 2015-04-30
2015-04-30 2786
27861) Создать в Блокноте таблицы следующего содержания (табл. 3.7, 3.8)
Таблица 3.7. Отгрузка товаров (файл otgruzka.txt)
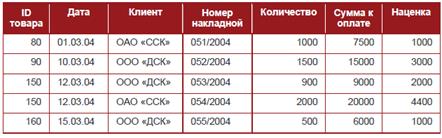
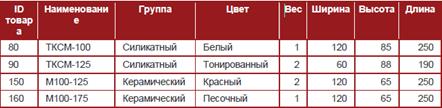
Таблица 3.8. Товары (файл tovar.txt)
Графически эти данные можно представить в многомерном пространстве следующим образом (рис. 3.34).
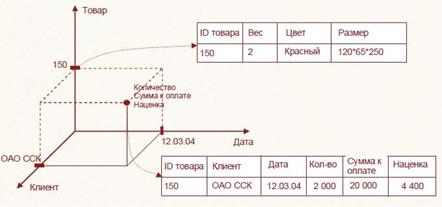
Рисунок 3.34 – Графическое представление исходных данных для создания ХД
2) Импортировать эти данные в программу (рис. 3.35).
Рисунок 3.35 – Импорт данных
3) Создать ХД primer.gdb.
Но сначала нужно определиться, что является процессом, фактами и измерениями (рис. 3.36).
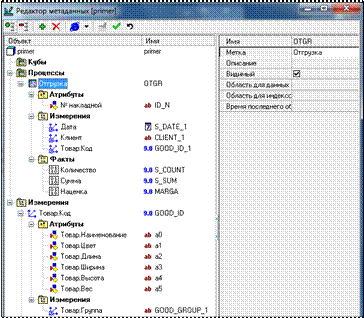
Рисунок 3.36 – Редактирование данных
Измерения – это Товар.Код, Товар.Группа, Дата и Клиент,.
Измерение Товар.Код содержит атрибуты Наименование, Цвет, Ширина, Высота, Длина, Вес.
В каждую товарную группу входит определенное число товаров. у измерения Товар.Код добавим ссылку на измерение Товар.Группа.
Процесс – это Отгрузка товаров. Он представлен таблицей 3.1.
Измерения – это Дата, Клиент, Товар.Код.
Комбинация этих трех измерений уникально идентифицирует точку в многомерном пространстве, т.е. предполагается, что в день один товар отгружается клиенту только один раз.
Факты – это Количество, Сумма к оплате и Наценка.
Атрибуты – Номер накладной – это справочное значение к каждой записи в таблице процесса, и нет смысла его помещать в измерение.
4) Экспортировать данные из текстовых файлов в ХД.
A) Нам необходимо загрузить 4 измерения. Причем загрузка измерений должна начинаться от верхних уровней иерархии к нижним, то есть в нашем примере сначала нужно загрузить измерение Товар. Группа, и только потом – Товар.Код.
Такая последовательность работы требуется потому, что при загрузке изменения Товар.Код необходимо сразу указать Группу, к которой он относится, и эта Группа уже должна присутствовать в хранилище.
Для загрузки нужен список уникальных (неповторяющихся) значений групп. Его можно получить при помощи обработчика Группировка, указав в качестве измерения то поле, по которому мы хотим получить список уникальных значений (в данном случае – Группа) (рис. 3.37).
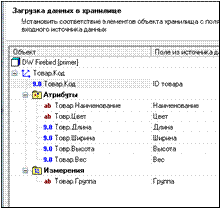
Рисунок 3.37 – Выставление соответствий
В сценариях становимся на Иванов.Текстовый файл tovar.txt. Мастер обработки ► Группировка. Все отметить как Неиспользуемое, кроме измерения Группа.
В сценариях становимся на Иванов.Текстовый файл tovar.txt. Мастер экспорта ► для базы primer, для измерения Товар.Группа.
Теперь мы можем загрузить измерение Товар.Код, имеющего дополнительные атрибуты.
В сценариях становимся на Иванов.Текстовый файл tovar.txt. Мастер экспорта ► для базы primer, для измерения Товар.Код.
Измерения без атрибутов Дата, Клиент можно не загружать отдельными узлами сценария, а сделать это во время загрузки в процесс.
Б) Последнее, что осталось сделать – загрузить данные в процесс (рис. 3.38).
Определить удаление данных из хранилища по измерению Дата.
Использовать опцию Способ удаления – в списке.
Определить варианты агрегации для фактов Количество, Сумма, Наценка как Сумма.
Таким образом, мы создали структуру хранилища и загрузили данные об отгрузках товара. Окончательный сценарий описанных действий, состоящий из 6 узлов, приведен на рисунке (рис. 3.39).
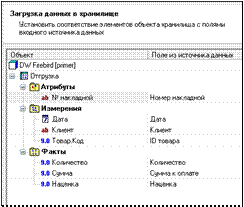
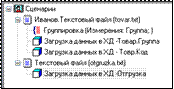
| Рисунок 3.38 – Загрузка данных в ХД | Рисунок 3.39 – Созданная структура хранилища |
5) Импортировать данные из ХД.
Импорт процесса.
Необходимо импортировать из ХД данные о количестве отгруженного товара в разрезе дат и товаров по клиенту ОАО «ССК», оставив атрибут товара Цвет.
В Мастере импорта отметить необходимые поля флажками (рис. 3.40).
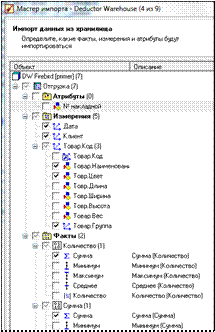
Рисунок 3.40 – Выделение необходимых полей флажками
Задать статический фильтр по клиенту ОАО «ССК».
В результате будет получен набор данных следующего содержания (рис. 3.41).
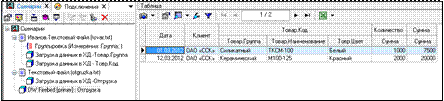
Рисунок 3.41 – Результат после статической фильтрации
Импорт измерения
Необходимо импортировать из ХД
А) данные о товарах, которые продает компания (табл. 3.9);
Таблица 3.9. Товары, продаваемые компанией

Б) информацию о том, в какую группу входит тот или иной товар (табл. 3.10).
Таблица 3.10. Информация о группе товаров

6) Настроить куб, в котором будет храниться информация об отгрузках по клиентам за последнюю неделю (рис. 3.42).
Откроем Редактор метаданных, войдем в режим редактирования и добавим Куб. Шаги по его созданию аналогичны шагам импорта из процесса. Выберем измерения Клиент и Дата, все доступные факты и по измерению Дата настроим статический фильтр с условием последний и значением неделя от имеющихся данных.
Дадим кубу название Куб.Отгрузка за неделю. В редакторе для него стал доступен специфичная опция в виде флажка Динамическое обновление. Активный флажок говорит о том, что при попадании новых данных в процесс Куб будет автоматически пересчитываться, при этом в поле Время последнего обновления будет заноситься дата и время последнего обновления.
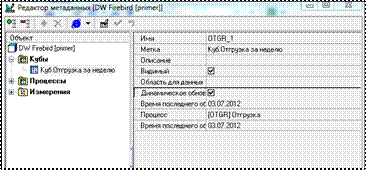
Рисунок 3.42 – Настройка Куба согласно условию
В результате в Мастере импорта, после выбора куба получим следующую таблицу (рис. 3.43).
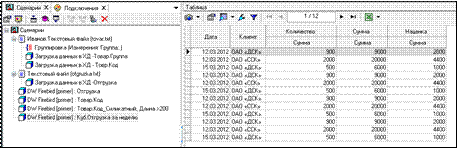
Рисунок 3.43 – Результат работы Мастера импорта
Результат сохраните в файле L3_2.ded.
Вопросы для проверки
1. Какая схема реляционного ХД используется в Deductor Warehouse?
2. Перечислите объекты хранилища Deductor Warehouse и дайте их определения.
3. Чем отличается атрибут процесса от измерения?
4. Как должна выглядеть структура таблицы-справочника, если имеются иерархии?
5. Что нужно сделать, если в приведенном примере выбранный уровень детализации продаж по дням не устраивает – необходимо сохранить максимальную детализацию исходных данных?
6. Что такое Редактор метаданных в Deductor Studio?
7. Как создать новое пустое хранилище данных?
8. Как сделать иерархию измерений?
9. Какие типы данных могут быть у объектов хранилища Deductor Warehouse 6?
10. Какова последовательность загрузки информации в хранилище?
11. В каких случаях измерение можно не загружать отдельным узлом экспорта?
12. Какие предусмотрены способы контроля непротиворечивости данных в Deduct or Warehouse?
13. Какие срезы для измерений типа дата/время предусмотрены в
Deductor Warehouse 6?
14. Что такое пользовательский фильтр?
15. Кому динамический срез, вероятнее всего, чаще будут требоваться –
аналитику Deductor Studio или пользователю Deductor Viewer?
16. Что такое куб в Deductor Warehouse 6?
17. Как создать куб?
18. Как настроить автоматическое обновление куба при попадании в хранилище новых данных?
19. Как проверить, актуален ли куб?
20. Как очистить значения процесса?
21. Как очистить значения измерения?
22. Как сделать полную очистку хранилища данных?
23. Как удалить измерение полностью из хранилища данных? Только из определенного процесса хранилища данных?
24. Как добавить измерение в процесс? Какие сложности при этом возникают?
25. Как добавить факт в процесс?

