 2015-04-20
2015-04-20 993
993Обмен данными в Web-технологии подразделяется в соответствии с типами методов доступа протокола HTTP и видами запросов в спецификации CGI.
Основных методов доступа два: GET и POST. Помимо них часто используются HEAD и PUT.
Виды запросов CGI разделяют на два основных MIME-типа: application/x-www-form-urlencoded и multipart/form-data. Второй тип запроса специально создан для передачи больших внешних файлов.
Эту классификацию можно представить в виде таблицы:
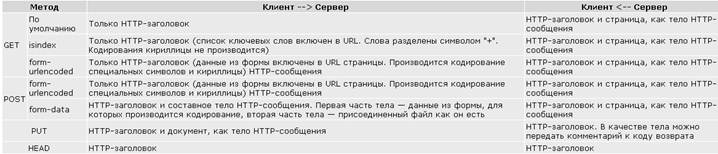
При реализации нестандартных методов доступа, например, DELETE, могут быть несколько иные комбинации содержания откликов и ответов.
Мы рассмотрим все эти типы обменов.
Спецификация Common Gateway Interface
Данная спецификация определяет стандартный способ обмена данными между прикладной программой и HTTP-сервером. Спецификация была предложена для сервера NCSA и является основным средством расширения возможностей обработки запросов клиентов HTTP-сервером.
В CGI имеет смысл выделить следующие основные моменты:
понятие CGI-скрипта;
типы запросов;
механизмы приема данных скриптом;
механизм генерации отклика скриптом.
Основное назначение CGI — обработка данных из HTML-форм. В настоящее время область применения CGI гораздо шире.
Понятие CGI-скрипта
CGI-скриптом называют программу, написанную на любом языке программирования или командном языке, которая осуществляет обмен данными с HTTP-сервером в соответствии со спецификацией Common Gateway Interface.
Наиболее популярными языками для разработки скриптов являются Perl и С.
Типы запросов
Различают два типа запросов к CGI-скриптам: по методу GET и по методу POST. В свою очередь, запросы по методу GET подразделяются на запросы по типам кодирования: isindex и form-urlencoded, а запросы по методу POST — multipart/form-data и form-urlencoded.
В запросах по методу GET данные от клиента передаются скрипту в переменной окружения QUERY_STRING. В запросах по методу POST данные от скрипта передаются в потоке стандартного ввода скрипта. При передаче через поток стандартного ввода в переменной окружения CONTENT_LENGHT указывается число передаваемых символов.
Запрос типа ISINDEX — это запрос вида:
https://pub.niiar.ru/somthig-cgi/
cgi-script?слово1+слово2+слово3
Главным здесь является список слов после символа "?". Слова перечисляются через символ "+" и для кириллицы в шестнадцатеричные последовательности не кодируются. Последовательность слов после символа "?" будет размещена в переменной окружения QUERY_STRING.
Запрос типа form-urlencoded — это запрос вида:
https://pub.niiar.ru/somthig-cgi/
cgi-script?field=word1&field2=word2
Данные формы записываются в виде пар "имя_поля-значение", которые разделены символом "&".
Приведенный пример — это обращение к скрипту по методу GET. Все символы после "?" попадут в переменную окружения QUERY_STRING. При этом если в значениях полей появляется кириллица или специальные символы, то они заменяются шестнадцатеричным кодом символа, который следует за символом "%".
При обращении к скрипту по методу POST данные после символа "?" не будут размещаться в QUERY_STRING, а будут направлены в поток стандартного ввода скрипта. В этом случае количество символов в потоке стандартного ввода скрипта будет указано в переменной окружения CONTENT_LENGTH.
При запросе типа multipart/form-data применяется составное тело HTTP-сообщения, которое представляет собой данные, введенные в форме, и данные присоединенного внешнего файла. Это тело помещается в поток стандартного ввода скрипта. При этом к данным формы применяется кодирование как в form-urlencoded, а данные внешнего файла передаются как есть.
Механизмы приема данных скриптом
Скрипт может принять данные от сервера тремя способами:
через переменные окружения;
через аргументы командной строки;
через поток стандартного ввода.
При описании этих механизмов будем считать, что речь идет об обмене данными с сервером Apache для платформы Unix.
Переменные окружения
При вызове скрипта сервер выполняет системные вызовы fork и exec. При этом он создает среду выполнения скрипта, определяя ее переменные. В спецификации CGI определены 22 переменные окружения. При обращении к скрипту разными методами и из различных контекстов реальные значения принимают разные совокупности этих переменных. Например, при обращении по методу POST переменная QUERY_STRING не имеет значения, а по методу GET — имеет. Другой пример — переменная окружения HTTP_REFERER. При переходе по гипертекстовой ссылке она определена, а если перейти по значению поля location или через JavaScript-программу, то HTTP_REFERER определена не будет.
Получить доступ к переменным окружения можно в зависимости от языка программирования следующим образом:
#Perl
$a = $ENV{CONTENT_LENGTH};
...
// C
a = getenv("CONTENT_LENGTH");
В случае доступа к скрипту по методу GET данные, которые передаются скрипту, размещаются в переменной окружения QUERY_STRING.
Аргументы командной строки
Как ни странно звучит, но у CGI-скрипта может быть такой элемент операционного окружения как командная строка. Это не означает, что скрипт реально можно вызвать из командной строки через сервер. Тем не менее получить доступ к содержанию командной строки скрипта можно с помощью тех же функций, что и при вызове его из-под интерактивной оболочки:
#Perl
foreach $a (@ARGV)
{
print $a,"\n";
}
// C
void main(argc,argv)
int argc;
char *argv[];
{
int i;
for(i=0;i<argc;i++)
{
printf("%s\n",argv[i]);
}
}
В обоих примерах показана распечатка аргументов командной строки для программ на Perl и C соответственно.
Аргументы командной строки появляются только в запросах типа ISINDEX.
Поток стандартного ввода
Ввод данных в скрипт через поток стандартного ввода осуществляется только при использовании метода доступа к ресурсу (скрипту) POST. При этом в переменную окружения CONTENT_LENGTH помещается число символов, которое необходимо считать из потока стандартного ввода скрипта, а в переменную окружения CONTENT_TYPE помещается тип кодирования данных, которые считываются из потока стандартного ввода.
При посимвольном считывании в C можно применить, например, такой фрагмент кода:
int n;
char *buf;
n= atoi(getenv("CONTENT_LENGTH"));
buf = (char *) malloc(n+1);
memset(buf,'\000',n+1);
for(i=0;i<n;i++)
{
buf[i]=getchar()
}
free(buf);
В данном фрагменте применено динамическое размещение памяти в скрипте, поэтому при выходе из него память следует освободить. Вообще говоря, память будет автоматически освобождена операционной системой после завершения скрипта. Однако, если переносить скрипт на спецификацию FCGI (Fast CGI), что требует минимума переделок, из-за неаккуратной работы с памятью могут возникнуть проблемы.
28. Технология CGI. Протокол HTTP (общая структура сообщений, методы доступа и оптимизация обменов).
Все данные в рамках Web-технологии передаются по протоколу HTTР. Исключение составляет обмен с использованием программирования на Java или обмен из Plugin-приложений. Учитывая реальный объем трафика, который передается в рамках Web-обмена по HTTP, мы будем рассматривать только этот протокол. При этом мы остановимся на таких вопросах, как:
общая структура сообщений;
методы доступа;
оптимизация обменов.
Общая структура сообщений
HTTP — это протокол прикладного уровня. Он ориентирован на модель обмена "клиент-сервер". Клиент и сервер обмениваются фрагментами данных, которые называются HTTP-сообщениями. Сообщения, отправляемые клиентом серверу, называют запросами, а сообщения, отправляемые сервером клиенту — откликами. Сообщение может состоять из двух частей: заголовка и тела. Тело от заголовка отделяется пустой строкой.
Заголовок содержит служебную информацию, необходимую для обработки тела сообщения или управления обменом. Заголовок состоит из директив заголовка, которые обычно записываются каждая на новой строке.
Тело сообщения не является обязательным, в отличие от заголовка сообщения. Оно может содержать текст, графику, аудио- или видеоинформацию.
Ниже приведен HTTP-запрос:
GET / HTTP/1.0
Accept: image/jpeg
пустая строка
И отклик:
HTTP/1.0 200 OK
Date: Fri, 24 Jul 1998 21:30:51 GMT
Server: Apache/1.2.5
Content-type: text/html
Content-length: 21345
пустая строка
<HTML>
...
</HTML>
Текст "пустая строка" — это просто обозначение наличия пустой строки, которая отделяет заголовок HTTP-сообщения от его тела.
Сервер, принимая запрос от клиента, часть информации заголовка HTTP-запроса преобразует в переменные окружения, которые доступны для анализа CGI-скриптом. Если запрос имеет тело, то оно становится доступным скрипту через поток стандартного ввода.
Методы доступа
Самой главной директивой HTTP-запроса является метод доступа. Он указывается первым словом в первой строке запроса. В нашем примере это GET. Различают четыре основных метода доступа:
GET;
HEAD;
POST;
PUT.
Кроме этих четырех методов существует еще около пяти дополнительных методов доступа, но они используются редко.
Метод GET
Метод GET применяется клиентом при запросе к серверу по умолчанию. В этом случае клиент сообщает адрес ресурса (URL), который он хочет получить, версию протокола HTTP, поддерживаемые им MIME-типы документов, версию и название клиентского программного обеспечения. Все эти параметры указываются в заголовке HTTP-запроса. Тело в запросе не передается.
В ответ сервер сообщает версию HTTP-протокола, код возврата, тип содержания тела сообщения, размер тела сообщения и ряд других необязательных директив HTTP-заголовка. Сам ресурс, обычно HTML-страница, передается в теле отклика.
Метод HEAD
Метод HEAD используется для уменьшения обменов при работе по протоколу HTTP. Он аналогичен методу GET за исключением того, что в отклике тело сообщения не передается. Данный метод используется для проверки времени последней модификации ресурса и срока годности кэшированных ресурсов, а также при использовании программ сканирования ресурсов World Wide Web. Одним словом, метод HEAD предназначен для уменьшения объема передаваемой по сети информации в рамках HTTP-обмена.
Метод POST
Метод POST — это альтернатива методу GET. При обмене данными по методу POST в запросе клиента присутствует тело HTTP-сообщения. Это тело может формироваться из данных, которые вводятся в HTML-форме, или из присоединенного внешнего файла. В отклике, как правило, присутствует и заголовок, и тело HTTP-сообщения. Чтобы инициировать обмен по методу POST, в атрибуте METHOD контейнера FORM следует указать значение "post".
Метод PUT
Метод PUT используется для публикации HTML-страниц в каталоге HTTP-сервера. При передаче данных от клиента к серверу в сообщении присутствует и заголовок сообщения, в котором указан URL данного ресурса, и тело — содержание размещаемого ресурса.
В отклике тело ресурса обычно не передается, а в заголовке сообщения указывается код возврата, который определяет успешное или неуспешное размещение ресурса.
Оптимизация обменов
Протокол HTTP изначально не был ориентирован на постоянное соединение. Это означает, что как только сервер принял запрос от клиента и ответил на него, соединение между клиентом и сервером разрывается. Для нового обмена данными нужно устанавливать новое соединение. Такой подход имеет как достоинства, так и недостатки.
К достоинствам относится возможность одновременного обслуживания большого количества коротких запросов. Даже на популярных серверах число открытых соединений может не превышать сотни при обслуживании порядка миллиона запросов в сутки. При этом один клиент может открыть до 40 соединений одновременно, и с точки зрения сервера все они равноправны. При высокоскоростных линиях связи это позволяет добиться малого времени отклика на запрос клиента для всей страницы (текст, графика и т.п.).
К недостаткам такой схемы обмена относятся: необходимость каждый раз устанавливать соединение и невозможность поддерживать сессию работы с информационным ресурсом. При инициализации соединения по транспортному протоколу TCP и разрыве этого соединения требуется передать довольно большой объем служебной информации. Отсутствие поддержки сессий в HTTP затрудняет работу с такими ресурсами как базы данных или ресурсы, требующие аутентификации.
Для оптимизации числа открытых TCP-соединений в HTTP-протоколе версий 1.0 и 1.1 предусмотрен режим keep-alive. В этом режиме соединение инициализируется только один раз, и по нему последовательно можно реализовать несколько HTTP-обменов.
Для обеспечения поддержки сессий к директивам HTTP-заголовка были добавлены "ключики" (cookies). Они позволяют сымитировать поддержку соединения при работе по протоколу HTTP.
29. Программирование CGI на языке С.
Директивы препроцессора позволяют собрать программу на языке С из готовых блоков кода. Кроме того, можно реализовать управление процессом компиляции, например, разработать процедуру условной компиляции для разных операционных систем.
В рамках разработки простых CGI-скриптов нам нужна будет только инструкция включения "include". Во всех примерах данного раздела она используется для включения в код программы описаний функций из набора стандартных библиотек.
Если необходимо задействовать функции форматного ввода/вывода, а их мы применяем для печати в стандартный вывод, то следует использовать инструкцию #include <stdio.h>:
#include <stdio.h>
void main()
{
printf("Content-type: text/html\n\n");
printf("<HTML>");
printf("<HEAD>");
printf("</HEAD>");
printf("<BODY>");
printf("<H1>Привет от-CGI</H1>");
printf("</BODY>");
printf("</HTML>");
}
Инструкция препроцессора начинается с символа "#". При использовании инструкций включения различают локальные файлы и стандартные файлы включения. Когда применяются стандартные файлы включения, имя файла заключают в "<имя_файла>". При использовании локального файла имя файла заключают в обычные двойные кавычки — "имя_файла". В наших примерах применяются только стандартные файлы включений.
Мы используем файлы включения только для ввода в код программы описаний стандартных функций и констант, с этими функциями связанных. Для наиболее распространенных функций существует файл /usr/include/stdlib.h. Его включения в программу достаточно для того, например, чтобы использовать функции ввода/вывода и сравнения строк:
#include <stdlib.h>
void main()
{
printf("Content-type: text/plain\n\n");
if(strcmp("GET",getenv("REQUEST_METHOD"))
{
printf("Нет даты в потоке STDIN");
}
}
В данном случае в stdlib.h определены шаблоны для функций strcmp() и getenv().
При программировании в среде Unix программист всегда может применить команду man, которая позволяет получить подсказку по использованию той или иной функции C.
Компиляция
Программа на С — это текстовый файл, из которого программа-компилятор создает исполняемый файл. CGI-скрипт — это исполняемый файл. Для компиляции используется компилятор с языка С. В большинстве Unix-платформ этот компилятор носит название cc.
Предположим, что нужно создать программу с именем hello.cgi. Код на С расположен в файле hello.c. В этом случае достаточно выполнить:
bash%cc -o hello.cgi hello.c
Опция "-о" в этой записи определяет имя исполняемого файла. Он задается сразу вслед за ней. Имя файла исходного текста С указывается просто в качестве параметра.
Если в скрипте использовать функции из внешней библиотеки, то компилятору необходимо указать ее адрес:
bash%cc -o test.cgi test.c -lpq
В данном случае мы используем внешнюю библиотеку pq. Опция -l определяет имя библиотеки. Сама процедура сборки программы называется linking (связывание). Отсюда и буква "l" перед именем библиотеки.
30. Технология CGI. Метод доступа GET.
Метод доступа GET долгое время был основным методом доступа из форм к CGI-скриптам. Это происходило по причине отсутствия при вводе большого количества данных и из-за прямого обращения к скриптам по их URL. В настоящее время ситуация меняется, но тем не менее данный метод занимает едва ли не главное место в программировании обработки данных из HTML-форм.
Условно использование GET можно разбить на два способа:
запросы типа isindex;
запросы типа from-urlencoded.
В первом случае имитируется или реально происходит передача запроса, который появляется при вводе данных в строке приглашения контейнера ISINDEX. Во втором случае происходит передача пар "имя_поля=значение". И в том, и в другом случае данные, не входящие в кодировку Latin1, преобразуются в пары шестнадцатеричных символов, предваряемых символом "%" (%20 — пробел).
Кроме вызова скрипта непосредственно из гипертекстовой ссылки, скрипт можно запустить и через Server Site Include. В этом случае данные из формы будут приписываться к URL документа, а не скрипта. Скрипт при этом будет вызываться сервером при разборе текста HTML-страницы перед отправкой ее клиенту.
Кроме собственно запроса, который в методе GET появляется в URL после символа "?", скрипту еще можно передать информацию в HTTP-пути. Это переменная окружения PATH_INFO. Обработка данных из этой переменной требует особого подхода к их получению и использованию в скрипте и гипертекстовых ссылках.
Запрос isindex
Запрос типа isindex является исторически первым способом передачи данных от браузера серверу. Он был разработан для передачи списка ключевых слов для поисковой машины. Запрос данного типа появляется либо в случае использования контейнера ISINDEX, либо при прямом обращении к скрипту через гипертекстовую ссылку. Данный тип запроса имеет ряд особенностей, которые отличают его от запроса типа form-urlencoded.
При использовании контейнера ISINDEX в начале документа появляется шаблон ввода ключевых слов. После ввода списка слов, разделенных пробелом, вызывается скрипт, который принимает список, разбирает его на отдельные слова и выполняет необходимую обработку. Первоначально isindex был ориентирован на модуль, подключавший поисковую систему WAIS к серверу CERN. После появления спецификации CGI стало возможным передавать списки слов любому CGI-скрипту. Запрос типа isindex определен только для метода доступа GET.
Согласно спецификации CGI для метода GET запрос присоединяется к URL документа или скрипта (указан атрибут ACTION в контейнере ISINDEX) после символа "?"(getis2.htm):
https://localhost/htdocs/isindex.htm?search+
engine+world+wide+web
или
https://localhost/htdocs/isindex.cgi?search+
engine+world+wide+web
Как видно из этого примера, в запросе пробел заменяется на символ "+". Причем буквы русского алфавита в таком запросе перекодировать не надо, они передаются как есть. Если пользователь работает с локализованной версией операционной среды, то все будет отображаться так, как положено. В случае нелокализованной версии операционной среды, например, Windows NT, буквы будут отображаться абракадаброй, но в скрипт будут передаваться правильные коды.
Традиционно в GET данные запроса выбираются из переменной окружения QUERY_STRING. Например, это можно сделать на Perl следующим образом:
#!/usr/local/bin/perl
print "Content-type: text/playn\n\n";
print "Запрос: $ENV{QUERY_STRING}.\n";
В данном примере первый оператор печати формирует заголовок HTTP-сообщения в соответствии со спецификацией CGI. Второй оператор печати распечатывает содержание переменной окружения QUERY_STRING. Главное при этом — разделить запрос на отдельные слова, чтобы можно было использовать их в качестве ключей поиска. В Perl для этого существует функция split:
#!/usr/local/bin/perl
print "Content-type: text/playn\n\n";
print "Запрос: $ENV{QUERY_STRING}.\n";
@words = split('+',$ENV{QUERY_STRING});
foreach $word (@words)
{
print $word,"\n";
}
В данном случае следует обратить внимание на то, что в запросе нет никаких имен полей — только введенные слова и их разделители. Естественно, если среди введенных символов встретится разделитель, он будет заменен шестнадцатеричным.
У запроса isindex есть еще одно замечательное свойство — это передача данных в командной строке CGI-скрипта. Очевидно, что ввести аргументы пользователь не в состоянии (у него нет удаленного терминала), но вот принять данные из командной строки скрипт может:
#!/usr/local/bin/perl
print "Content-type: text/playn\n\n";
print "Запрос: $ENV{QUERY_STRING}.\n";
$n = @ARGV;
for ($i=0;$i
{
print $ARGV[$i],"\n";
}
Внешне результаты работы данного скрипта и скрипта разбора QUERY_STRING ничем не отличаются. Но данные они получают из разных источников (getis6.htm).
Запрос типа isindex не порождается событием onSubmit, как это происходит в запросах form-urlencoded. Он является одной из разновидностей схемы http универсального локатора ресурсов (URL). При использовании обычной контекстной гипертекстовой ссылки (контейнер A (anchor)) запрос просто дописывается вслед за символом "?".
При программировании на JavaScript обратиться к скрипту через запрос isindex можно либо путем изменения значения атрибута HREF в одном из элементов массива гипертекстовых ссылок документа, либо путем вызова метода replace() объекта Location.
Запрос from-urlencoded
В методе GET запрос типа form-urlencoded является основной формой запроса. От запроса типа isindex он отличается форматом и способом передачи, точнее, кодировкой данных в теле HTTP-сообщения. Данные формы попадают в запрос, который расширяет URL скрипта в виде пар "имя_поля=значение&имя_поля=значение&...". Например, для формы вида:
<FORM ACTION=test.cgi METHOD=get>
Поле1:<INPUT NAME=f1 VALUE=value1>
Поле2:<INPUT NAME=f1 VALUE=value1>
<INPUT TYPE=submit VALUE="Послать">
</FORM>
запрос в сообщении HTTP-протокола будет выглядеть следующим образом:
GET /test.cgi?f1=value1&f2=value2 HTTP/1.0
Несмотря на то, что в форме имеется три поля, переданы будут значения только двух полей. Это связано с тем, что у третьего поля в форме нет имени. Если у поля нет имени, то его значение не передается серверу. Это правило общее для всех полей. Чаще всего оно применяется для полей подтипов submit и reset типа text.
Применение неименованных полей позволяет передавать в скрипт только ту информацию, которая реально требуется для выполнения обработки данных. Иногда неименованные поля применяют и при программировании на JavaScript.
Кроме формата в запросе типа form-urlencoded, данные, введенные в форму, подвергаются дополнительной обработке — кодированию.
Кодирование, собственно, и дало название методу (urlencoded). Согласно спецификации, текстовое сообщение не может содержать символы, не входящие в набор Latin1. Это означает, что вторая половина таблицы ASCII и первые 20 символов должны быть закодированы. В CGI символ кодируется как две шестнадцатеричные цифры, следующие за знаком "%". Для российских Web-узлов это означает, что скрипт, который принимает запрос, должен предварительно перекодировать все шестнадцатеричные эквиваленты в символы (getform2.htm). На Perl это можно реализовать в одну строку:
query =~ s/%(.{2})/pack('c',hex($1))/ge;
В данном случае мы осуществляем глобальную подстановку (оператор "=~ s///"), который употреблен с модификаторами "ge". Первый модификатор обозначает глобальную замену по всей строке query, а второй требует выполнения перед заменой выражения "pack('c',hex($1))". Более подробно о программировании на Perl см. раздел "Введение в программирование на Perl".
Передача параметров через PATH_INFO
Передача данных в скрипты возможна не только при помощи переменной окружения QUERY_STRING или аргументов командной строки скрипта. Передать параметры в скрипт можно через переменную окружения PATH_INFO. Данная переменная принимает свое значение после преобразования URL скрипта. Рассмотрим следующий URL:
https://localhost/cgi-bin/test/arg1/arg2/
arg3?param1+param2
Согласно спецификации URI адрес ресурса делится на две части: название схемы адресации и путь к ресурсу:
схема разделитель путь к ресурсу
http: //localhost/cgi-bin/test/arg1/arg2/arg3?param1+param2
схема адресации задается протоколом обмена данными. Обращение к скрипту осуществляется по схеме http. В свою очередь, в схеме http путь снова делится на две части: адрес ресурса и параметры. Эти части разделены символом "?". Параметры могут быть записаны либо в форме isindex, либо в формате form-urlencoded:
адрес ресурса разделитель параметры
//localhost/cgi-bin/test/arg1/arg2/arg3? param1+param2
Адрес ресурса в случае обращения к скрипту снова можно разделить на две части — адрес скрипта и путевой параметр PATH_INFO:
адрес скрипта PATH_INFO
//localhost/cgi-bin/test /arg1/arg2/arg3
В данном случае явного разделителя между адресом скрипта и PATH_INFO нет. Деление определяется настройками сервера. У большинства серверов стандартным каталогом CGI-скриптов является каталог cgi-bin. При этом подразумевается, что все файлы этого каталога — скрипты. Можно даже указать файл с расширением html, который в данном случае будет интерпретироваться как скрипт (getpath1.htm). Значение путевого параметра сервер помещает в переменную окружения PATH_INFO. При этом в нее попадает и лидирующий символ "/".
Управление работой скрипта через путевой параметр довольно популярно. Например, при выполнении перенаправления, когда нужно собирать статистику обращений к ресурсам, расположенным вне Web-узла:
https://localhost/cgi-bin/banner/
https://otherhost/page.html
Вообще говоря, при таких перенаправлениях возникает опасность Web-спуффинга. Существует очень большая вероятность, что администратор не заметит подмены одной из частей такого URL.
PATH_INFO применяется не только в совокупности с каталогами скриптов, но и с любым скриптом, определенным пользователем. Часто в качестве такого скрипта определяются файлы с расширением *.cgi:
https://www.pub.niiar.ru/~user/script.cgi/
path_param/test?arg1+arg2
В этом примере в переменную PATH_INFO попадет /path+param/test.
31. Технология CGI. Метод доступа PUT и другие методы.
Метод POST — это второй основной метод доступа к информационным ресурсам Web-узла. Он является альтернативой методу GET. Вообще, при HTTP-обмене используются три основных метода: GET, POST и HEAD. Первые два предназначены для получения страниц. Страницы при этом передаются в виде тела HTTP-отклика. При методе GET от клиента к серверу отправляется запрос, состоящий только из заголовка HTTP-сообщения. Все введенные пользователем данные размещаются в URL документа. При методе POST от клиента к серверу уходит запрос, который состоит из заголовка и тела HTTP-сообщения. При этом данные, введенные пользователем, размещаются в теле запроса. Метод HEAD применяется только для управления обменом и отображением. В рамках данного метода тело HTTP-сообщения не пер едается как клиентом в запросе, так и сервером в отклике.
Основное назначение метода POST — передача сравнительно больших объемов данных от клиента к серверу. Применение этого метода оправдано при передаче сложных состоящих из множества полей форм. В спецификации CGI от NCSA рекомендуется использовать метод POST при передаче данных из форм, содержащих поля textarea.
Современное использование Web в качестве альтернативы FTP-архивам расширило свойства метода POST. Так, большинство архивов научной периодики построено по принципу их обновления авторами статей. Для этой цели используются страницы с формами, содержащими поля типа File-upload. Этот механизм позволяет передать на сервер файл любого размера и любого типа. При этом сами пользователи не получают Web-account на сервере архива, они пользуются стандартным скриптом публикации.
Из перечисленных выше методов только POST формирует тело сообщения. В спецификации CGI речь при этом идет только об HTTP-сообщениях. Но современные браузеры — это мультипротокольные программы. При этом в качестве гипертекстовых ссылок можно использовать различные схемы. Во многих протоколах, на которые эти схемы указывают, нет понятия метода доступа. Тем не менее в контейнере FORM такой метод можно использовать, например, со схемой mailto. В данном случае ни по какому методу POST, который не определен в протоколе SMTP, ничего не передается. POST просто заставляет браузер создать тело, в данном случае, почтового сообщения.
Чтение данных из стандартного потока ввода
При передаче запроса по методу POST от клиента к серверу передается HTTP-сообщение, которое состоит из заголовка и тела. Данные, введенные в HTML-форму, как раз и составляют тело сообщения. При обработке такого запроса CGI-скриптом данные следует выбирать из стандартного потока ввода скрипта, а не из переменной окружения QUERY_STRING. Эта переменная будет иметь пустое значение.
Для того, чтобы принять данные, нужно прочитать стандартный поток ввода. При этом из стандартного потока ввода нужно считать строго определенное количество байтов. Число байтов определяется переменной окружения CONTENT_LENGTH. В Perl прием данных в скрипт можно организовать следующим образом:
#!/usr/local/bin/perl
read STDIN,$query,$ENV(CONTENT_LENGTH);
Здесь из стандартного потока ввода STDIN считывается $ENV(CONTENT_LENGTH) данных и помещается в переменную $query. После этого можно уже что-то делать с запросом, например, распечатать его в виде HTML-таблицы.
Аналогично можно принять запрос из стандартного ввода и в С. Для этого следует воспользоваться в простейшем случае функцией getchar():
#include <stdlib.h>
#include <malloc.h>
void main()
{
int n,i;
char *buff;
n = atoi(getenv("CONTENT_LENGTH");
buff = (char *) malloc(n+1);
memset(buff,'\000',n+1);
for(i=0;i<n;i++)
{
buff[i] = getchar();
}
printf("Content-type: text/plain\n\n");
printf("Length of data into STDIN:%d\n",n);
printf("STDIN data: %s\n",buff);
free(buff);
}
Посимвольное чтение в этом примере можно заменить чтением по функции fread(). При этом не следует ожидать существенного уменьшения времени чтения данных. Во-первых, данные при вводе буферизуются. Во-вторых, в С применяется потоковая модель работы с внешними наборами данных.
Передача присоединенных файлов
Метод POST позволяет реализовать передачу файлов с компьютера пользователя в архив на HTTP-сервере. Для этой цели разработана специальная форма кодирования тела документа: multipart/form-data. Она указывается в контейнере FORM в атрибуте ENCTYPE совместно с методом POST:
<FORM ENCTYPE=multipart/form-data
METHOD=post>
Скрипт, который принимает такие данные, должен определить метод доступа, затем определить тип тела документа и только после этого начать разбирать тело. В теле может быть как минимум две части: значения различных полей, которые доставляются скрипту в первой части сообщения, и тело передаваемого файла, которое передается как вторая часть сообщения.
Поля разбираются по традиционной схеме. Это обычные ASCII-символы. С ними никаких проблем не возникает. Тело документа передается как есть, т.е. без преобразований. Это значит, что применять для его выделения текстовые функции С нельзя, т.к. внутри документа могут попадаться любые символы, в том числе и символы конца символьного массива (строки).
Чтобы убедиться в этом, достаточно просто распечатать данные, посланные браузером. Для приема данных и их разбора нужно либо написать собственную программу, либо воспользоваться готовыми программами и библиотеками языка Perl, например.
Очевидно, что метод POST с полями file-upload используется для опубликования данных на стороне сервера. При этом файл, который передается по сети, должен быть размещен в файловой системе либо сервера, либо другого удаленного компьютера. Для этого пользователь, от имени которого запускается скрипт, должен иметь соответствующие права на доступ к каталогу файловой системы компьютера, в который записывается файл. Довольно часто модули стандартных библиотек, например, CGI_Lite или CGI.pm, используют для временного хранения каталог /tmp. Иногда данный каталог закрывают на запись, из-за чего могут возникнуть проблемы с приемом данных скриптом, составленным из модулей стандартной библиотеки.
Стандартные библиотеки разбора данных
Разбор запроса по методу POST CGI-скриптом — это рутинная процедура. При запросе типа url-encoded нужно просто выделить имена полей и их значения, а при запросе типа multipart/form-data — выделить части составного тела запроса и преобразовать их в имена полей, их значения и файлы.
С 1995 года было написано достаточно много заготовок для такого разбора, которые оформлены в виде свободно распространяемых библиотек. Наиболее популярными являются библиотеки модулей Perl — CGI.pm и CGI_Lite.
CGI.pm — полный набор функций для генерации HTML-файлов с формами и разбора запросов CGI-скриптами.
CGI_Lite — это средство работы с составными (multipart/form-data) запросами. При работе с функциями данного модуля следует иметь в виду, что временные файлы эти функции размещают в каталоге /tmp.
Метод доступа PUT и другие способы использования CGI-скриптов
Кроме стандартных способов использования CGI-скриптов, т.е. приема запросов от браузеров по методам GET и POST, скрипты применяются и для решения ряда других задач. К таким задачам можно отнести обслуживание расширенного набора методов доступа, например, PUT и DELETE.
Кроме того, для исполнения скриптов сам HTTP-сервер должен быть настроен соответствующим образом. В конфигурации по умолчанию сервера Apache предполагается, что все стандартные скрипты будут размещаться в каталоге ~server_root/cgi-bin, а скрипты пользователя будут иметь расширение *.cgi.
Если эксплуатируется только один Web-узел, этих настроек вполне достаточно. Если же на одной вычислительной установке эксплуатируется несколько виртуальных Web-узлов, то для каждого из них следует дополнительно определять и каталоги стандартного размещения, и расширения по умолчанию, и методы обработки нестандартных методов доступа.
Нередко CGI-скрипты применяются в качестве подстановок SSI на стороне сервера. Схема проста: HTML-документ используется как шаблон, в котором HTML-комментарии задают команды подстановок. В зависимости от различных условий сервер, который обрабатывает эти документы перед отправкой клиенту (браузеру), вставляет в шаблон результаты выполнения команд подстановок, в частности CGI-скриптов.
Преимущество CGI-скриптов в данном случае заключается в том, что они работают с переменными окружения, порожденными сервером для скрипта, а не с системными переменными окружения. Это позволяет включить механизмы анализа IP-адреса клиента, его доменного имени или cookie, чего нельзя сделать при работе с обычным набором переменных окружения, который порождается операционной системой.
32. Технология CGI. Контейнер INPUT и его компоненты.
Контейнер INPUT является самым распространенным контейнером HTML-формы. Существует целых 10 типов этого контейнера (text, image, submit, reset, hidden, password, file, checkbox, radio, button), причем каждый из них отображается по-разному.
В общем виде контейнер имеет вид:
<INPUT
NAME="Имя"
TYPE="Тип"
[вариации параметров, зависящие от типа]
>
Чаще всего контейнер INPUT применяется для организации текстового поля ввода: например, для ввода списка ключевых слов или для заполнения регистрационных форм.








