 2015-04-23
2015-04-23 1780
1780Выборочным называется такое наблюдение, при котором изучается некоторая часть единиц совокупности и получаемые в результате обобщающие показатели с достаточной точностью могут быть использованы для характеристики всей совокупности в целом.
На этапе сбора данных статистическая процедура (см. п. 2.1) предусматривает проведение либо сплошного наблюдения (переписи), либо выборочного обследования.
По сравнению со сплошным выборочное наблюдение обладает следующими преимуществами:
· детализация в изучении первичного материала. Поскольку в выборку попадает не так много единиц совокупности, их обследование можно провести по более широкой программе;
· меньшее число ошибок регистрации, как следствие меньшего объема наблюдения;
· большая маневренность по сравнению со сплошным наблюдением. Выборочное наблюдение может быть организовано неспециализированным подразделением.
К недостаткам выборочных наблюдений относится то, что выборочные показатели почти никогда не совпадают с соответствующими показателями всей совокупности.
При проведении и обработке результатов выборочного обследования применяется следующая терминология.
v Генеральная совокупность (Population) – вся совокупность единиц, из которых производится отбор.
v Выборочная совокупность (Sampling population)– та часть единиц, которая попала в выборку.
v Генеральное среднее (Mean)`X.
v Выборочное среднее (Sample Mean)`xв.
v Генеральная дисперсия (Variance) s2.
v Выборочная дисперсия (Sample Variance) s2в.
В число основных показателей выборки входят не только параметры центра распределения и рассеивания, но и значения ошибок выборки, оценивающие с определенным уровнем вероятности отклонения выборочных значений от соответствующих параметров генеральной совокупности. Вычисления выполняются по следующим формулам.
1)выборочное среднее для выборки объемом n, сгруппированной на K групп, рассчитывается по формуле среднего взвешенного:
K
S mi`xi
i=1
`xв = ¾¾¾¾, (2.23)
n
где`xi - среднее i-ой группы,
mi - частота i-ой группы,
K - количество групп.
2)Выборочная дисперсия:
K
S mi(`xi -`xв)2
i=1
s2в = ¾¾¾¾¾¾¾¾¾. (2.24)
n
3)Средняя ошибка выборки, оценивающая (в среднем) величину отклонения выборочного от генерального среднего (т.е. от математического ожидания – в терминах теории вероятностей):

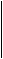
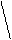 s2
s2
mx = ¾¾, (2.25)
 n
n
где s2 – генеральная дисперсия. При расчетах вместо неизвестной s2 в формуле (2.25) используется близкое к ней расчетное значение выборочной дисперсии s2в. Степень приближения определяется законом больших чисел, согласно которому при неограниченном увеличении объема выборки: n ® N, где N-общее число единиц генеральной совокупности, выборочная дисперсия стремится по вероятности к генеральной: s2в ® s2.
4)Предельная ошибка выборки, гарантируемая с вероятностью p:
 |
s2 n
Dв = t ¾¾ (1- ¾), (2.26)
n N
где t – коэффициент доверия, определяющий с вероятностью p пределы возможных значений генерального среднего:`X =`xв ± Dв.
Согласно теореме Чебышева-Ляпунова, являющейся одним из выражений закона больших чисел, значения коэффициента доверия определяются нормальным законом распределения среднего выборочного и его целые значения могут быть рассчитаны из функции Лапласа:
| t | ||||
| p | 0,683 | 0,954 | 0,997 | 0,999937 |
Задавшись заранее предельным значением ошибки выборки, коэффициент доверия t можно вычислить по статистическим данным (т.е. используя рассчитанное значение выборочной дисперсии s2в) на основе формулы (2.26):
Dв

 t = ¾¾¾¾¾¾¾¾¾¾,
t = ¾¾¾¾¾¾¾¾¾¾,
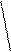 s2в n
s2в n
¾¾ (1- ¾)
n N
и затем определить вероятность заданного значения Dв из обратной формулы функции Лапласа [2].
5)Объем выборки, гарантирующий с коэффициентом доверия t заданные пределы ошибки Dв:
t2s2N
nt = ¾¾¾¾¾¾. (2.27)
Dв2N + t2s2
Формула (2.27) используется при планировании выборочных наблюдений для определения величины репрезентативного (представительного) набора данных.
Пример 2.10. Обработка выборочных наблюдений. В течение года на судоходной линии было выполнено N=525 рейсов однотипными судами. В порядке собственно-случайной выборки отобрано n=50 рейсов для определения среднего процента грузов иностранных фрахтователей (ГИФ) в общем потоке грузов. Данные полученной выборки сведены в группировочную таблицу (табл.2.9), в которой выполнены расчеты элементов для исчисления среднего выборочного и выборочной дисперсии. Определить:
1)Средний процент перевозки ГИФ: `xв;
2)Выборочную дисперсию s2в этого показателя;
3)Предельную ошибку выборки Dв, гарантированную с вероятностью p =0,997;
4)Пределы `xв ± Dв , в которых находится генеральное среднее `X с заданной вероятностью p.
5)Какой объем выборки nt гарантировал бы предельную ошибку Dв, равную 5%, с такой же вероятностью p =0,997?
Таблица 2.9
| № гр. i | Границы группы | Среднее группы `xi | Час-тота mi | Элементы для исчисления `xв и s2в | |||
| mi`xi | `xi -`xв | (`xi -`xв)2 | mi(`xi -`xв)2 | ||||
| 0-15 | 7,5 | 22,5 | -45 | ||||
| 15-25 | 20,5 | 41,0 | -32 | ||||
| 25-35 | 30,5 | 122,0 | -22 | ||||
| 35-45 | 40,5 | 324,0 | -12 | ||||
| 45-55 | 50,5 | 606,0 | -2 | ||||
| 55-65 | 60,5 | 544,5 | |||||
| 65-75 | 70,5 | 352,5 | |||||
| 75-85 | 80,5 | 241,5 | |||||
| 85-100 | 92,5 | 370,0 | |||||
| å= |

