 2015-05-18
2015-05-18 730
730Для решения задачи прогнозирования требуется по экспериментальным точкам провести гладкую кривую (или, в общем случае, многомерную поверхность), то есть выявить функциональную зависимость (аппроксимация), продлить ее в неизученную область (экстраполяция) и оценить надежность прогноза. Этим и занимается эконометрика. Хорошо разработана методика линейного регрессионного анализа (линейной аппроксимации), нелинейные зависимости (степенные, показательные, логарифмические) научились линеаризовать, т.е. сводить к линейной. Вид функции часто задается из теоретических соображений, коэффициенты вычисляются методом наименьших квадратов (МНК), т.е. подбираются таким образом, чтобы сумма квадратов отклонений (остатков, разностей) теоретических и экспериментальных значений при равных аргументах была минимальной. Используются и другие методы оценки параметров моделей. Теоретические основы эконометрики изложены в учебниках Л.О.Бабешко [3] и И.И.Елисеевой [ 4 ], имеется хороший практикум И.И.Елисеевой [ 5 ].
Для конкретизации задачи будем исследовать продажу пива в зависимости от температуры воздуха в диапазоне 0 О – 30 О: Постановка задачи: по имеющимся данным о продажах в диапазоне температур 0 О …20 О спрогнозировать уровень и диапазон продаж при температуре 30 О. Обобщённая модель:
y = f (x)+u
где x – независимая (экзогенная) переменная: температура,
y - зависимая (эндогенная) переменная: продажа пива.
В таблице 4.1 и на рисунке 4.1 приведены известные нам объемы продаж при различных температурах в диапазоне 0 О – 20 О, требуется дать прогноз на диапазон 21 О – 30 О. Рассмотрим две модели и 4 способа решения задачи.
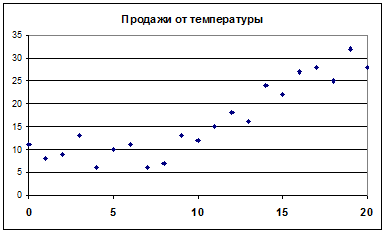 Таблица 4.1
Таблица 4.1
| Температура X | Продажи Y |
Рис.4.1.
В данной задаче температуры упорядочены изначально. В противном случае обычно требуется провести предварительную сортировку данных по независимой (экзогенной) переменной: выделить таблицу, в меню Данные – Сортировка – указать столбец независимой переменной – ОК.
4.1. Построение диаграмм и спецификация моделей.
Решение эконометрической задачи начинается со спецификации модели, то есть выявления функции регрессии и особенностей возмущений. Для этого надо построить диаграмму: выделить оба столбца данных и построить диаграмму Точечная, что позволит сразу правильно расположить данные по оси абсцисс и оценить корреляцию X и Y или ее отсутствие. Диаграмма позволяет оценить вид аппроксимирующей функции, может быть, различной в разных диапазонах Х, и увидеть точки, выпадающие из закономерности. Эти точки надо удалить из выборки и рассматривать отдельно. В данном примере аномальные значения Y могут быть связаны с праздничными днями и премиями.
Если функция Y = f(X) нелинейная, то ее, как правило, надо линеаризовать, заменив значения X и Y на их логарифмы, квадраты, квадратные корни или более сложные функции, а после решения задачи провести обратное преобразование полученной аппроксимирующей функции. Если точки уплотняются в левой части диаграммы, то целесообразно заменить значения Х, а может и Y их логарифмами. Целесообразно построить гистограммы частотных распределений X и Y, и при распределении с “толстым хвостом” провести логарифмирование.
В данном случае можно увидеть на диаграмме, что от 0 о до 10 о продажи не возрастают, а после 10 о – возрастают. Можно построить две модели с расчетом коэффициентов по различным диапазонам:
1) Линейная Y = a + b X + u в диапазоне от 10 о до 20 о;
2) Парабола Y = a + b X + с Х 2 +u в диапазоне от 0 о до 20 о.
(Любую функцию в некотором диапазоне можно достаточно точно представить многочленом).
В первом случае мы отбрасываем половину исходных данных и считаем, что до 10 о одна закономерность, а свыше 10 о – другая. Во втором случае мы используем для настройки модели все данные. Выбор модели зависит от теоретических закономерностей и от личного опыта, а также от результатов эконометрических тестов, например, теста Чоу.
Параметры моделей и прогноз можно получить, построив диаграммы.
Модель1:
- выделите оба столбца в диапазоне температур 10 о – 20 о, постройте диаграмму типа Точечная;
- щелкните правой клавишей мыши по любой точке, в появившемся окне щёлкните Добавить линию тренда, установите Тип – Линейная, выберите Параметры, установите Прогноз вперед на 10 единиц и флажки Показывать уравнение на диаграмме, Поместить на диаграмму величину достоверности (R^2) – ОК. На диаграмме появятся уравнение регрессии и коэффициент детерминации.
Модель 2:
- выделите оба столбца в диапазоне температур 0 о – 20о, постройте диаграмму типа Точечная;
- щелкните правой клавишей мыши по любой точке, в появившемся окне щёлкните Добавить линию тренда, установите Тип – Полиномиальная, Степень 2, выберите Параметры, установите Прогноз вперед на 10 единиц и флажки Показывать уравнение на диаграмме, Поместить на диаграмму величину достоверности (R^2) – ОК.
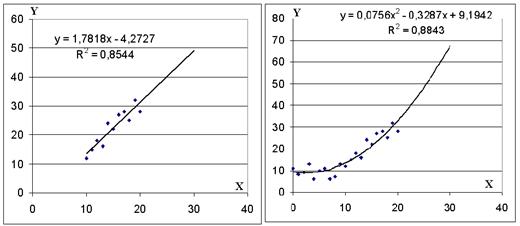
Рис.4.1. Диаграммы линейной и параболической моделей.
Индекс детерминации R2 даёт представление о надёжности модели. Критерии качества модели и её параметров мы обсудим позднее.
Возможно использование других функций: степенной, экспоненты, логарифма. Обратите внимание, что модели дают различные прогнозы на 30 о.
Данный пример служит иллюстрацией того, что в разных диапазонах переменных могут действовать разные закономерности. Из житейских соображений следует, что параболу нельзя продлевать в область отрицательных значений температуры: продажи пива зимой не вырастут. Обе функции нельзя экстраполировать на 40 и более градусов. Для каждой закономерности существует диапазон значений, или область определения экзогенной переменной.
Возникает вопрос: можно ли повысить качество модели, увеличив степень полинома? Это возможно, но только при очень большом количестве измерений и высоком (>0,95) коэффициенте детерминации. Попробуем увеличить степень полинома в нашем примере до 4, а последние 4 замера (17о - 20о) используем не для настройки модели, а для проверки её адекватности. Получим результат: Рисунок 4.2А. Получился высокий R2, последние 4 значения Y предсказаны неплохо. Решим, что модель качественная и адекватная, используем её для прогнозирования. Получим абсолютно безобразный прогноз: Рисунок 4.2 Б.
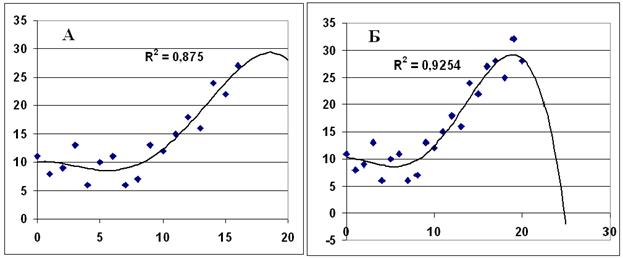 Рис. 4.2.
Рис. 4.2.
Это произошло из-за большого количества тесно связанных влияющих переменных – х в различных степенях, что привело к высокой дисперсии (большим ошибкам) коэффициентов. В диапазоне настройки эти ошибки друг друга компенсируют, а в области прогноза – нет.








