 2015-05-18
2015-05-18 2817
2817Уравнение, которое связывает зависимую (или объясняемую) переменную Y с независимыми (или объясняющими) переменными x1, x2, …, xn называют уравнением регрессии. Принято различать простую (парную) регрессию и множественную регрессию.
Простая регрессия представляет собой регрессию между двумя переменными – у и х, т. е. модель вида
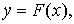
где у – зависимая переменная (результативный признак);
х – независимая или объясняющая, переменная (признак-фактор).
Парная регрессия достаточна, если имеется доминирующий фактор, который и используется в качестве объясняющей переменной (Х). Она, в свою очередь, делится на: линейную и нелинейную (показательная, степенная, гипербола и т.д.)
Множественная регрессия соответственно представляет собой регрессию результативного признака с двумя и большим числом факторов, т. е. модель вида
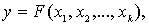
В уравнении регрессии связь переменных представляется в виде функциональной связи, выраженной соответствующей математической функцией. Практически в каждом отдельном случае величина У складывается из двух слагаемых
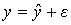 ,
,
y – фактическое значение результативного признака;
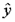 – теоретическое значение результативного признака, найденное по уравнению регрессии;
– теоретическое значение результативного признака, найденное по уравнению регрессии;
ε – случайная составляющая, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии.
Случайная составляющая ε называется также возмущением. Присутствие случайных ошибок в уравнениях объясняется несколькими причинами — влиянием неучтенных факторов, непредсказуемостью человеческих реакций, неточностями наблюдений и измерений и т.д. Присутствие в модели случайной величины порождено тремя основными источниками:
- спецификацией модели,
- выборочным характером исходных данных,
- особенностями измерения переменных.
От правильно выбранной спецификации модели зависит величина случайных ошибок: они тем меньше, чем в большей мере теоретические значения результативного признака подходят к фактическим данным.

