 2015-05-18
2015-05-18 768
768Контрольная работа
по курсу «Эконометрика и экономико-математические методы и модели»
Вариант 13
Задание 1. Модель множественной линейной регрессии
По данным таблицы 4:
1) Построить модель множественной линейной регрессии, зависимости ресурсоемкости производства мяса от восьми объясняющих переменных, используя надстройку MS Excel Пакет анализа (команда Сервис\ Анализ данных\ Регрессия)
2) Оценить значимость модели и значимость коэффициентов
3) Указать экономический смысл полученных коэффициентов модели
4) Построить «короткую» модель со значимыми коэффициентами
5) Сравнить полную и «короткую» модель, выбрать лучшую.
Решение.
1. Таблица 1. Исходные данные задачи 1
| Мясо | Ресурсо-емкость мяса т.р./ц | уд.вес высшего и спец. образ. % | Кормо-вые ресурсы ц.к.ед./ гол | фондо оснащен. животно- водства т.р./гол | износ основных фондов % | энерго оснащен. животно- водства КВт/гол | уд.вес в рационе комби- кормов % | темп воспроиз-водства поголовья % | уровень специа-лизации % |
| № хозяйства | Y1 | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 |
| 4,908 | 5,4 | 29,5 | 12,426 | -0,89 | 8,7 | 23,7 | |||
| 4,2 | 6,7 | 5,5 | -0,78 | 45,7 | 20,7 | ||||
| 3,918 | 13,7 | 44,6 | 11,7 | -0,56 | 33,9 | 28,7 | |||
| 5,416 | 16,7 | 33,8 | 11,3 | -1 | 18,7 | 16,7 | |||
| 3,813 | 4,7 | 40,2 | 4,12 | 0,7 | 26,7 | 51,7 | |||
| 3,7 | 8,7 | 5,4 | 0,9 | 38,7 | 68,7 | ||||
| 6,422 | 16,7 | 5,8 | -1 | 10,7 | 18,7 | ||||
| 3,986 | 8,7 | 44,2 | 7,94 | -0,2 | 31,7 | 19,7 | |||
| 3,82 | 13,7 | 47,4 | 6,04 | -0,1 | 27,7 | 35,7 | |||
| 18,7 | 5,8 | 0,5 | 23,7 | 48,7 | |||||
| 4,5 | 23,7 | 3,72 | -0,4 | 18,7 | 58,7 | ||||
| 5,4 | 11,7 | 4,4 | -0,9 | 13,7 | 16,7 | ||||
| 5,3 | 8,7 | 4,82 | -0,8 | 10,7 | 21,7 | ||||
| 6,1 | 10,7 | 11,7 | -0,2 | 13,7 | 23,7 | ||||
| 16,7 | 34,4 | -0,7 | 12,7 | 28,7 | |||||
| 6,5 | 6,7 | 19,7 | -0,8 | 18,7 | 38,7 | ||||
| 5,6 | 13,7 | 14,7 | -0,6 | 19,7 | 48,7 | ||||
| 5,1 | 18,7 | 8,9 | -0,4 | 16,7 | 23,7 | ||||
| 5,4 | 15,7 | 40,2 | 14,2 | 0,2 | 14,7 | 58,7 | |||
| 5,6 | 23,7 | 10,8 | 0,4 | 17,7 | 73,7 | ||||
| 6,4 | 12,7 | 7,7 | 0,6 | 21,7 | 48,7 | ||||
| 6,5 | 15,7 | 41,4 | 10,1 | 0,8 | 13,7 | 42,7 | |||
| 6,3 | 19,7 | 12,4 | 0,5 | 17,7 | 33,7 | ||||
| 6,6 | 16,7 | 13,7 | 0,2 | 15,7 | 48,7 |
1.
Скопируем таблицу 1 на лист Excel.
С помощью механизма регрессии и на основании данных таблицы 1, получим уравнение нашей модели.
Получение модели удобно осуществляется с помощью инструмента Регрессия пакета Анализ данных. Для работы с ним необходимо
- активизировать команду Сервис - Анализ данных;
- выбрать инструмент Регрессия;
- заполнить поля диалогового окна Регрессия:
· поле Входной интервал Y - диапазон ячеек зависимой величины (значения показателя Y);
· поле Входной интервал X - ввести адреса всех диапазонов, которые содержат значения независимых переменных (факторов X);
В результате проделанной работы в рабочей книге появится лист с данными.
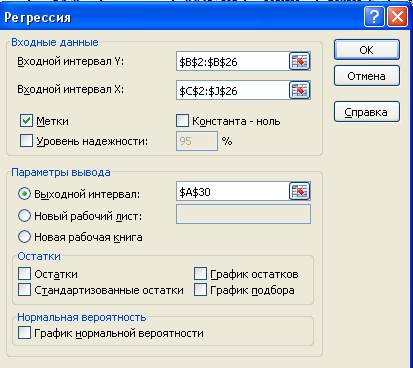
Рисунок 1. Регрессия
| Регрессионная статистика | ||||||
| Множественный R | 0,903949 | |||||
| R-квадрат | 0,817123 | |||||
| Нормированный R-квадрат | 0,719589 | |||||
| Стандартная ошибка | 0,529613 | |||||
| Наблюдения | ||||||
| Дисперсионный анализ | ||||||
| df | SS | MS | F | Значимость F | ||
| Регрессия | 18,79915 | 2,349894 | 8,377811 | 0,000244 | ||
| Остаток | 4,207353 | 0,28049 | ||||
| Итого | 23,00651 | |||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |
| Y-пересечение | 2,3512 | 1,8968 | 1,2395 | 0,2342 | -1,6918 | 6,3941 |
| X1 | -0,0206 | 0,0312 | -0,6620 | 0,5180 | -0,0871 | 0,0458 |
| X2 | 0,0936 | 0,0396 | 2,3661 | 0,0319 | 0,0093 | 0,1779 |
| X3 | 0,0790 | 0,0376 | 2,0996 | 0,0531 | -0,0012 | 0,1591 |
| X4 | 0,0223 | 0,0141 | 1,5780 | 0,1354 | -0,0078 | 0,0525 |
| X5 | 0,2751 | 0,3439 | 0,8001 | 0,4362 | -0,4578 | 1,0081 |
| X6 | -0,0736 | 0,0179 | -4,1110 | 0,0009 | -0,1118 | -0,0354 |
| X7 | -0,0194 | 0,0101 | -1,9267 | 0,0732 | -0,0409 | 0,0021 |
| X8 | 0,0053 | 0,0109 | 0,4883 | 0,6324 | -0,0179 | 0,0286 |
Таким образом, уравнение регрессии имеет следующий вид:
y = 2,3512 – 0,0206x1+0,0936х2+0,0790х3+0,0223х4+
+0,2751х5–0,0736х6–0,0194х7+0,0053х8.
2.
Для оценки качественности выбранной модели воспользуемся рассчитанными значениями коэффициентов множественной корреляции R, коэффициента детерминации R2 и нормированный R квадрат.
Коэффициент множественной корреляции R=0,9039, что свидетельствует о тесной связифакторов и результативного показателя.
Коэффициент регрессии R2=0,8171 и пересчитанное значение этого коэффициента с учетом количества используемых факторов модели 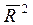 = 0,7196 также подтверждает ее качество, т.к. в модели 81,71% или 71,96% вариации переменных затрат соответственно учтено и обусловлено влиянием включенных факторов.
= 0,7196 также подтверждает ее качество, т.к. в модели 81,71% или 71,96% вариации переменных затрат соответственно учтено и обусловлено влиянием включенных факторов.
Фактическое значение F -критерия Фишера: F= 8,3778
Фактические значения t -критерия Стьюдента:
| tb1= | -0,6620 |
| tb2= | 2,3661 |
| tb3= | 2,0996 |
| tb4= | 1,5780 |
| tb5= | 0,8001 |
| tb6= | -4,1110 |
| tb7= | -1,9267 |
| tb8= | 0,4883 |
(столбец t - статистика)
Доверительные интервалы для параметров регрессии указаны в двух последних столбцах таблицы.
3.
В полученном уравнении коэффициент регрессии -0,0206 означает, что увеличение X1 на 1 в среднем приводит к снижению значения Y (ресурсоемкости мяса) на -0,0206, при условии, что остальные коэффициенты не изменятся.
Коэффициент регрессии 0,0936 означает, что увеличение X2 на 1 в среднем приводит к увеличению значения Y (ресурсоемкости мяса) на 0,0936 при условии, что остальные коэффициенты не изменятся.
Коэффициент регрессии 0,0790 означает, что увеличение X3 на 1 в среднем приводит к увеличению значения Y (ресурсоемкости мяса) на 0,0790 при условии, что остальные коэффициенты не изменятся.
Коэффициент регрессии 0,0223 означает, что увеличение X4 на 1 в среднем приводит к увеличению значения Y (ресурсоемкости мяса) на 0,0223 при условии, что остальные коэффициенты не изменятся.
Коэффициент регрессии 0,2751 означает, что увеличение X5 на 1 в среднем приводит к увеличению значения Y (ресурсоемкости мяса) на 0,2751 при условии, что остальные коэффициенты не изменятся.
Коэффициент регрессии -0,0736 означает, что увеличение X6 на 1 в среднем приводит к уменьшению значения Y (ресурсоемкости мяса) на -0,0736 при условии, что остальные коэффициенты не изменятся.
Коэффициент регрессии -0,0194 означает, что увеличение X7 на 1 в среднем приводит к уменьшению значения Y (ресурсоемкости мяса) на 0,0194 при условии, что остальные коэффициенты не изменятся.
Коэффициент регрессии 0,0053 означает, что увеличение X8 на 1 в среднем приводит к увеличению значения Y (ресурсоемкости мяса) на 0,0053 при условии, что остальные коэффициенты не изменятся.
Для проверки значимости каждого коэффициента регрессии вычисляется t -статистика, которая показывает, во сколько раз этот коэффициент превышает свою среднюю ошибку в выборке.
Соответствующая величина p (уровень значимости или вероятность ошибки) измеряет вероятность случайного появления в выборке значений t, равных или больших, чем данное значение.
Если вероятность p меньше выбранного уровня значимости (по умолчанию 5% или 0,05), соответствующий коэффициент регрессии является статистически значимым.
Если вероятность p больше выбранного уровня значимости, соответствующий коэффициент регрессии является статистически незначимым.
Статически значимые коэффициенты: X2 и X6.
4.
Построим «короткую» модель со значимыми коэффициентами. Скопируем таблицу на новый лист и удалим столбцы X1, X3, X4, X5, X7, X8.
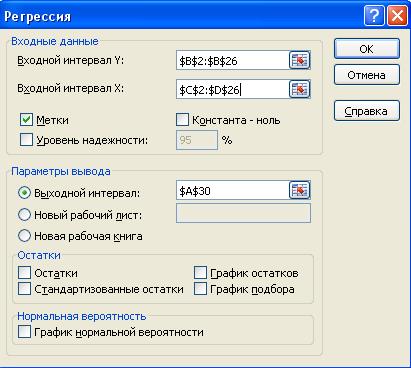
Рисунок 2. Регрессия
| Регрессионная статистика | ||||||
| Множественный R | 0,7425 | |||||
| R-квадрат | 0,5513 | |||||
| Нормированный R-квадрат | 0,5086 | |||||
| Стандартная ошибка | 0,7011 | |||||
| Наблюдения | ||||||
| Дисперсионный анализ | ||||||
| df | SS | MS | F | Значимость F | ||
| Регрессия | 12,68374 | 6,341869 | 12,9015 | 0,000222 | ||
| Остаток | 10,32277 | 0,49156 | ||||
| Итого | 23,00651 | |||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |
| Y-пересечение | 3,9552 | 1,2170 | 3,2499 | 0,0038 | 1,4243 | 6,4861 |
| X2 | 0,0751 | 0,0326 | 2,3054 | 0,0314 | 0,0074 | 0,1428 |
| X6 | -0,0890 | 0,0175 | -5,0795 | 0,0000 | -0,1254 | -0,0526 |
Таким образом, уравнение регрессии имеет следующий вид:
y = 3,9552 + 0,0751x2 – 0,0890х6.
Коэффициент множественной корреляции R=0,7425, что свидетельствует о достаточно сильной связифакторов и результативного показателя.
Коэффициент регрессии R2=0,5513 и пересчитанное значение этого коэффициента с учетом количества используемых факторов модели = 0,5086 также подтверждает ее качество, т.к. в модели 55,13% или 50,86% вариации переменных затрат соответственно учтено и обусловлено влиянием включенных факторов.
5. Сравним модели. Вычислим средние квадратические отклонения.
| Y11 | Y12 | (Y1-Y11)^2 | (Y1-Y12)^2 | |
| 5,608 | 5,396 | 0,491 | 0,238 | |
| 3,330 | 2,967 | 0,757 | 1,521 | |
| 4,628 | 4,287 | 0,504 | 0,136 | |
| 5,559 | 4,829 | 0,021 | 0,344 | |
| 3,671 | 4,598 | 0,020 | 0,616 | |
| 3,888 | 3,740 | 0,035 | 0,002 | |
| 5,973 | 5,631 | 0,202 | 0,625 | |
| 4,459 | 4,453 | 0,223 | 0,218 | |
| 4,377 | 5,049 | 0,311 | 1,511 | |
| 4,318 | 4,925 | 0,101 | 0,855 | |
| 4,555 | 5,145 | 0,003 | 0,415 | |
| 5,381 | 5,514 | 0,000 | 0,013 | |
| 5,564 | 5,631 | 0,070 | 0,110 | |
| 5,627 | 5,590 | 0,224 | 0,261 | |
| 5,173 | 5,408 | 0,030 | 0,167 | |
| 6,011 | 5,220 | 0,239 | 1,639 | |
| 5,782 | 5,506 | 0,033 | 0,009 | |
| 4,392 | 5,548 | 0,502 | 0,201 | |
| 5,400 | 5,666 | 0,000 | 0,071 | |
| 5,411 | 5,759 | 0,036 | 0,025 | |
| 5,935 | 5,629 | 0,216 | 0,595 | |
| 6,288 | 5,845 | 0,045 | 0,429 | |
| 6,663 | 6,060 | 0,132 | 0,058 | |
| 6,490 | 6,087 | 0,012 | 0,263 | |
| ИТОГО | 124,483 | 124,483 | 4,207 | 10,323 |
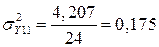 ,
, 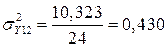
Так как, среднее квадратическое отклонение для полной модели меньше, то она лучше описывает переменную Y.








