 2015-05-10
2015-05-10 376
376- Конструкции позволяют разделить выполнение кода в параллельном регионе между нитями, его выполняющими.
- Конструкции не порождают новые нити.
- Не существует предполагаемого барьера перед входом в конструкцию, однако, такой барьер существует в конце ее работы.
Типы конструкций:
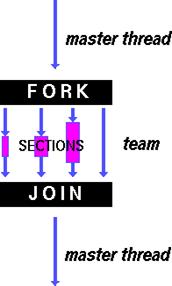
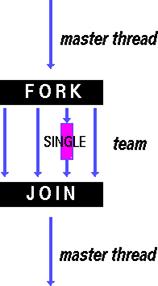
| DO / for – разделение итераций цикла между всеми нитями. Тип – параллельная обработка данных (data parallelism). | SECTIONS – разделяет работу на различные секции. Каждая секция выполняется нитью. Тип «функциональный параллелизм». | SINGLE – последовательное выполнение секции |
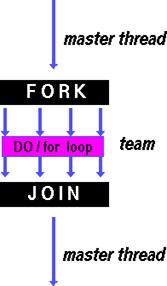
| 
| 
|
for Directive
 Purpose:
Purpose:
- Если в параллельной секции встретился оператор цикла, то, согласно общему правилу, он будет выполнен всеми нитями, т.е. каждая нить выполнит все итерации данного цикла. Данная директива используется для распределения итераций цикла между различными нитями. Если параллельная область-регион не инициализирована перед директивой – цикл выполняется как последовательный код.
Format:
Опции:
- schedule: Describes how iterations of the loop are divided among the threads in the team. The default schedule is implementation dependent.
static
Итерации цикла делятся на блоки размера chunk, и затем назначаются на нити. Если размер не задан – итерации равномерно распределяются на нити. То есть, имеет место блочно-циклическое распределение итераций: первый блок из chunk итераций выполняет первая нить, второй блок - вторая и т.д. до последней нити, затем распределение снова начинается с первой нити; по умолчанию значение chunk равно 1;
dynamic
Динамическое распределение итераций с фиксированным размером блока: сначала все нити получают порции из chunk итераций, а затем каждая нить, заканчивающая свою работу, получает следующую порцию опять-таки из chunk итераций. The default chunk size is 1.
guided
Динамическое распределение итераций блоками уменьшающегося размера; аналогично распределению DYNAMIC, но размер выделяемых блоков все время уменьшается, что в ряде случаев позволяет аккуратнее сбалансировать загрузку нитей;
For a chunk size of 1, the size of each chunk is proportional to the number of unassigned iterations divided by the number of threads, decreasing to 1.
For a chunk size with value k (greater than 1), the size of each chunk is determined in the same way with the restriction that the chunks do not contain fewer than k iterations (except for the last chunk to be assigned, which may have fewer than k iterations). The default chunk size is 1.
runtime
способ распределения итераций цикла выбирается во время работы программы в зависимости от значения переменной OMP_SCHEDULE. Размер блока не задается.
· nowait: If specified, then threads do not synchronize at the end of the parallel loop.
В конце параллельного цикла происходит неявная барьерная синхронизация параллельно работающих нитей: их дальнейшее выполнение происходит только тогда, когда все они достигнут данной точки. Если в подобной задержке нет необходимости, то директива NOWAIT позволяет нитям уже дошедшим до конца цикла продолжить выполнение без синхронизации с остальными. Если директива не указана, то в конце параллельного цикла синхронизация обязательно будет выполнена.
- ordered: Specifies that the iterations of the loop must be executed as they would be in a serial program.
- private: определяет набор локальных переменных для каждой нити
- shared: определяет набор общих переменных для всех нитей
- default: позволяет определить видимость всех переменных по умолчанию (shared | none)
- firstprivate: переменные инициализируются, принимая значения перед входом в параллельный регион из переменных основного потока.
- lastprivate: при выполнении последней итерации цикла или раздела конструкции распараллеливания значения переменных, указанных в разделе lastprivate, присваиваются переменным основного потока.
- reduction: Создается локальная копия каждой переменной из списка list для каждой нити. В конце редукции, выполняется заданная операция для всех локальных копий переменных из списка с сохранением результата в общей глобальной переменной.
Ограничения:
- Цикл не может быть циклом без контроля (типа бесконечный цикл). Параметры выполнения цикла должны быть одними для всех нитей.
- Правильность выполнения программы не должна зависеть от того какая нить выполняет определенную операцию.
- Размер блока(chunk size) должен быть определен как инвариантное целое число.
- Переменная цикла должна иметь тип integer. Беззнаковые целые числа, такие как DWORD, работать не будут.
- Цикл должен являться базовым блоком и не может использовать goto и break (за исключением оператора exit, который завершает все приложение).
- Инкрементная часть цикла for должно являться либо целочисленным сложением, либо целочисленным вычитанием и должно практически совпадать со значением инварианта цикла.
- Если используется операция сравнения < или <=, переменная цикла должна увеличиваться при каждой итерации, а при использовании операции > или >= переменная цикла должна уменьшаться.








