 2015-05-12
2015-05-12 1563
1563План занятия:
· Размещение файлов связными списками
· Связанные списки с использованием таблицы файлов
· Индексированное размещение файлов
· Структура индексных дескрипторов
· Разрежённые файлы
Размещение файлов связными списками
Каждый кластер файла содержит информацию о том, где находится следующий кластер этого файла (например, его номер). Заголовок файла в этом случае должен содержать ссылку на его первый кластер, а все свободные кластеры могут быть организованы в аналогичный список.
Размещение файлов с использованием связных списков предоставляет следующие преимущества:
- отсутствие внешней фрагментации (есть только небольшая внутренняя фрагментация, связанная с тем, что размер файла может не делиться нацело на размер кластера);
- минимум информации, необходимой для хранения в заголовке файла (только ссылки на первый кластер);
- возможность динамического изменения размера файла;
- простота реализации управления свободными блоками.
Этот подход, однако, не лишен и серьезных недостатков:
- отсутствие эффективной реализации случайного доступа к файлу: для того чтобы получить доступ к кластеру с номером п, нужно прочитать все кластеры файла с номерами от 1 до n-1;
- снижение производительности тех приложений, которые считывают данные блоками, по размеру равными степени числа 2 (а таких приложений достаточно много): часть любого кластера должна содержать номер следующего, поэтому полезна информация в кластере занимает объем, не кратный его размеру (этот объем даже не является степенью числа 2);
- возможность потери информации в последовательности кластеров, если в результате сбоя будет потеряно кластер в начале файла, вся информация в кластерах, идущие за ним, и будет потеряна.
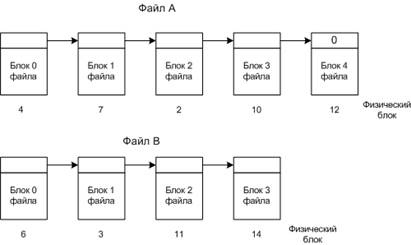
Рисунок 20.11 Размещение файлов связными списками.
Связанные списки с использованием таблицы файлов
Этот подход заключается в том, что все ссылки, которые формируют списки кластеров файла, хранятся в отдельной области файловой системы фиксированного размера, формируя таблицу размещения файлов (File Allocation Table, FAT). Элемент такой таблицы соответствует кластеру на диске и может содержать:
- номер следующего кластера, если этот кластер принадлежит файлу и не является его последним кластером;
- индикатор конца файла, если этот кластер является последним кластером файла;
- индикатор, который показывает, что этот кластер свободен.
Для организации файла достаточно поместить в соответствующий ему элемент каталога, номер первого кластера файла. При необходимости прочитать файл, система находит по этому номеру кластера, соответствующий элемент FAT, считывает с него информацию о следующем кластере и т. д. Этот процесс продолжается до тех пор, пока не сработает индикатор конца файла.
Использование этого подхода позволяет повысить эффективность и надежность размещения файлов связными списками. Это достигается благодаря тому, что размеры FAT позволяют кэшироваться в памяти. Поэтому доступ к диску во время отслеживания ссылок, заменяют обращениями к оперативной памяти. Отметим, что даже если такое кэширование не реализовано, случайный доступ к файлу не приведет к чтению всех предыдущих его кластеров – считанные данные, будут только предварительными элементами FAT.
Кроме того, упрощена защита от сбоев. Для этого, на диске храниться дополнительная копия FAT, автоматически синхронизирующаяся с основной. В случае повреждения одной из копий, информация может быть восстановлена с другой.
Служебная информация не хранится в кластерах файла, освобождая в них место для данных. Теперь объем полезных данных внутри кластера почти всегда (за исключением, возможно, последнего кластера файла) равен степени числа 2.
Однако в случае такого способа размещения файлов большого размера, FAT может стать довольно большим и его кэширование может потребовать значительных затрат памяти. Сократить размер таблицы можно, увеличив размер кластера, но это, в свою очередь, приводит к увеличению внутренней фрагментации для малых файлов (меньших размера кластера).
Также разрушение обоих копий FAT (вследствие аппаратного сбоя или действия программы-злоумышленника, например, компьютерного вируса) делает восстановление данных очень сложной задачей, которую не всегда можно решить.
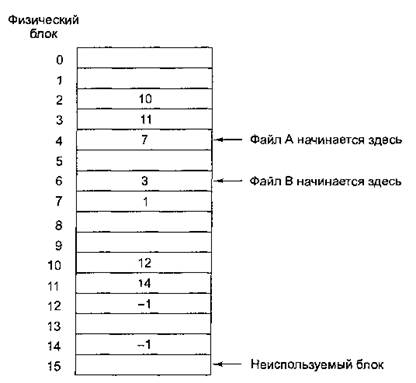
Рисунок 20.2. Таблица файлов.
Индексированное размещение файлов
Базовой идеей еще одного подхода к размещению файлов является перечень адресов всех кластеров файла в его заголовке. Такой заголовок файла получил название индексного дескриптора, или i-узла (inode), а сам подход - скорректированное размещение файлов.
При использовании индексного дескриптора, с каждым файлом связывают его уникальный индекс. Он содержит массив с адресами (или номерами) всех кластеров этого файла, при этом n-ый элемент массива соответствует n-ому кластеру. Индексные дескрипторы хранят отдельно от данных файла, для этого, в начале раздела выделяют специальный участок индексных дескрипторов. В элементе каталога размещают номер индексного дескриптора, соответствующего файла.
При создании файла на диске размещают его индексный дескриптор, в котором все указатели на кластеры изначально является пустыми. Во время первого записи в n-й кластер файла менеджер свободного пространства выделяет свободный кластер и его номер или адрес заносят в соответствующий элемент массива
Этот подход устойчив к внешней фрагментации и эффективно поддерживает как последовательный, так и случайный доступ (информация обо всех кластеры сохраняется компактно и может быть считана за одну операцию). Для повышения эффективности индексный дескриптор полностью загружают в память, когда процесс начинает работать с файлом, и оставляют в памяти до тех пор, пока эта работа продолжается.
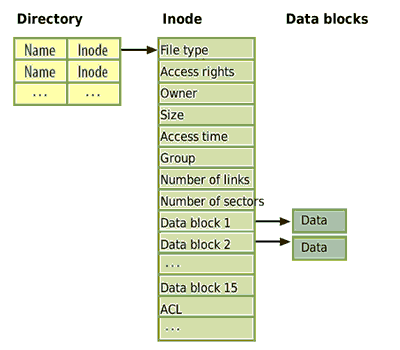
Рисунок 20.3. Индексное расположение файлов на диске.
Структура индексных дескрипторов
Размер блока может отличаться от 4 Кбайт. Чем больше блок, тем больше размер, который может быть достигнут файлом, пока не возникнет необходимости в косвенной адресации высокого уровня. С другой стороны, больший размер блока вызывает большую внутреннюю фрагментацию.
Для улучшения работы, можно распределять дисковое пространство не блоками (кластерами), а их группами (непрерывными участками из нескольких дисковых блоков). Такие группы называют экстентами (extents). Каждый экстент характеризуется длиной (в блоках) и номером, начального дискового блока. Когда возникает необходимость выделить несколько непрерывно расположенных блоков одновременно, вместо этого выделяют только один экстент нужной длины. В результате объем служебной информации, которую нужно хранить, может быть сокращен.
Характер преобразования адреса в номер кластера делает этот подход аналогом страничной организации памяти, причем индексный дескриптор соответствует таблице страниц.
Разрежённые файлы
Многие операционные системы не хранят указатели на дисковые блоки файлов в их индексных дескрипторах, пока к ним не было доступа для записи. Фрагменты, в которых этого доступа не было с момента создания файла, называют «дырами» (holes), дисковое пространство под них не выделяют, но при расчете длины файла их учитывают. В случае чтения содержания «дыры», возвращают блоки, заполненные нулями, обращение к диску не происходит.
На практике «дыры» чаще всего возникают, когда указатель текущей позиции файла перемещают далеко за его конец, после чего выполняют операцию записи. В результате чего, размер файла увеличивается без дополнительного выделения дискового пространства. Подобные файлы называют разреженными файлами (sparse files). Они реально занимают на диске места намного меньше, чем их длина, фактически длина разреженного файла может превышать размер раздела, на котором он находится.
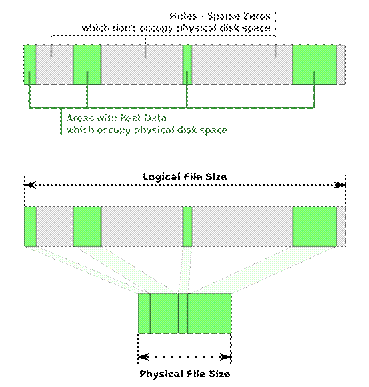
Рисунок 20.4. Разрежённые файлы на диске

