2014-02-02
2014-02-02 1194
1194Взаимная увязка базовых информационных процессов, их синхронизация на логическом уровне осуществляются через модель управления данными (УД). Так как базовые информационные процессы оперируют данными, то управление данными - это управление процессами обработки, обмена и накопления. На логическом уровне управление процессом накопления - это комплексы программ управления базами данных, получившие название систем управления базами данных. С увеличением объемов информации, хранимых в базах данных, при переходе к распределенным базам и банкам данных управление процессом накопления усложняется и не всегда поддается формализации. Поэтому в АИТ при реализации процесса накопления часто возникает необходимость в человеке - администраторе базы данных, который формирует и ведет модель накопления данных, определяя ее содержание и актуальное состояние.
Модель представления знаний может быть выбрана в зависимости от предметной области и вида решаемых задач. Сейчас практически используются такие модели, как логические (Л), алгоритмические (А), фреймовые (Ф), семантические (С) и интегральные (И).
Процедуры и составляют информационный процесс обмена. Для качественной работы сети необходимы формальные соглашения между ее пользователями, что реализуется в виде протоколов сетевого обмена. В свою очередь, передача данных основывается на моделях кодирования, модуляции, каналов связи. На основе моделей обмена производится синтез системы обмена данными, при котором оптимизируются топология и структура вычислительной сети, метод коммутации, протоколы и процедуры доступа, адресации и маршрутизации.
Модель обмена данными включает в себя формальное описание процедур, выполняемых в вычислительной сети: передачи (П), маршрутизации (М), коммутации (К). Именно эти
Модель накопления данных формализует описание информационной базы, которая в компьютерном виде представляется базой данных. Процесс перехода от информационного (смыслового) уровня к физическому отличается трехуровневой системой моделей представления информационной базы: концептуальной, логической и физической схем. Концептуальная схема информационной базы (КСБ) описывает информационное содержание предлагаемой области, т.е. какая и в каком объеме информация должна накапливаться при реализации информационной технологии. Логическая схема информационной базы (ЛСБ) должна формализовано описать ее структуру и взаимосвязь элементов информации. При этом могут быть использованы различные подходы: реляционный, иерархический, сетевой. Выбор подхода определяет и систему управления базой данных, которая, в свою очередь, определяет физическую модель данных - физическую схему информационной базы (ФСБ), описывающую методы размещения данных и доступа к ним на машинных (физических) носителях информации.
ФИЗИЧЕСКИЙ УРОВЕНЬ
Физический уровень информационной технологии представляет ее программно-аппаратную реализацию. При этом стремятся максимально использовать типовые технические средства и программное обеспечение, что существенно уменьшает затраты на создание и эксплуатацию АИТ. С помощью программно-аппаратных средств практически осуществляются базовые информационные процессы и процедуры в их взаимосвязи и подчинении единой цели функционирования. Таким образом, и на физическом уровне АИТ рассматривается как система, причем большая система, в которой выделяется несколько крупных подсистем (рис. 2.3). Это подсистемы, реализующие на физическом уровне информационные процессы: подсистема обработки данных, подсистема обмена данными, подсистема накопления данных, подсистема управления данными и подсистема представления знаний. С системой информационной технологии взаимодействуют пользователь и проектировщик системы.
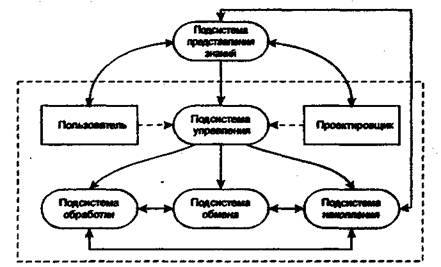
Рис. 2.3. Взаимосвязь подсистем базовой информационной технологии
Для выполнения функций подсистемы обработки данных используются электронные вычислительные машины различных классов. В настоящее время при создании автоматизированных информационных технологий применяются три основных класса ЭВМ: на верхнем уровне - большие универсальные ЭВМ (по зарубежной классификации - мэйнфреймы), способные накапливать и обрабатывать громадные объемы информации и используемые как главные ЭВМ; на среднем - абонентские вычислительные машины (серверы); на нижнем уровне - персональные компьютеры либо управляющие ЭВМ. Обработка данных, т.е. их преобразование и отображение, производится с помощью программ решения задач в той предметной области, для которой создана информационная технология.
В подсистему обмена данными входят комплексы программ и устройств, позволяющих реализовать вычислительную сеть и осуществить по ней передачу и прием сообщений с необходимыми скоростью и качеством. Физическими компонентами подсистемы обмена служат устройства приема передачи (модемы, усилители, коммутаторы, кабели, специальные вычислительные комплексы, осуществляющие коммутацию, маршрутизацию и доступ к сетям). Программными компонентами подсистемы являются программы сетевого обмена, реализующие сетевые протоколы, кодирование-декодирование сообщений и др.
Подсистема накопления данных реализуется с помощью банков и баз данных, организованных на внешних устройствах компьютеров и ими управляемых. В вычислительных сетях, помимо локальных баз и банков, используется организация распределенных банков данных и распределенной обработки данных. Аппаратно-программными средствами этой подсистемы являются компьютеры различных классов с соответствующим программным обеспечением.
Для автоматизированного формирования модели предметной области из ее фрагментов и модели решаемой информационной технологией задачи создается подсистема представления знаний. На стадии проектирования информационной технологии проектировщик формирует в памяти компьютера модель заданной предметной области, а также комплекс моделей решаемых
технологией задач. На стадии эксплуатации пользователь обращается к подсистеме знаний и, исходя из постановки задачи, выбирает в автоматизированном режиме соответствующую модель решения, после чего через подсистему управления данными включаются другие подсистемы информационной технологии. Реализация подсистем представления знаний производится, как правило, на персональных компьютерах, программирование которых осуществляется с помощью прологоподобных или алголоподобных языков. При отсутствии в АИТ подсистемы представления знаний состав и взаимосвязь подсистем ограничиваются пунктирным контуром (см. рис. 2.3).
Подсистема управления данными организуется на компьютерах с помощью подпрограммных систем управления обработкой данных и организации вычислительного процесса, систем управления вычислительной сетью и систем управления базами данных. При больших объемах накапливаемой на компьютере и циркулирующей в сети информации на предприятиях, где внедрена информационная технология, могут создаваться специальные службы, такие, как администратор баз данных, администратор вычислительной сети и т.п.
В настоящее время мультимедиа-технологии являются бурно развивающейся областью информационных технологий. В этом на-правлении активно работает значительное число крупных и мелких фирм, технических университетов и студий (в частности ІВМ, Аррlе, Моtoгоlа, Рhіlірs, Sоnу, Іntеl и др.). Области использования чрезвычайно многообразны: интерактивные обучающие и инфор-мационные системы, САПР, развлечения и др.
Основными характерными особенностями этих технологий яв-ляются:
• объединение многокомпонентной информационной среды (текста, звука, графики, фото, видео) в однородном цифровом представлении; обеспечение надежного (отсутствие искажений при копиро-
вании) и долговечного хранения (гарантийный срок хране-
ния — десятки лет) больших объемов информации;
• простота переработки информации (от рутинных до творче-
ских операций).
Многокомпонентную мультимедиа-среду целесообразно разделить на три группы: аудиоряд, видеоряд, текстовая информация.
Аудиоряд может включать речь, музыку, эффекты (звуки типа шума, грома, скрипа и т. д., объединяемые обозначением WAVE (волна) [42]. Главной проблемой при использовании этой группы мультисреды является информационная емкость. Для записи одной минуты WAVE-звука высшего качества необходима память порядка 10 Мбайт, поэтому стандартный объем СD (до 640 Мбайт) позво-ляет записать не более часа WAVE. Для решения этой проблемы используются методы компрессии звуковой информации.
Другим направлением является использование в мультисреде звуков (одноголосая и многоголосая музыка, вплоть до оркестра, звуковые эффекты) MIDI (Мusісаl Іnstrument Digitale Interface). В данном случае звуки музыкальных инструментов, звуковые эф-фекты синтезируются программно-управляемыми электронными синтезаторами. Коррекция и цифровая запись МIDI-звуков осу-ществляется с помощью музыкальных редакторов (программ-се-квенсоров). Главным преимуществом МІDI является малый объ-ем требуемой памяти — 1 минута МIDI-звука занимает в среднем 10 кбайт.
Видеоряд по сравнению с аудиорядом характеризуется большим числом элементов. Выделяют статический и динамический видео-ряды.
Видеоряд по сравнению с аудиорядом характеризуется большим числом элементов. Выделяют статический и динамический видео-ряды.
Статический видеоряд включает графику (рисунки, интерьеры, поверхности, символы в графическом режиме) и фото (фотографии и сканированные изображения).
• Динамический видеоряд представляет собой последователь-ность статических элементов (кадров).
• 24-битные видеоадаптеры (видеопамять 2 Мбайт, 24 бит/пик-
сель) позволяют использовать 16 млн цветов.
Вторая проблема — объем памяти. Для статических изображений один полный экран требует следующие объемы памяти:
• в режиме 640 х 480, 16 цветов — 150 кбайт;
• в режиме 320 х 200, 256 цветов — 62, 5 кбайт;
• в режиме 640 х 480, 256 цветов — 300 кбайт.
Такие значительные объемы при реализации аудио- и видеорядов определяют высокие требования к носителю информации, видеопамяти и скорости передачи информации.
При размещении текстовой информации на СD-RОМ нет никаких сложностей и ограничений ввиду большого информационного объема оптического диска.
Основные направления использования мультимедиатехнологий:
• электронные издания для целей образования, развлечения и др.;
• в телекоммуникациях со спектром возможных применений от
просмотра заказной телепередачи и выбора нужной книги до уча-
стия в мультимедиа-конференциях. Такие разработки получили на-
звание Іnformation higway;
• мультимедийные информационные системы («мультиме-
диакиоски»), выдающие по запросу пользователя наглядную ин-
формацию.
С точки зрения технических средств на рынке представлены как полностью укомплектованные мультимедиа-компьютеры, так и отдельные комплектующие и подсистемы (Multimedia upgrade Kit), включающие в себя звуковые карты, приводы компакт-дисков, джойстики, микрофоны, акустические системы.
Для персональных компьютеров класса ІВМ РС утвержден спе-циальный стандарт МРС, определяющий минимальную конфигу-рацию аппаратных средств для воспроизведения мультимедиа-продуктов. Для оптических дисков СD-RОМ разработан международ-ный стандарт ІSО 9660. Достигнутый технологический базис основан на использовании нового стандарта оптического носителя DVD (Dіgіtаl Versalite/Video Disk), имеющего емкость порядка единиц и десят-ков гигабайт и заменяющего все предыдущие: СD-RОМ, Video- СD, CD-аudio. Использование DVD позволило реализовать концепцию однородности цифровой информации. Одно устройст-во заменяет аудиоплейер, видеомагнитофон, CD-ROM, дисковод, слайдер и др. В плане представления информации оптический но-ситель DVD приближает ее к уровню виртуальной реальности.
ГЕОИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ
В настоящее время в соответствии с требованиями новых информационных технологий создаются и функционируют многие системы управления, связанные с необходимостью отображения информации на электронной карте:
• системы федерального и муниципального управления;
• системы военного назначения и т.д.
Эти системы управления регулируют деятельность технических и социальных систем, функционирующих в некотором операционном пространстве (географическом, экономическом и т.п.) с явно выраженной пространственной природой.
При решении задач социального и технического регулирования в системах управления используется масса пространственной информации: топография, гидрография, инфраструктура, коммуникации, размещение объектов.
Графическое представление какой-либо ситуации на экране компьютера подразумевает отображение различных графических образов. Сформированный на экране ЭВМ графический образ состоит из двух различных с точки зрения среды хранения частей — графической «подложки» или графического фона и других графических объектов. По отношению к этим другим графическим образам «образ-подложка» является «площадным», или пространственным двухмерным изображением. Основной проблемой при реализации геоинформационных приложений является трудность формализованного описания конкретной предметной области и ее отображения на электронной карте.
Таким образом, геоинформационные технологии предназначены для широкого внедрения в практику методов и средств работы с пространственно-временными данными, представляемыми в виде
системы электронных карт, и предметно-ориентированных сред обработки разнородной информации для различных категорий пользователей.
Основным классом данных геоинформационных систем (ГИС) являются координатные данные, содержащие геометрическую информацию и отражающие пространственный аспект. Основные типы координатных данных: точка (узлы, вершины), линия (незамкнутая), контур (замкнутая линия), полигон (ареал, район). На практике для построения реальных объектов используют большее число данных (например, висячий узел, псевдоузел, нормальный узел, покрытие, слой и др.). На рис. 5.1 показаны основные из рассмотренных элементов координатных данных [29].
Рассмотренные типы данных имеют большее число разнообразных связей, которые можно условно разделить на три группы:
• взаимосвязи для построения сложных объектов из простых элементов;
• взаимосвязи, вычисляемые по координатам объектов;
• взаимосвязи, определяемые с помощью специального описания и семантики при вводе данных.
Основой визуального представления данных при использовании ГИС-технологий является графическая среда, основу которой составляют векторные и растровые (ячеистые) модели.
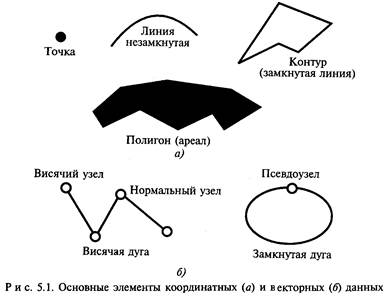
Векторные модели основаны на представлении геометрической информации с помощью векторов, занимающих часть пространства, что требует при реализации меньшего объема памяти. Используются векторные модели в транспортных, коммунальных, маркетинговых приложениях ГИС.
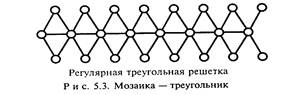
В растровых моделях объект (территория) отображается в пространственные ячейки, образующие регулярную сеть. Каждой ячейке растровой модели соответствует одинаковый по размерам, но разный по характеристикам (цвет, плотность) участок поверхности. Ячейка модели характеризуется одним значением, являющимся средней характеристикой участка поверхности. Эта процедура называется пикселизацией. Растровые модели делятся на регулярные, нерегулярные и вложенные (рекурсивные или иерархические) мозаики. Плоские регулярные мозаики бывают трех типов: квадрат (рис. 5.2), треугольник (рис. 5.3) и шестиугольник.
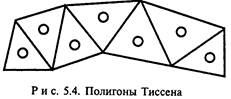
Квадратная форма удобна при обработке больших объемов информации, треугольная — для создания сферических поверхностей. В качестве нерегулярных мозаик используют треугольные сети неправильной формы (Triangulated Irregular Network — TIN) и полигоны Тиссена (рис. 5.4). Они удобны для создания цифровых моделей отметок местности по заданному набору точек.
Таким образом, векторная модель содержит информацию о местоположении объекта, а растровая о том, что расположено в той или иной точке объекта. Векторные модели относятся к бинарным или квазибинарным. Растровые позволяют отображать полутона.
Основной областью использования растровых моделей является обработка аэрокосмических снимков.
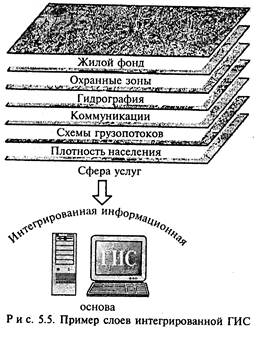
Цифровая карта может быть организована в виде множества слоев (покрытий или карт подложек). Слои в ГИС представляют набор цифровых картографических моделей, построенных на основе объединения (типизации) пространственных объектов, имеющих общие функциональные признаки. Совокупность слоев образует интегрированную основу графической части ГИС. Пример слоев интегрированной ГИС представлен на рис. 5.5.
Важным моментом при проектировании ГИС является размерность модели. Применяют двухмерные модели координат (2D) и трехмерные (3D). Двухмерные модели используются при построе-
нии карт, а трехмерные — при моделировании геологических процессов, проектировании инженерных сооружений (плотин, водохранилищ, карьеров и др.), моделировании потоков газов и жидкостей. Существуют два типа трехмерных моделей: псевдотрехмерные, когда фиксируется третья координата и истинные трехмерные.
Большинство современных ГИС осуществляет комплексную обработку информации:
• сбор первичных данных;
• накопление и хранение информации;
• различные виды моделирования (семантическое, имитационное, геометрическое, эвристическое);
• автоматизированное проектирование;
• документационное обеспечение.
Основные области использования ГИС:
• электронные карты;
• городское хозяйство;
• государственный земельный кадастр;
• экология;
• экономика;
• специальные системы военного назначения.
 |
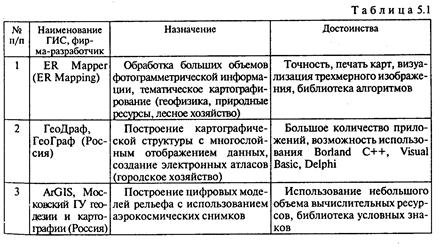
В табл. 5.1 дана краткая характеристика современных отечественных и зарубежных ГИС [50].
Наряду с позитивным влиянием на все стороны человеческой деятельности широкое внедрение информационных технологий привело к появлению новых угроз безопасности людей. Это связано с тем обстоятельством, что информация, создаваемая, хранимая и обрабатываемая средствами вычислительной техники, стала определять действия большей части людей и технических систем. В связи с этим резко возросли возможности нанесения ущерба, связанные с хищением информации, так как воздействовать на любую
систему (социальную, биологическую или техническую) с целью ее уничтожения, снижения эффективности функционирования или воровства ее ресурсов (денег, товаров, оборудования) возможно только в том случае, когда известна информация о ее структуре и принципах функционирования.
Все виды информационных угроз можно разделить на две большие группы [18]:
• отказы и нарушения работоспособности программных и технических средств;
• преднамеренные угрозы, заранее планируемые злоумышленниками для нанесения вреда.
Выделяют следующие основные группы причин сбоев и отказов в работе компьютерных систем:
• нарушения физической и логической целостности хранящихся в оперативной и внешней памяти структур данных, возникающие по причине старения или преждевременного износа их носителей;
• нарушения, возникающие в работе аппаратных средств из-за их старения или преждевременного износа;
• нарушения физической и логической целостности хранящихся в оперативной и внешней памяти структур данных, возникающие по причине некорректного использования компьютерных ресурсов;
• нарушения, возникающие в работе аппаратных средств из-за неправильного использования или повреждения, в том числе из-за неправильного использования программных средств;
• неустраненные ошибки в программных средствах, не выявленные в процессе отладки и испытаний, а также оставшиеся в аппаратных средствах после их разработки.
Помимо естественных способов выявления и своевременного устранения указанных выше причин, используют следующие специальные способы защиты информации от нарушений работоспособности компьютерных систем:
• внесение структурной, временной, информационной и функциональной избыточности компьютерных ресурсов;
" защиту от некорректного использования ресурсов компьютерной системы;
• выявление и своевременное устранение ошибок на этапах разработки программно-аппаратных средств.
Структурная избыточность компьютерных ресурсов достигается за счет резервирования аппаратных компонентов и машинных носителей данных, организации замены отказавших и своевременного пополнения резервных компонентов [19]. Структурная избыточность составляет основу остальных видов избыточности.
Внесение информационной избыточности выполняется путем периодического или постоянного (фонового) резервирования данных на основных и резервных носителях. Зарезервированные данные обеспечивают восстановление случайно или преднамеренно уничтоженной и искаженной информации. Для восстановления работоспособности компьютерной системы после появления устойчивого отказа кроме резервирования обычных данных следует заблаговременно резервировать и системную информацию, а также подготавливать программные средства восстановления.
Функциональная избыточность компьютерных ресурсов достигается дублированием функций или внесением дополнительных функций в программно-аппаратные ресурсы вычислительной системы для повышения ее защищенности от сбоев и отказов, например периодическое тестирование и восстановление, а также самотестирование и самовосстановление компонентов компьютерной системы.
Защита от некорректного использования информационных ресурсов заключается в корректном функционировании программного обеспечения с позиции использования ресурсов вычислительной системы. Программа может четко и своевременно выполнять свои функции, но некорректно использовать компьютерные ресурсы из-за отсутствия всех необходимых функций (например, изолирование участков оперативной памяти для операционной системы и прикладных программ, защита системных областей на внешних носителях, поддержка целостности и непротиворечивости данных).
Выявление и устранение ошибок при разработке программно-аппаратных средств достигается путем качественного выполнения базовых стадий разработки на основе системного анализа концепции, проектирования и реализации проекта.
Однако основным видом угроз целостности и конфиденциальности информации являются преднамеренные угрозы, заранее планируемые злоумышленниками для нанесения вреда. Их можно разделить на две группы:
• угрозы, реализация которых выполняется при постоянном участии человека;
• угрозы, реализация которых после разработки злоумышленником соответствующих компьютерных программ выполняется этими программами без непосредственного участия человека.
Задачи по защите от угроз каждого вида одинаковы:
• запрещение несанкционированного доступа к ресурсам вычислительных систем;
• невозможность несанкционированного использования компьютерных ресурсов при осуществлении доступа;
• своевременное обнаружение факта несанкционированных действии, устранение их причин и последствий.
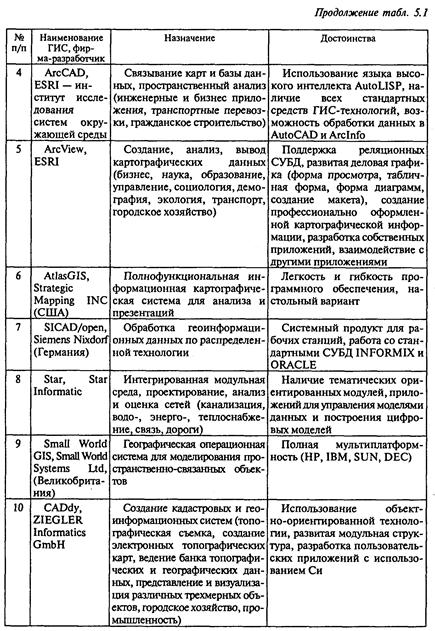
Основным способом запрещения несанкционированного доступа к ресурсам вычислительных систем является подтверждение подлинности пользователей и разграничение их доступа к информационным ресурсам, включающего следующие этапы:
• идентификация;
• установление подлинности (аутентификация);
• определение полномочий для последующего контроля и разграничения доступа к компьютерным ресурсам.
Идентификация необходима для указания компьютерной системе уникального идентификатора обращающегося к ней пользователя. Идентификатор может представлять собой любую последовательность символов и должен быть заранее зарегистрирован в системе администратора службы безопасности. В процессе регистрации заносится следующая информация:
• фамилия, имя, отчество (при необходимости другие характеристики пользователя);
• уникальный идентификатор пользователя;
• имя процедуры установления подлинности;
• эталонная информация для подтверждения подлинности (например, пароль);
• ограничения на используемую эталонную информацию (например, время действия пароля);
• полномочия пользователя по доступу к компьютерным ресурсам.
Установление подлинности (аутентификация) заключается в проверке истинности полномочий пользователя.
Общая схема идентификации и установления подлинности пользователя представлена на рис. 5.6 [17].
Для особо надежного опознания при идентификации используются технические средства, определяющие индивидуальные характеристики человека (голос, отпечатки пальцев, структура зрач-
ка). Однако такие методы требуют значительных затрат и поэтому используются редко.
 |
Наиболее массово используемыми являются парольные методы проверки подлинности пользователей. Пароли можно разделить на две группы: простые и динамически изменяющиеся.
Простой пароль не изменяется от сеанса к сеансу в течение установленного периода его существования.
Во втором случае пароль изменяется по правилам, определяемым используемым методом. Выделяют следующие методы реализации динамически изменяющихся паролей:
• методы модификации простых паролей. Например, случайная выборка символов пароля и одноразовое использование паролей;
• метод «запрос—ответ», основанный на предъявлении пользователю случайно выбираемых запросов из имеющегося массива;
• функциональные методы, основанные на использовании некоторой функции F с динамически изменяющимися параметрами (дата, время, день недели и др.), с помощью которой определяется пароль.
Для защиты от несанкционированного входа в компьютерную систему используются как общесистемные, так и специализированные программные средства защиты.
После идентификации и аутентификации пользователя система защиты должна определить его полномочия для последующего контроля санкционированного доступа к компьютерным ресурсам (разграничение доступа). В качестве компьютерных ресурсов рассматриваются:
• программы;
• внешняя память (файлы, каталоги, логические диски);
• информация, разграниченная по категориям в базах данных;
• оперативная память;
• время (приоритет) использования процессора;
• порты ввода-вывода;
• внешние устройства.
Различают следующие виды прав пользователей по доступу к ресурсам:
• всеобщее (полное предоставление ресурса);
• функциональное или частичное;
• временное.
Наиболее распространенными способами разграничения доступа являются:
• разграничение по спискам (пользователей или ресурсов);
• использование матрицы установления полномочий (строки матрицы — идентификаторы пользователей, столбцы — ресурсы компьютерной системы);
• разграничение по уровням секретности и категориям (например, общий доступ, конфиденциально, секретно);
• парольное разграничение.
 |
Защита информации от исследования и копирования предполагает криптографическое закрытие защищаемых от хищения данных. Задачей криптографии является обратимое преобразование некоторого понятного исходного текста (открытого текста) в кажущуюся случайной последовательность некоторых знаков, часто называемых шифротекстом, или криптограммой. В шифре выделяют два основных элемента — алгоритм и ключ. Алгоритм шифрования представляет собой последовательность преобразований обрабатываемых данных, зависящих от ключа шифрования. Ключ задает значения некоторых параметров алгоритма шифрования, обеспечивающих шифрование и дешифрование информации. В криптогра-
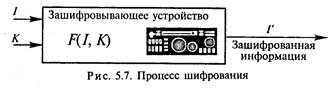
фической системе информация I и ключ К являются входными данными для шифрования (рис. 5.7) и дешифрования (рис. 5.8) информации. При похищении информации необходимо знать ключ и алгоритм шифрования.
По способу использования ключей различают два типа криптографических систем: симметрические и асимметрические.
В симметрических (одноключевых) криптографических системах ключи шифрования и дешифрования либо одинаковы, либо легко выводятся один из другого.
В асимметрических (двухключевых или системах с открытым Ключом) криптографических системах ключи шифрования и дешифрования различаются таким образом, что с помощью вычислений нельзя вывести один ключ из другого. ' Скорость шифрования в двухключевых криптографических системах намного ниже, чем в одноключевых. Поэтому асимметрические системы используют в двух случаях:
• для шифрования секретных ключей, распределенных между пользователями вычислительной сети;
• для формирования цифровой подписи.
Одним из сдерживающих факторов массового применения методов шифрования является потребление значительных временных ресурсов при программной реализации большинства хорошо известных шифров (DES, FEAL, REDOC, IDEA, ГОСТ). Одной из основных угроз хищения информации является угроза доступа к остаточным данным в оперативной и внешней памяти компьютера. Под остаточной информацией понимают данные, оставшиеся в освободившихся участках оперативной и внешней памяти после удаления файлов пользователя, удаления временных файлов без ведома пользователя, находящиеся в неиспользуемых
хвостовых частях последних кластеров, занимаемых файлами, а также в кластерах, освобожденных после уменьшения размеров файлов и после форматирования дисков.
Основным способом защиты от доступа к конфиденциальным остаточным данным является своевременное уничтожение данных в следующих областях памяти компьютера:
• в рабочих областях оперативной и внешней памяти, выделенных пользователю, после окончания им сеанса работы;
• в местах расположения файлов после выдачи запросов на их удаление.
Уничтожение остаточных данных может быть реализовано либо средствами операционных сред, либо с помощью специализированных программ. Использование специализированных программ (автономных или в составе системы защиты) обеспечивает гарантированное уничтожение информации.
Подсистема защиты от компьютерных вирусов (специально разработанных программ для выполнения несанкционированных действий) является одним из основных компонентов системы защиты информации и процесса ее обработки в вычислительных системах.
Выделяют три уровня защиты от компьютерных вирусов [20]:
• защита от проникновения в вычислительную систему вирусов известных типов;
• углубленный анализ на наличие вирусов известных и неизвестных типов, преодолевших первый уровень защиты;
• защита от деструктивных действий и размножения вирусов, преодолевших первые два уровня.
Поиск и обезвреживание вирусов осуществляются как автономными антивирусными программными средствами (сканеры), так и в рамках комплексных систем защиты информации.
Среди транзитных сканеров, которые загружаются в оперативную память, наибольшей популярностью в нашей стране пользуются антивирусные программы Aidstest Дмитрия Лозинского и DrWeb Игоря Данилова. Эти программы просты в использовании и для детального ознакомления с руководством по каждой из них следует прочитать файл, поставляемый вместе с антивирусным средством.
Широкое внедрение в повседневную практику компьютерных сетей, их открытость, масштабность делают проблему защиты информации исключительно сложной. Выделяют две базовые подзадачи:
• обеспечение безопасности обработки и хранения информации в каждом из компьютеров, входящих в сеть;
• защита информации, передаваемой между компьютерами сети.
Решение первой задачи основано на многоуровневой защите автономных компьютерных ресурсов от несанкционированных и некорректных действий пользователей и программ, рассмотренных выше.
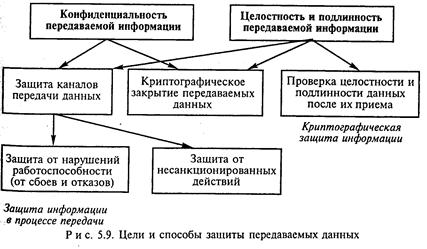
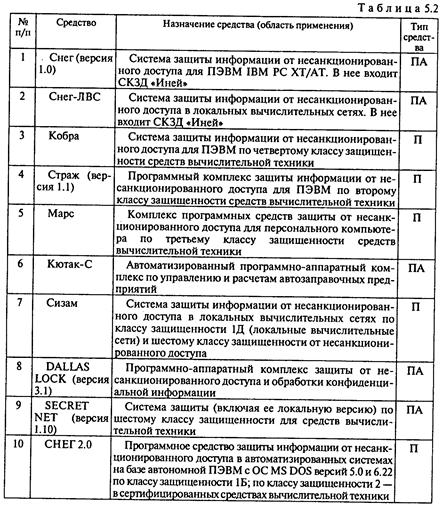
Безопасность информации при сетевом обмене данными требует также обеспечения их конфиденциальности и подлинности. Защита информации в процессе передачи достигается на основе защиты каналов передачи данных, а также криптографического закрытия передаваемых сообщений. В идеальном случае защита каналов передачи данных должна обеспечивать их защиту как от нарушений работоспособности, так и несанкционированных действий (например, подключения к линиям связи). По причине большой протяженности каналов связи, а также возможной доступности их отдельных участков (например, при беспроводной связи) защита каналов передачи данных от несанкционированных действий экономически неэффективна, а в ряде случаев невозможна. Поэтому реально защита каналов передачи данных строится на основе защиты нарушений их работоспособности. На рис. 5. 9 представлены цели и способы защиты передаваемых данных В табл. 5. 2 приведены краткие сведения об отечественных комплексных средствах защиты информации, имеющих сертификаты и соответствующих государственным стандартам.
Международное признание для защиты передаваемых сообщений получила программная система PGP (Pretty Good Privacy — очень высокая секретность), разработанная в США и объединяющая асимметричные и симметричные шифры. Являясь самой популярной программной криптосистемой в мире, PGP реализована для множества операционных сред — MS DOS, Windows 95, Windows NT, OS/2, UNIX, Linux, Mac OS, Amiga, Atari и др.
5.4. CASE-ТЕХНОЛОГИИ
На данный момент в технологии разработки программного обеспечения существуют два основных подхода к разработке информационных систем, отличающиеся критериями декомпозиции:
функционально-модульный (структурный) и объектно-ориентированный.
Функционально-модульный подход основан на принципе алгоритмической декомпозиции с выделением функциональных элементов и установлением строгого порядка выполняемых действий.
Объектно-ориентированный подход основан на объектной декомпозиции с описанием поведения системы в терминах взаимодействия объектов.
Главным недостатком функционально-модульного подхода является однонаправленность информационных потоков и недостаточная обратная связь. В случае изменения требований к системе это приводит к полному перепроектированию, поэтому ошибки, заложенные на ранних этапах, сильно сказываются на продолжительности и стоимости разработки. Другой важной проблемой является неоднородность информационных ресурсов, используемых в большинстве информационных систем. В силу этих причин в на-
стоящее время наибольшее распространение получил объектно-ориентированный подход.
Под CASE-технологиеи будем понимать комплекс программных средств, поддерживающих процессы создания и сопровождения программного обеспечения, включая анализ и формулировку требований, проектирование, генерацию кода, тестирование, документирование, обеспечение качества, конфигурационное управление и управление проектом (CASE-средство может обеспечивать поддержку только в заданных функциональных областях или в широком диапазоне функциональных областей) [5].
В связи с наличием двух подходов к проектированию программного обеспечения существуют CASE-технологии ориентированные на структурный подход, объектно-ориентированный подход, а также комбинированные. Однако сейчас наблюдается тенденция переориентации инструментальных средств, созданных для структурных методов разработки, на объектно-ориентированные методы, что объясняется следующими причинами:
• возможностью сборки программной системы из готовых компонентов, которые можно использовать повторно;
• возможностью накопления проектных решений в виде библиотек классов на основе механизмов наследования;
• простотой внесения изменений в проекты за счет инкапсуляции данных в объектах;
• быстрой адаптацией приложений к изменяющимся условиям за счет использования свойств наследования и полиформизма;
• возможностью организации параллельной работы аналитиков, проектировщиков и программистов.
Рассмотренные ранее (см. подразд. 3.1) концепции объектно-ориентированного подхода и распределенных вычислений стали базой для создания консорциума Object Management Group (OMG), членами которой являются более 500 ведущих компьютерных компаний (Sun, DEC, IBM, HP, Motorola и др.). Основным направлением деятельности консорциума является разработка спецификаций и стандартов для создания распределенных объектных систем в разнородных средах. Базисом стали спецификации под названием Object Management Architecture (ОМА).
ОМА состоит из четырех основных компонентов, представляющих спецификации различных уровней поддержки приложений (рис. 5.10):
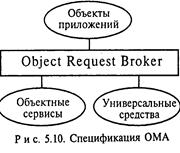 |
• архитектура брокера запросов объектов (CORBA — Common Object Request Broker Architecture) определяет механизмы взаимодействия объектов в разнородной ceти;
• объектные сервисы (Object Services) являются основными системными сервисами, используемыми разработчиками для создания приложений;
• универсальные средства (Common Facilities) являются высокоуровневыми системными сервисами, ориентированными на поддержку пользовательских приложений (электронная почта, средства печати и др.);
• прикладные объекты (Application Object) предназначены для решения конкретных прикладных задач.
Исходя из основных положений объектно-ориентированного подхода рассмотрим концепцию идеального объектно-ориентированного CASE-средства.
Существует несколько объектно-ориентированных методов, авторами наиболее распространенных из них являются Г.Буч, Д.Рамбо, И.Джекобсон. В настоящее время наблюдается процесс сближения объектно-ориентированных методов. В частности, указанные выше авторы создали и выпустили несколько версий унифицированного метода UML (Unified Modeling Language — унифициванный язык моделирования).
Классическая постановка задачи разработки программной системы (инжиниринг) представляет собой спиральный цикл итерактианого чередования этапов объектно-ориентированного анализа, проектирования и реализации (программирования).
В реальной практике в большинстве случаев имеется предыстория в виде совокупности разработанных и внедренных программ, которые целесообразно использовать при разработке новой системы. Процесс проектирования в таком случае основан на реинжиниринге программных кодов, при котором путем анализа текстов программ восстанавливается исходная модель программной системы.
Современные CASE-средства поддерживают процессы инжиниринга и автоматизированного реинжиниринга.
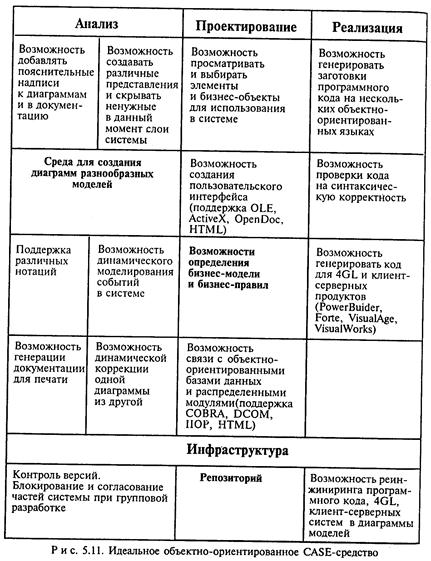
Идеальное объектно-ориентированное CASE-средство (рис. 5.11) должно содержать четьфе основных блока: анализ, проектирование, разработка и инфраструктура [34].
Основные требования к блоку анализа:
• возможность выбора выводимой на экран информации из всей совокупности данных, описывающих модели;
• согласованность диаграмм при хранении их в депозитарии;
• внесение комментариев в диаграммы и соответствующую документацию для фиксации проектных решений;
• возможность динамического моделирования в терминах событий;
• поддержка нескольких нотаций (хотя бы три нотации — Г.Буча, И.Джекобсона и ОМТ).
Основные требования к блоку проектирования:
• поддержка всего процесса проектирования приложения;
• возможность работы с библиотеками, средствами поиска и выбора;
• возможность разработки пользовательского интерфейса;
• поддержка стандартов OLE, ActiveX и доступ к библиотекам HTML или Java;
• поддержка разработки распределенных или двух- и трехзвенных клиент-серверных систем (работа с CORBA, DCOM, Internet). Основные требования к блоку реализации:
• генерация кода полностью из диаграмм;
• возможность доработки приложений в клиент-серверных CASE-средствах типа Power Builder;
• реинжиниринг кодов и внесение соответствующих изменений в модель системы;
• наличие средств контроля, которые позволяют выявлять несоответствие между диаграммами и генерируемыми кодами и обнаруживать ошибки как на стадии проектирования, так и на стадии реализации. Основные требования к блоку инфраструктуры:
• наличие репозитория на основе базы данных, отвечающего за генерацию кода, реинжиниринг, отображение кода на диаграммах, а также обеспечивающего соответствие между моделями и программными кодами;
• обеспечение командной работы (многопользовательской работы и управление версиями) и реинжиниринга.
В табл. 5.3 приведен обзор наиболее распространенных объектно-ориентированных CASE-средств [34].
Сравнительный анализ CASE-систем показывает, что на сегодняшний день одним из наиболее приближенных к идеальному варианту CASE-средств является семейство Rational Rose фирмы Rational Software Corporation. Следует отметить, что именно здесь работают авторы унифицированного языка моделирования Г. Буч, Д. Рамбо и И. Джекобсон, под руководством которых ведется разработка нового CASE-средства, поддерживающего UML.
5.5. ТЕЛЕКОММУНИКАЦИОННЫЕ ТЕХНОЛОГИИ
По мере эволюции вычислительных систем сформировались следующие разновидности архитектуры компьютерных сетей:
• классическая архитектура «клиент—сервер»;
• архитектура «клиент—сервер» на основе Web-технологии. При одноранговой архитектуре (рис. 5.12) все ресурсы вычислительной системы, включая информацию, сконцентрированы в центральной ЭВМ, называемой еще мэйнфреймом (main frame — центральный блок ЭВМ). В качестве основных средств доступа к информационным ресурсам использовались однотипные алфавитно-цифровые терминалы, соединяемые с центральной ЭВМ кабелем. При этом не требовалось никаких специальных действий со стороны пользователя по настройке и конфигурированию программного обеспечения.
Явные недостатки, свойственные одноранговой архитектуре и развитие инструментальных средств привели к появлению вычислительных систем с архитектурой «клиент—сервер». Особенность данного класса систем состоит в децентрализации архитектуры автономных вычислительных систем и их объединении в глобальные компьютерные сети. Создание данного класса систем связано с появлением персональных компьютеров, взявших
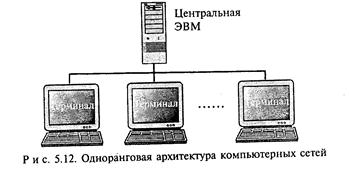
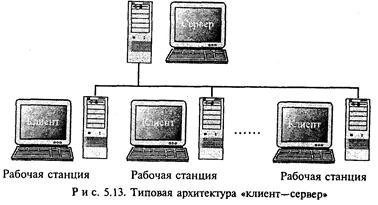
на себя часть функций центральных ЭВМ. В результате появилась возможность создания глобальных и локальных вычислительных сетей, объединяющих персональные компьютеры (клиенты или рабочие станции), использующие ресурсы, и компьютеры (серверы), предоставляющие те или иные ресурсы для общего использования. На рис. 5.13 представлена типовая архитектура «клиент—сервер», однако различают несколько моделей, отличающихся распределением компонентов программного обеспечения между компьютерами сети.
Любое программное приложение можно представить в виде структуры из трех компонентов:
• компонент представления, реализующий интерфейс с пользователем;
• прикладной компонент, обеспечивающий выполнение прикладных функций;
• компонент доступа к информационным ресурсам, или менеджер ресурсов, выполняющий накопление информации и управление данными.
На основе распределения перечисленных компонентов между рабочей станцией и сервером сети выделяют следующие модели архитектуры «клиент—сервер»:
• модель доступа к удаленным данным;
• модель сервера управления данными;
• модель комплексного сервера;
• трехзвенная архитектура «клиент—сервер».
Модель доступа к удаленным данным (рис. 5.14), при которой на сервере расположены только данные, имеет следующие особенности:
• невысокая производительность, так как вся информация обрабатывается на рабочих станциях;
• снижение общей скорости обмена при передаче больших объемов информации для обработки с сервера на рабочие станции.
При использовании модели сервера управления данными (рис. 5.15) кроме самой информации на сервере располагается менеджер информационных ресурсов (например, система управления базами данных). Компонент представления и прикладной компонент совмещены и выполняются на компьютере-клиенте, который поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается либо операторами специального языка (например, SQL в случае использования базы данных), либо вызовами функций специализированных программных библиотек. Запросы к информационным ресурсам направляются по сети менеджеру ресурсов (например, серверу базы данных), который обрабатывает запросы и возвращает клиенту блоки данных. Наиболее существенные особенности данной модели:
• уменьшение объемов информации, передаваемых по сети, так как выборка необходимых информационных элементов осуществляется на сервере, а не на рабочих станциях;
• унификация и широкий выбор средств создания приложений;
• отсутствие четкого разграничения между компонентом представления и прикладным компонентом, что затрудняет совершенствование вычислительной системы.
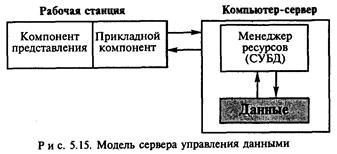
Модель сервера управления данными целесообразно использовать в случае обработки умеренных, не увеличивающихся со временем объемов информации. При этом сложность прикладного компонента должна быть невысокой.
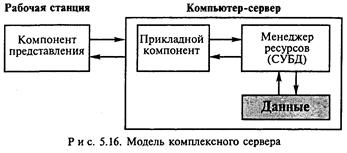
Модель комплексного сервера (рис. 5.16) строится в предположении, что процесс, выполняемый на компьютере-клиенте, ограничивается функциями представления, а собственно прикладные функции и функции доступа к данным выполняются сервером.
Преимущества модели комплексного сервера:
• высокая производительность;
• централизованное администрирование;
• экономия ресурсов сети.
Модель комплексного сервера является оптимальной для крупных сетей, ориентированных на обработку больших и увеличивающихся со временем объемов информации.
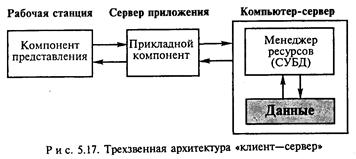
Архитектура «клиент—сервер», при которой прикладной компонент расположен на рабочей станции вместе с компонентом представления (модели доступа к удаленным данным и сервера управления данными) или на сервере вместе с менеджером ресурсов и данными (модель комплексного сервера), называют двухзвенной архитектурой.
При существенном усложнении и увеличении ресурсоемкости прикладного компонента для него может быть выделен отдельный сервер, называемый сервером приложений. В этом случае говорят о трезвенной архитектуре «клиент—сервер» (рис. 5. 17). Первое звено — компьютер—клиент, второе — сервер приложений, третье — сервер управления данными. В рамках сервера приложений могут быть реализованы несколько прикладных функций, каждая из которых оформляется как отдельная служба, предоставляющая некоторые услуги всем программам. Серверов приложения может быть несколько, каждый из них ориентирован на предоставление некоторого набора услуг.
Наиболее ярко современные тенденции телекоммуникационных технологий проявились в Интернете. Архитектура «клиент-сервер», основанная на Web-технологии Представлена на рис. 5. 18.
В соответствии с Web-технологией на сервере размещаются так называемые Web-документы, которые визуализируются и интерпретируются программой навигации (Web-навигатор, Web-броузер), функционирующей на рабочей станции. Логически Web-документ представляет собой гипермедийный документ, объединяющий ссылками различные Web-страницы. В отличие от бумажной Web-страница может быть связана с компьютерными программами и содержать ссылки на другие объекты. В Web-технологии существует система гиперссылок, включающая ссылки на следующие объекты:
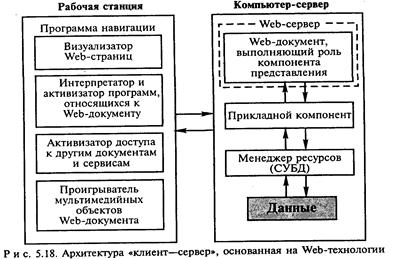 125
125
• другую часть Web-документа;
• другой Web-документ или документ другого формата (например, документ Word или Excel), размещаемый на любом компьютере сети;
• мультимедийный объект (рисунок, звук, видео);
• программу, которая при переходе на нее по ссылке, будет передана с сервера на рабочую станцию для интерпретации или запуска на выполнение навигатором;
• любой другой сервис — электронную почту, копирование файлов с другого компьютера сети, поиск информации и т.д.
Передачу с сервера на рабочую станцию документов и других объектов по запросам, поступающим от навигатора, обеспечивает функционирующая на сервере программа, называемая Web-сервером. Когда Web-навигатору необходимо получить документы или другие объекты от Web-сервера, он отправляет серверу соответствующий запрос. При достаточных правах доступа между сервером и навигатором устанавливается логическое соединение. Далее сервер обрабатывает запрос, передает Web-навигатору результаты обработки и разрывает установленное соединение. Таким образом, Web-сервер выступает в качестве информационного концентратора, который доставляет информацию из разных источников, а потом в однородном виде предоставляет ее пользователю.
Дальнейшим развитием Интернета явилась Интернет-технология, рассмотренная в подразд. 6.1.
Интернет — бурно разросшаяся совокупность компьютерных сетей, опутывающих земной шар, связывающих правительственные, военные, образовательные и коммерческие институты, а также отдельных граждан.
Как и многие другие великие идеи, «сеть сетей» возникла из проекта, который предназначался совершенно для других целей: из сети ARPAnet, разработанной и созданной в 1969 г. по заказу Агентства передовых исследовательских проектов (ARPA — Advanced Research Project Agency) Министерства обороны США. ARPAnet была сетью, объединяющей учебные заведения, военных и военных подрядчиков; она была создана для помощи исследователям в обмене информацией, а также (что было одной из главных целей) для изучения проблемы поддерживания связи в случае ядерного нападения.
В модели ARPAnet между компьютером-источником и компьютером-адресатом всегда существует связь. Сама сеть считается ненадежной; любой ее отрезок может в любой момент исчезнуть (по-
еле бомбежки или в результате неисправности кабеля). Сеть была построена так, чтобы потребность в информации от компьютеров-клиентов была минимальной. Для пересылки сообщения по сети компьютер должен был просто помещать данные в конверт, называемый «пакетом межсетевого протокола» (IP, Internet Protocol), правильно «адресовать» такие пакеты. Взаимодействующие между собой компьютеры (а не только сама сеть) также несли ответственность за обеспечение передачи данных. Основополагающий принцип заключался в том, что каждый компьютер в сети мог общаться в качестве узла с любым другим компьютером с широким выбором компьютерных услуг, ресурсов, информации. Комплекс сетевых соглашений и общедоступных инструментов «сети сетей» разработан с целью создания одной большой сети, в которой компьютеры, соединенные воедино, взаимодействуют, имея множество различных программных и аппаратных платформ.
В настоящее время направление развития Интернета в основном определяет «Общество Internet», или ISOC (Internet Society). ISOC — это организация на общественных началах, целью которой является содействие глобальному информационному обмену через Интернет. Она назначает совет старейшин IAB (Internet Architecture Board), который отвечает за техническое руководство и ориентацию Интернета (в основном это стандартизация и адресация в Интернете). Пользователи Интернета выражают свои мнения на заседаниях инженерной комиссии IETF (Internet Engineering Task Force). IETF — еще один общественный орган, он собирается регулярно для обсуждения текущих технических и организационных проблем Интернета.
Финансовая основа Интернета заключается в том, что каждый платит за свою часть. Представители отдельных сетей собираются и решают, как соединяться и как финансировать эти взаимные соединения. Учебное заведение или коммерческое объединение платит за подключение к региональной сети, которая, в свою очередь, платит за доступ к Интернету поставщику на уровне государства. Таким образом, каждое подключение к Интернету кем-то оплачивается.
на предыдущую просмотренную, поставить закладку. В этом заключается основное преимущество WWW. Пользователя не интересует, как организовано и где находится огромное структурированное хранилище данных. Графическое представление подключения различных серверов представляет собой сложную невидимую электронную паутину.
Серверы Web — специальные компьютеры, осуществляющие хранение страниц с информацией и обработку запросов от других машин. Пользователь, попадая на какой-нибудь сервер Web, получает страницу с данными. На компьютере пользователя специальная программа (броузер) преобразует полученный документ в удобный для просмотра и чтения вид, отображаемый на экране. Серверы Web устанавливаются, как правило, в фирмах и организациях, желающих распространить свою информацию среди многих пользователей, и отличаются специфичностью информации. Организация и сопровождение собственного сервера требует значительных затрат. Поэтому в WWW встречаются «разделяемые» (shared) серверы, на которых публикуют свои данные различные пользователи и организации. Это самый дешевый способ опубликования своей информации для обозрения. Такие серверы зачастую представляют своеобразные информационные свалки.
Серверы FTP представляют собой хранилища различных файлов и программ в виде архивов. На этих серверах может находиться как полезная информация (дешевые условно бесплатные утилиты, программы, картинки), так и информация сомнительного характера, например порнографическая.
Электронная почта является неотъемлемой частью Интернета и одной из самых полезных вещей. С ее помощью можно посылать и получать любую корреспонденцию (письма, статьи, деловые бумаги и др.). Время пересылки зависит от объема, обычно занимает минуты, иногда часы. Каждый абонент электронной почты имеет свой уникальный адрес. Надо отметить, что подключение к электронной почте может быть организовано и без подключения к Интернету. Необходимый интерфейс пользователя реализуется с помощью браузера, который, получив от него запрос с Интернет-адресом, преобразовывает его в электронный формат и посылает на определенный сервер. В случае корректности запроса, он достигает WEB-сервера, и последний посылает пользователю в ответ информацию, хранящуюся по заданному адресу. Браузер, получив информацию, делает ее читабельной и отображает на экране. Современные браузеры имеют также встроенную программу для электронной почты.
Среди наиболее распространенных браузеров необходимо выделить Microsoft Internet Explorer и Netscape Navigator.
Подсоединение к Интернету для каждого конкретного пользователя может быть реализовано различными способами: от полного подсоединения по локальной вычислительной сети (ЛВС) до доступа к другому компьютеру для работы с разделением и использованием программного пакета эмуляции терминала.
Фактически выход в Интернет может быть реализован несколькими видами подключений:
• доступ по выделенному каналу;
• доступ по ISDN (Integrated Services Digital Network — цифровая сеть с интегрированными услугами);
• доступ по коммутируемым линиям;
• с использованием протоколов SLIP и РРР.
Корпорациям и большим организациям лучше всего использовать доступ по выделенному каналу. В этом случае возможно наиболее полно использовать все средства Интернета. Поставщик сетевых услуг при этом сдает в аренду выделенную телефонную линию с указанной скоростью передачи и устанавливает специальный компьютер-маршрутизатор для приема и передачи сообщений от телекоммуникационного узла организации. Это дорогостоящее подключение. Однако, установив такое соединение, каждый компьютер ЛВС-организации является полноценным членом Интернета и может выполнять любую сетевую функцию.
ISDN — это использование цифровой телефонной линии, соединяющей домашний компьютер или офис с коммутатором телефонной компании. Преимущество ISDN — в возможности доступа с очень высокими скоростями при относительно низкой стоимости. При этом по Интернету предоставляется такой же сервис, как и по коммутируемым линиям. Услуги телефонных компаний, предоставляющих сервис ISDN, доступны не на всей территории России.
Наиболее простои и дешевый способ получения доступа к сети (Dial — up Access) осуществляется по коммутируемым линиям. В этом случае пользователь приобретает права доступа к компьютеру, который подсоединен к Интернету (хост-компьютеру или узлу Интернета). Войдя по телефонной линии (при этом используется модем и программное обеспечение для работы в коммутируемом режиме) с помощью эмулятора терминала в удаленную систему, необходимо в ней зарегистрироваться и далее уже можно пользоваться всеми ресурсами Интернета, предоставленными удаленной системе. Пользователь в таком режиме арендует дисковое пространство и вычислительные ресурсы удаленной системы. Если требуется сохранить важное сообщение электронной почты или другие данные, то это можно сделать в удаленной системе, но не на диске пользовательского компьютера: сначала нужно записать файл на диск удаленной системы, а затем с помощью программы передачи данных перенести этот файл на свой компьютер. При таком доступе пользователь не может работать с прикладными программами, для которых нужен графический дисплей, так как в такой конфигурации с компьютера, подсоединенного к Интернету, нет возможности передать графическую информацию на компьютер пользователя.
При дополнительных финансовых затратах и в коммутируемом режиме можно получить полный доступ к Интернету. Это достигается применением протоколов SLIP и РРР. Один называется «межсетевой протокол последовательного канала» (Serial Line Internet Protocol — SLIP), а другой — «протокол точка — точка» (Point-to-Point Protocol — РРР). Одно из главных достоинств SLIP и РРР состоит в том, что они обеспечивают полноценное соединение с Интерне-том. Пользовательский компьютер не использует какую-то систему как «точку доступа», а непосредственно подключается к Интернету. Но для подключения средних и больших сетей к Интернету эти протоколы не подходят, поскольку их быстродействия недостаточно для одновременной связи со многими пользователями.
Современные сети создаются по многоуровневому принципу. Передача сообщений в виде последовательности двоичных сигналов начинается на уровне линий связи и аппаратуры, причем линий связи не всегда высокого качества. Затем добавляется уровень базового программного обеспечения, управляющего работой аппаратуры. Следующий уровень программного обеспечения позволяет наделить базовые программные средства дополнительными необходимыми возможностями. Расширение необходимых функциональных возможностей сети путем добавления уровня за уровнем при-
водит к тому, что пользователь в конце концов получает по-настоящему дружественный и полезный инструментарий.
Моделью Интернета можно считать почтовое ведомство, представляющее собой сеть с коммутацией пакетов. Там корреспонденция конкретного пользователя смешивается с другими письмами, отправляется в ближайшее почтовое отделение, где сортируется и направляется в другие почтовые отделения до тех пор пока не достигнет адресата.
Для передачи данных в Интернете используются интернет-про-токол (IP) и протокол управления передачей (TCP).
С помощью интернет-протокола (IP) обеспечивается доставка данных из одного пункта в другой. Различные участки Интернета связываются с помощью системы компьютеров (называемых маршрутизаторами), соединяющих между собой сети. Это могут быть сети Ethernet, сети с маркерным доступом, телефонные линии. Правила, по которым информация переходит из одной сети в другую, называются протоколами. Межсетевой протокол (Internet Protocol — IP) отвечает за адресацию, т.е. гарантирует, что маршрутизатор знает, что делать с данными пользователя, когда они поступят. Некоторая адресная информация приводится в начале каждого пользовательского сообщения. Она дает сети достаточно сведений для доставки пакета данных, так как каждый компьютер в Интернете имеет свой уникальный адрес.
Для более надежной передачи больших объемов информации служит протокол управления передачей (Transmission Control Protocol — TCP). Информация, которую пользователь хочет передать, TCP разбивает на порции. Каждая порция нумеруется, подсчитывается ее контрольная сумма, чтобы можно было на приемной стороне проверить, вся ли информация получена правильно, а также расположить данные в правильном порядке. На каждую порцию добавляется информация протокола IP, таким образом получается пакет данных в Интернете, составленный по правилам TCP/IP.
По мере развития Интернета и увеличения числа компьютерных узлов, сортирующих информацию, в сети была разработана доменная система имен — DNS, и способ адресации по доменному принципу. DNS иногда еще называют региональной системой наименований.
Доменная система имен — это метод назначения имен путем передачи сетевым группам ответственности за их подмножество. Каждый уровень этой системы называется доменом. Домены в именах отделяются друг от друга точками: inr.msk.ru. В имени мо-
жет быть различное число доменов, но практически — не больше пяти. По мере движения по доменам слева направо в имени, число имен, входящих в соответствующую группу возрастает.
Все компьютеры Интернета способны пользоваться доменной системой. Работающий в сети компьютер всегда знает свой собственный сетевой адрес. Когда используется доменное имя, например mx.ihep.ru, компьютер преобразовывает его в числовой адрес. Для этого он начинает запрашивать помощь у DNS-серверов. Это узлы, рабочие машины, обладающие соответствующей базой данных, в число обязанностей которых входит обслуживание такого рода запросов. DNS-сервер начинает обработку имени с его правого конца и двигается по нему влево, т.е. сначала осуществляет поиск адреса в с