 2015-05-13
2015-05-13 981
981Электронные компьютеры с хранимыми программами были разработаны в 1940-х и начале 1950-х годов для выполнения научных и численных вычислений. Примерно в то же время компания Univac разработала аппаратуру магнитных лент, каждая из которых могла хранить столько информации, сколько десять тысяч перфокарт. Поставка в 1951 году Univac1 в бюро переписей отразилась на разработке устройств с перфокартами. Очередная перепись населения показала работоспособность новой технологии и ее перспективность. Эти новые компьютеры могли обрабатывать сотни записей в секунду, и их можно было разместить на гораздо меньшей площади, чем предыдущее оборудование.
Ключевым компонентом этой новой технологии было программное обеспечение.
Начали появляться стандартные пакеты для таких общеупотребительных бизнес-приложений, как общая бухгалтерия, расчет заработной платы, ведение инвентарных ведомостей, управление подпиской, банковская деятельность и ведение библиотек документов.
Реакция на появление этих новых технологий была предсказуемой. В крупном бизнесе сохраняли еще больше информации и требовали все более и более быстрого оборудования.
Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Типичные программы последовательно читали несколько входных файлов и производили на выходе новый файлы.
Системы пакетной обработки транзакций сохраняли транзакции на картах или лентах и собирали их в пакеты для последующей обработки. Раз в день эти пакеты транзакций сортировались. Отсортированные транзакции сливались с хранимой на ленте намного большей по размерам базой данных (основным файлом) для производства нового основного файла. На основе этого основного файла также производился отчет, который использовался как гроссбух на следующий бизнес-день. Пакетная обработка позволяла очень эффективно использовать компьютеры, но обладала двумя серьезными ограничениями. Если в транзакции имелась ошибка, она не распознавалась до вечерней обработки основного файла, и могло потребоваться несколько дней для исправления транзакции. Более важным является то, что бизнес не знал текущего состояния баз данных, поскольку транзакции реально не обрабатывались до следующего утра. Для решения этих двух проблем требовался следующий шаг эволюции – оперативные системы. Этот шаг также существенно облегчил написание приложений.
До появления СУБД все данные, которые содержались в компьютерной системе постоянно, хранились в виде отдельных файлов. Система управления файлами, которая обычно является частью операционной системы компьютера, следила за именами файлов и местами их расположения. В системах управления файлами модели данных, как правило, не использовались; эти системы ничего не знали о внутреннем содержимом файлов. Для такой системы файл, содержащий документ текстового процессора, ничем не отличается от файла, содержащего данные о начисленной зарплате.
Знание о содержимом файла – какие данные в нем хранятся и какова их структура – было уделом прикладных программ, использующих этот файл, что иллюстрирует рис.5.1. В приложении для начисления зарплаты каждая из программ, обрабатывающих файл с информацией о служащих, содержит в себе описание структуры данных (ОСД), хранящихся в этом файле. Когда структура данных изменялась – необходимо было модифицировать каждую из программ, обращавшихся к файлу. Со временем количество файлов и программ росло, и на сопровождение существующих приложений приходилось затрачивать все больше и больше усилий, что замедляло разработку новых приложений.
Проблемы сопровождения больших систем, основанных на файлах, привели в конце 60-х годов к появлению СУБД. В основе СУБД лежала простая идея: изъять из программ определение структуры содержимого файла и хранить ее вместе с данными в базе данных.
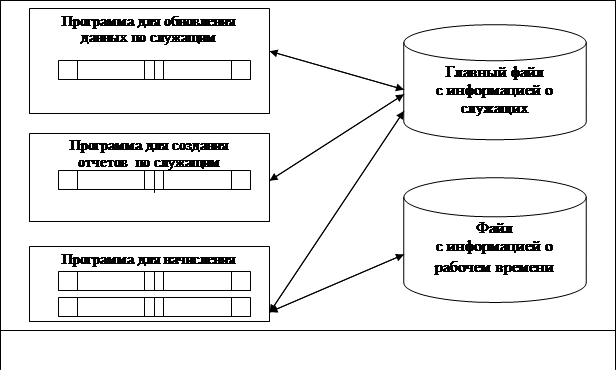 |
Приложение для начисления зарплаты, использующее систему управления файлами
 |
Рис.5.1. Приложение для начисления зарплаты.








