2015-10-16
2015-10-16 1397
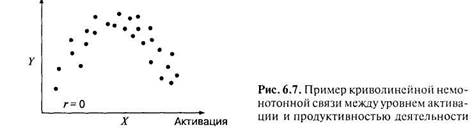
1397Наиболее типичный пример — это связь тревожности и результатов тестирования, или в общем случае — связь уровня активации (X) и продуктивности деятельности (Y). Связь таких переменных напоминает перевернутую (инвертированную) U (рис. 6.7). Любой из рассмотренных коэффициентов корреляции будет в этом случае иметь значение, близкое к нулю.
Продуктивность
Если наблюдается немонотонная нелинейность связи, то можно поступить двояко. В первом случае сначала надо найти точку перегиба по графику рассеивания и разделить выборку на две группы, различающиеся направлением связи между переменными. После этого можно вычислять корреляции отдельно для каждой группы. Второй способ предполагает отказ от применения коэффициентов корреляции. Необходимо ввести дополнительную номинативную переменную, которая делит исследуемую выборку на контрастные группы по одной из переменных. Далее можно изучать различия между этими группами по уровню выраженности (например, по средним значениям) другой переменной.
В приведенном примере (рис. 6.7) можно по переменной «активация» выделить 3 группы (низкий, средний и высокий уровень) и далее изучать различия между этими группами по продуктивности деятельности.
КАКОЙ КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ ВЫБРАТЬ
При изучении связей между переменными наиболее предпочтительным является случай применения r-Пирсона непосредственно к исходным данным. В любом случае, обнаружена корреляция или нет, необходим визуальный ана-
ГЛАВА 6. КОЭФФИЦИЕНТЫ КОРРЕЛЯЦИИ
лиз графиков распределения переменных и графика двумерного рассеивания, если исследователя действительно интересует связь между соответствующими переменными. Применяя /•-Пирсона, необходимо убедиться, что: П обе переменные не имеют выраженной асимметрии;
□ отсутствуют выбросы;
□ связь между переменными прямолинейная.
Если хотя бы одно из условий не выполняется, можно попытаться применить ранговые коэффициенты корреляции: r-Спирмена или х-Кендалла. Но и ранговые корреляции имеют свои ограничения. Они применимы, если:
□ обе переменные представлены в количественной шкале (метрической
или ранговой);
□ связь между переменными является монотонной (не меняет свой знак с
изменением величины одной из переменных).
Применение ранговых коэффициентов корреляции при расчете «вручную» требует предварительного ранжирования переменных. Если при этом встречаются одинаковые значения признаков (связи в рангах), применяется формула r-Пирсона для предварительно ранжированных переменных (в случае с r-Спирмена) либо вводятся поправки на связанные ранги (в случае с т-Кен-далла).
Если есть предположение, что корреляция обусловлена влиянием третьей переменной, и все три переменные допускают применение r-Пирсона для вычисления корреляции между ними, возможна проверка этого предположения путем вычисления коэффициента частной корреляции этих переменных (при фиксированных значениях третьей переменной). Если значение частной корреляции двух переменных по абсолютной величине заметно меньше, чем их парная корреляция, то парная корреляция обусловлена влиянием третьей переменной.
Применяя коэффициенты корреляции, особое внимание следует уделять графикам двумерного рассеивания. Они позволяют выявить случаи, когда корреляция обусловлена неоднородностью выборки по той и другой переменной. Кроме того, эти графики позволяют определить характер связи: ее линейность и монотонность. Если связь является криволинейной и не монотонной (например, имеет форму U), то коэффициенты корреляции не подходят. 13 этом случае можно разделить выборку на группы по одной из переменных, для сравнения этих групп по выраженности другой переменной.
Если обе переменные представлены в бинарной шкале (0,1), для изучения связи между ними можно применять ф-коэффициент сопряженности, если для каждой переменной количество 0 и 1 приблизительно одинаковое.
Во всех случаях, когда исследователя интересует связь между переменными, а коэффициенты корреляции для этого не подходят, изучение этой связи возможно при помощи сравнения групп, выделяемых по одной из переменных. Если другая переменная метрическая или ранговая, то группы сравниваются по уровню ее выраженности, если номинативная — то по ее распределению.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
ОБРАБОТКА НА КОМПЬЮТЕРЕ
1. Графики двумерного рассеивания. Выбираем Graphs... > Scatter... > Simple.
Нажимаем Define. В появляющемся окне назначаем осям переменные: выде
ляем слева одну переменную, нажимаем > напротив «X Axis» (Ось X), выделя
ем другую переменную, нажимаем > напротив «Y Axis». Нажимаем ОК. По
лучаем график рассеивания назначенных переменных.
2. Вычисление парных корреляций. Выбираем Analyze > Correlate > Bivariate...
В открывшемся окне диалога переносим интересующие переменные из ле
вой части в правую при помощи кнопки > (переменных должно быть как
минимум две). По умолчанию стоит флажок «Pearson» (корреляция г-Пирсо-
на). Если интересует корреляция r-Спирмена или т-Кендалла, необходимо
поставить соответствующие флажки внизу. Нажимаем ОК. В появившейся
таблице строки и столбцы соответствуют выделенным ранее переменным.
В ячейке на пересечении строки и столбца, соответствующих интересующим
нас переменным, видим три числа: верхнее соответствует коэффициенту кор
реляции, нижнее — численности выборки N, среднее — уровню значимости.
3. Вычисление частной корреляции. Выбираем Analyze > Correlate > Partial...
В открывшемся окне диалога переносим интересующие переменные из ле
вой части в правое верхнее окно (Variables:) при помощи верхней кнопки >
(переменных должно быть как минимум две). Затем при помощи нижней
кнопки > из левой части в правое нижнее окно (Controlling for:) переносим
переменную, значения которой хотим фиксировать. Нажимаем ОК. Получа
ем таблицу, аналогичную таблице парных корреляций, но верхнее число в
каждой ячейке — значение частной корреляции соответствующих двух пере
менных при фиксированном значении указанной третьей переменной. Ниж
нее число — уровень значимости, а посередине — число степеней свободы.