 2014-02-24
2014-02-24 3536
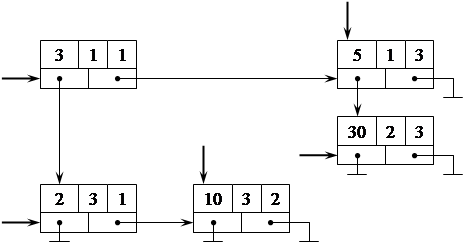
3536Рис. 38. Исключение узла, на который предварительно установлен указатель
Предварительно установлен указатель
Исключение из списка узла, на который
Исключение узла, на который предварительно установлен указатель, не требует поиска предыдущего узла (рис. 38). После исключения узла из списка и возвращения его элемента хранения в кучу, доступ к этому узлу по предварительно установленному указателю более невозможен, поэтому данному указателю следует присвоить значение NIL.

| Procedure Del_Double(head: PDlist; | { head – указатель на “голову” списка } | |||
| var p: PDlist); | { p – указатель на исключаемый узел } | |||
| begin | ||||
| if (head <> nil) and (head^.next <> head) | { список не пуст и указатель p } | |||
| and (head^.prev <> head) and (p <> nil) then | { установлен? } | |||
| begin | ||||
| p^.prev^.next:=p^.next; | { изменить поле связи предыдущего узла } | |||
| p^.next^.prev:=p^.prev; | { изменить поле связи следующего узла } | |||
| dispose(p); p:=nil | { элемент хранения исключаемого узла вернуть в кучу } | |||
| end; | ||||
| end; | ||||
Операция поиска узла в двусвязном циклическом списке и операция разрушения выполняются так же, как в односвязном циклическом списке, только проход возможен в любом из двух направлений: с использованием атрибута связи next (т.е. “вперед”) или с использованием атрибута связи prev (т.е. “назад”).
Двусвязные циклические списки, как и односвязные, можно использовать для реализации разнообразных линейных структур.
Ортогональный список (или мультисписок) – это структура, каждый элемент которой входит более чем в один список одновременно и имеет соответствующее числу списков количество полей связи. Реализация каждого из списков может быть выполнена как одно- или двусвязного нециклического или циклического. Технология обработки мультисписков ничем не отличается от обработки обычных списков, но так как мультисписок одновременно содержит несколько списков, каждую операцию следует выполнить отдельно для каждого списка.
Ортогональный список позволяет на множестве одних и тех же атрибутов, содержащих информацию, организовать различные списки, упорядоченные по различным признакам. Рассмотрим список студентов, каждый узел которого содержит следующие информационные поля: фамилия_ имя_отчество, средний балл, дата рождения, адрес, номер зачетки и т.п. Пусть необходимо упорядочить список студентов по двум признакам: в алфавитном порядке по фамилии и в соответствии со средним баллом. Этого можно достичь, если построить два отдельных списка, но элементы хранения информационных полей в этом случае продублируются, что приведет к неэффективному использованию оперативной памяти, особенно, если количество информационных полей велико. Более рациональным решением является использование мультисписка, содержащего два списка, каждый из которых организован, например, в виде двусвязного циклического списка: по алфавиту элементы списка упорядочены с помощью атрибутов связи fnext и fprev, а по среднему баллу те же самые элементы упорядочены с помощью атрибутов связи bnext и bprev. Для удобства обработки мультисписок содержит головной элемент, на который установлен указатель. Структура мультисписка студентов представлена на рис. 39.

Рис. 39. Структура мультисписка студентов
Описание элемента хранения мультисписка студентов:
| Type | ||||
| Str30 = String[30]; | { тип для описания фамилии_имени_отчества } | |||
| PMulty_List: ^ Multy_List; | { тип – указатель на узел мультисписка } | |||
| Multy_List = record | { описание элемента хранения узла мультисписка} | |||
| fam: Str30; | { фамилия_имя_отчество } | |||
| ball: real; | { средний балл } | |||
| ... | ||||
| fnext, fprev: PMulty; | { атрибуты связи в списке по фамилии } | |||
| bnext, bprev: PMulty; | { атрибуты связи в списке по среднему баллу } | |||
| end; | ||||
| Var head: PMulty; | { указатель на “голову” мультисписка } | |||
Пример обработки мультисписка – процедуры, распечатывающие содержимое узлов в виде списка, упорядоченного по алфавиту, и в виде списка, упорядоченного по среднему баллу.
| Procedure Print_Fam(head: PMulty); | { распечатка мультисписка, } |
| Var p: PMulty; | { упорядоченного по алфавиту } |
| begin | |
| if (head <> nil) then begin | { список существует? } |
| p:=head^.fnext; | { установить вспомогательный указатель } |
| while (p <> head) do begin | { весь список пройден? } |
| writeln(p^.fam, p^.ball); | { распечатать информационные поля } |
| p:=p^.fnext | { перейти к следующему узлу } |
| end; | |
| end; | |
| end; |
| Procedure Print_Ball(head: PMulty); | { распечатка мультисписка, } |
| Var p: PMulty; | { упорядоченного по среднему баллу } |
| begin | |
| if (head <> nil) then begin | { список существует? } |
| p:=head^.bnext; | { установить вспомогательный указатель } |
| while (p <> head) do begin | { весь список пройден? } |
| writeln(p^.fam, p^.ball); | { распечатать информационные поля } |
| p:=p^.bnext | { перейти к следующему узлу } |
| end; | |
| end; | |
| end; |
Часто в виде ортогональных списков представляются матрицы очень большой размерности, в которых большинство элементов равны нулю (такие матрицы называются разреженными). Пример разреженной матрицы
Мультисписки обеспечивают эффективное хранение таких структур в памяти – хранятся только те элементы, которые отличны от нуля (рис. 40). Каждый элемент входит в два списка – в список-строку и в список-столбец. Вся матрица представляется (m + n) списками, где m и n соответственно число строк и число столбцов. Каждый элемент мультисписка хранит значение элемента матрицы, номер строки, номер столбца и две ссылки – на следующий элемент в строке и на следующий элемент в столбце (если используются односвязные списки). Указатели на начала этих списков хранятся в двух массивах.
 |








