 2014-02-10
2014-02-10 339
339Задачу определения среднего количества детей у людей различных рас можно решить еще одним способом. Вкратце этот способ будет выглядеть так. Выберем только людей белой расы. Вычислим для них среднее количество детей. Затем выберем только негров и повторим вычисления. И так далее.
Этот способ использует операцию выбора наблюдений, о которой сейчас и пойдет речь. Раздел выбора наблюдений вызывается следующим образом:
Данные à Отобрать наблюдения (в русской версии)
Data à Select Cases. (в английской версии)
Появляется окно, в котором следует отметить один из вариантов выбора, а также указать параметры для этого варианта:
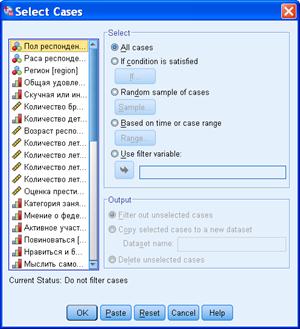
По умолчанию отмечен вариант без селекции: «Все наблюдения» или «All cases».
Второй пункт – «Если выполнено условие…» (If condition is satisfied) - выбор наблюдений, удовлетворяющих некоторому условию. Условие представляет собой логическое выражение, которое может быть либо истинным, либо нет. Утверждение «возраст>40 лет» - пример такого выражения. Притом для одних людей это выражение будет истинно, а для других – ложно.
Логическое выражение по виду может напоминать уравнение или неравенство. Причем в него, скорее всего, будут входить наименования переменных. Проверка истинности утверждения производится с подставленными конкретными значениями указанных переменных. На иллюстрации утверждение выглядит так: Race = 1.
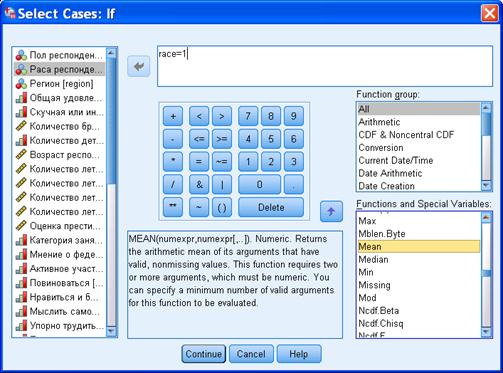
В логическое выражение кроме чисел и знаков арифметических действий могут входить функции. Полный перечень функций расположен в верхнем правом углу. При нажатии названия функции в правом нижнем углу появляются сведения о функциях.
При выборе респондентов изменяется внешний вид базы данных. Номера наблюдений, которые для анализа не были выбраны, будут перечеркнуты.
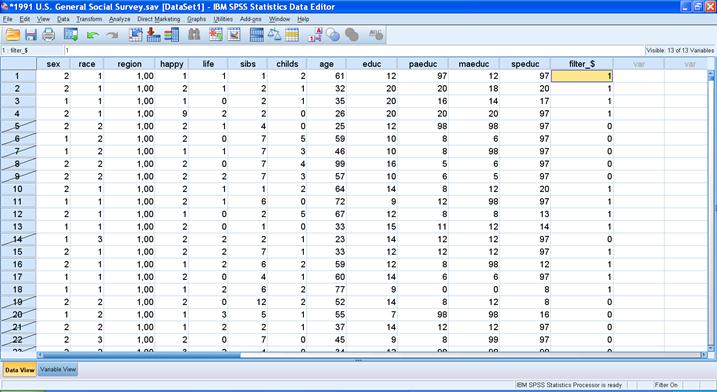
Одновременно при включении выбора респондентов появится «фильтровая» переменная под названием
Filter_$. Эта переменная состоит только из нулей и единиц, причем единицы стоят у отобранных респондентов, а нули – у тех, кто в анализе принимать участие не будет.
Фильтровую переменную можно создать и самостоятельно, любым способом, вплоть до набора ее вручную. При включении селекции останется только указать ее имя, выбрав в процедуре селекции наблюдений раздел «Использовать фильтрующую перемнную» (Use filter variable). Фильтровая переменная должна быть устроена так же, как и в своей «автоматической» версии. Те строки (респонденты), которые должны быть включены в обработку, должны иметь значение этой переменной, равное 1. Остальные (исключаемые) строки – значение 0.
Следующий вариант отбора наблюдений проводится с использованием генератора случайных чисел.
Random sample of cases – определенный % анкет будет выбран случайным образом.

Имеются два варианта выбора:
1) Approximately _____% of all cases – позиция для указания этого процента.
2) Exactly __A___ cases from first ___В____ cases – …
Этот вариант означает, что из первых А анкет случайным образом компьютер выберет В наблюдений.
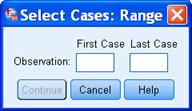
При анализе данных редко, но встречается ситуация, когда не все анкеты равноправны. Такая ситуация называется Time series – временным рядом. При этом может потребоваться включить в анализ только респондентов с определенными порядковыми номерами. Тогда можно в процедуре отбора наблюдений выбрать пункт «Временной диапазон или диапазон наблюдений» (Based on time or case range) и указать точно, с какой анкеты по какую будем анализировать:
В правом нижнем углу окна отбора наблюдений (select cases) возможно выбрать один из трех вариантов того, как компьютеру следует поступить с теми наблюдениями, которые анализировать не планируется. По умолчанию SPSS предлагает самый безопасный вариант: фильтрацию. Именно этот вариант и описан ранее. Ненужные строки данных остаются в файле, просто они исключаются из анализа до тех пор, пока мы не включим их снова, изменив условия выбора.
Есть еще один вариант, также безопасный: выбранные наблюдения поместить в новый набор данных. По-английски это звучит «copy selected cases to a new dataset». Следует указать название нового набора данных. С этим набором будет можно работать как с новым файлом, и даже сохранить его как новый файл, если он понадобится в дальнейшей работе. Однако, имейте в виду, что до сохранения этот набор будет только в виртуальной памяти, и выключение компьютера пориведет к его потере.
Наконец, редко, но все же случается ситуация, когда не выбранные строки нам больше не потребуются. Для этого случая есть вариант, когда не выбранные анкеты удаляются из файла («delete unselected cases»). Этот вариант можно использовать только с очень большой осторожностью, поскольку можно потерять данные. Конечно, если Вы имеете резервную копию исходного файла, ничего ужасного не произойдет, тем не менее, я студентам и начинающим пользователям SPSS рекомендую всячески избегать данный вариант работы.








