 2015-01-30
2015-01-30 898
898В модели парной линейной регрессии зависимость между переменными в генеральной совокупности представляется в виде
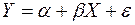
где X — неслучайная величина, а Y и e — случайные величины.
Величина Y называется объясняемой (зависимой) переменной, а X — объясняющей (независимой) переменной. Постоянные a, b — параметры уравнения.
Наличие случайного члена e (ошибки регрессии) связано с воздействием на зависимую переменную других неучтенных в уравнении факторов, с возможной нелинейностью модели и ошибками измерения.
На основе выборочного наблюдения оценивается выборочное уравнение регрессии (линия регрессии):
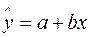
где (а, b) — оценки параметров (a, b).
Коэффициенты a и b вычисляются по формулам:
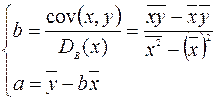
Для вычисления этих коэффициентов можно воспользоваться функциями Excel:
коэффициент a вычисляется с помощью функции ОТРЕЗОК(изв_значение_y; изв_значение_x);
коэффициент b вычисляется с помощью функции НАКЛОН(изв_значение_y; изв_значение_x).
Линия регрессии (расчетное значение зависимой переменной) имеет вид:
или 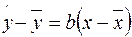
Линия регрессии проходит через точку 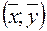 и выполняются равенства:
и выполняются равенства: 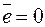 ,
, 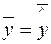 .
.
Коэффициент b есть угловой коэффициент регрессии,он показывает, на сколько единиц в среднем изменяется переменная y при увеличении независимой переменной х на единицу. Постоянная a дает прогнозируемое значение зависимой переменной при x = 0. Это может иметь смысл в зависимости от того, как далеко находится x = 0 от выборочных значений x.
После построения уравнения регрессии наблюдаемые значения y можно представить как 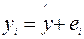 , где остатки ei, как и ошибки ei, являются случайными величинами, однако они, в отличие от ошибок ei, наблюдаемы.
, где остатки ei, как и ошибки ei, являются случайными величинами, однако они, в отличие от ошибок ei, наблюдаемы.
Выборочные дисперсии величин y, 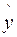 , e вычисляются по формулам:
, e вычисляются по формулам:
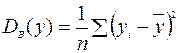 ¾ дисперсия наблюдаемых значений y;
¾ дисперсия наблюдаемых значений y;
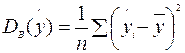 ¾ дисперсия расчетных значений y;
¾ дисперсия расчетных значений y;
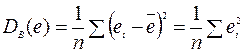 ¾ дисперсия остатков.
¾ дисперсия остатков.








