 2015-04-30
2015-04-30 1106
1106Обработчик Свёртка столбцов, как и Кросс-таблица, служит для преобразования исходной структуры набора данных в форму удобную для обработки. Но в отличие от Кросс-диаграммы которая формирует из выбранного поля данных несколько новых полей со значениями, сформированными на основе заданных фактов. Свёртка столбцов наоборот собирает все обозначенные поля в одно. В Deductor Studio такую возможность предоставляет инструмент Свёртка столбцов.
Обработчик предназначен для изменения структуры таблицы, а именно, перенесения заголовков полей в значения строк и столбцов.
ПРИМЕР
Пусть есть таблица с объемами продаж некоторых товаров за три месяца.
| Группа | Товар | Январь | Февраль | Март |
| Группа 1 | Товар 1 | |||
| Группа 1 | Товар 2 | |||
| Группа 1 | Товар 3 | |||
| Группа 2 | Товар 1 | |||
| Группа 2 | Товар 4 |
Применим к исходному набору данных обработчик Свёртка столбцов.
На этапе настройки назначения полей зададим следующие параметры:
– Информационные поля – Группа и Товар. Поля, помещенные в этот узел, не будут изменяться.
– Транспонируемые поля -Январь, Февраль и Март. Из значений полей, помещенных в этот узел, будут сформированы два новых столбца один со списком из меток, другой со списком значений. Транспонируемые столбцы должны быть одного типа.
Результат преобразования исходной таблицы представлен ниже (рис.
2.38).
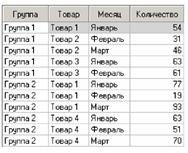
Рисунок 2.38 – Результат обработки
Свёртка столбцов
1) Рассмотрим алгоритм использования обработчика Свёртка столбцов на примере данных файла region_servise.txt, который необходимо импортировать в новом проекте.
В нем содержаться данные по объему предоставляемых платных услуг, выраженных в млн. руб. с 1995 по 2006 г. населению. Рассмотренные данные понадобятся аналитику для прогнозирования развития рынка услуг и отслеживания его динамики (рис. 2.39).
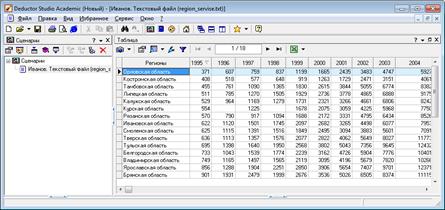
Рисунок 2.39 – Исходные данные
Необходимо преобразовать исходную таблицу, в такой вид чтобы она содержала данные по объему предоставляемых услуг в одном столбце.
Воспользуемся обработчиком Свёртка столбцов. (Для поля 2007 исправить тип поля на вещественный и разделитель дробной части – на точку).
2) Преобразование исходной таблицы данных.
Выберем обработчик Свёртка-столбцов (рис. 2.40). из окна Мастер обработки. Наша задача заключается в создании столбца фактов – Объем предоставляемых платных услуг населению и столбца измерения – Год, где будут храниться рассматриваемые годы.
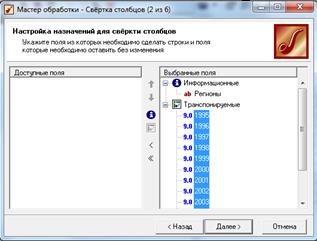
Рисунок 2.40 – Настройка назначений для свёртки столбцов
В появившемся окне Мастера обработки произведем настройку полей, переместим Регионы в информационные, а все рассматриваемые годы – в транспонируемые. Поля, которые переместились в информационные, изменению не подлежат, а транспонируемые поля объединяются в одно с помощью слияния их значений.
3) На следующем шаге задаем название новым полям.
В Поле меток транспонируемых столбцов, которое будет содержать перечисление рассматриваемых лет, присвоим значения: имя – Year и метка Год (рис. 2.41).
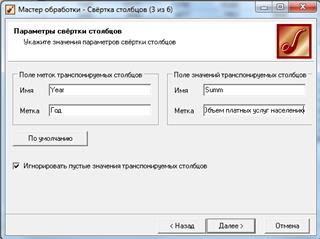
Рисунок 2.41 – Значения параметров
В Поле значений транспонируемых столбцов, содержащее данные по объему предоставляемых платных услуг населению по годам, присвоим имя Summ и метку Объем платных услуг населению.
Имеется возможность восстановить значения по умолчанию нажатием соответствующей кнопки.
После нажатия кнопки Далее запустим процесс на обработку.
4) На последнем шаге Мастера выберем для просмотра результата визуализатор Таблица (рис. 2.42).
Рисунок 2.42 – Результат применения визуализатора Таблица
Установим флажок в поле Игнорировать пустые значения транспонированных полей, в соответствии с чем пустые значения транспонированных полей будут исключаться из рассматриваемого набора данных.
Результаты сохранить в файле L2_6.ded.
Вопросы для проверки
1. Какую нужно задать глубину погружения в узле Скользящее окно, если в модели планируется использовать первый и пятый предыдущий месяцы, а горизонт прогнозирования уже задан равным 1?
2. Поля какого типа пригодны для обработки в узле Дата и время?
3. Какие варианты группировки имеются в Deductor Studio?
4. Для чего предназначена разгруппировка?
5. Вы импортировали набор данных и хотите сделать разгруппировку по некоторому полю, однако в списке доступных обработчиков узел Разгруппировка отсутствует. В чем наиболее вероятная причина этого?
6. Для чего может задаваться оценка распределения данных в разгруппировке?
7. Какие типы слияний реализованы в обработчике Слияние?
8. Что такое «поля связи»?
9. Как сделать слияние, если связываемая таблица находится в текстовом файле?
10. Можно ли в Deductor Studio настроить неравномерное квантование по полю?
11. Можно ли изменять автоматически рассчитанные границы интервалов квантования?
12. В каких случаях может понадобиться обработка данных при помощи узлов Кросс-таблица и Свёртка столбцов?
13. Где настраивается нормализация и схемы кодирования в Deductor Studio?
14. Что такое нормализатор Уникальные значения?
15. Как для столбца задать двоичное кодирование компактным кодом?
16. Как по умолчанию нормализуются непрерывные выходы (если аналитический алгоритм требует нормализации)?








