 2015-06-05
2015-06-05 5178
51784й семестр – лекции 34 часа, лабораторные работы 32 часа – экзамен;
5й семестр – лекции 34 часа, лабораторные работы 16 час – зачёт.
Литература.
1. Хусаинов Б.С. «Структуры и алгоритмы обработки данных. Примеры на языке Си» М: Финансы и статистика, 2004.
2. Вирт Н. «Алгоритмы и структуры данных», СПб: Невский диалект, 2001.
3. Ахо А., Хопкрофт Джон, Ульман Джеффри «Структуры данных и алгоритмы», М: Издательский дом «Вильямс», 2000.
4. Кнут Д. Искусство программирования. В трёх томах. М.: Издательский дом «Вильямс», 2001.
5. Кормен Т. и др. Алгоритмы: Построение и анализ, 2-е издание. М.: Издат. Дом «Вильямс». 2005.
Алгоритмы
Алгоритмом решения задачи называют конечную последовательность действий, которые надо выполнить над входными данными и промежуточными результатами для получения результата решения задачи.
Алгоритм должен обладать следующими свойствами:
1. Конечность – работа алгоритма должна заканчиваться за конечное число шагов, причём некоторые из шагов могут повторяться многократно.
2. Определённость (детерминированность) – все шаги алгоритма должны иметь однозначную трактовку и должны быть понятны исполнителю алгоритма, при одних и тех же исходных данных должны быть получены одни и те же результаты.
3. Массовость – алгоритм должен быть направлен на решение целого класса задач, отличающихся исходными данными.
4. Результативность – алгоритм должен приводить к достижению поставленной цели за конечное число шагов.
5. Эффективность – все шаги алгоритма должны выполняться за конечное время, а общее время решения задачи должно лежать в допустимых пределах.
Основными этапами подготовки задачи к решению на компьютере являются:
1. Постановка задачи – на этом этапе необходимо точно сформулировать и понять задачу, установить, имеет ли она решение; нельзя ли её решить с помощью готовых прикладных программ.
2. Построение модели задачи – предполагает подбор или разработку формального описания (модели) задачи, привлекая достижения современной науки.
3. Разработка алгоритма – в рамках построенной модели задачи разрабатываются или подбираются методы и алгоритмы её решения. При этом необходимо выяснить, существуют ли решения аналогичных задач, то есть руководствоваться накопленным опытом, что значительно сокращает сроки разработки, и, следовательно, снижает расходы.
4. Реализация алгоритма в виде программы – сначала выбирается язык программирования.
5. Проверка правильности алгоритма – выполняется на различных этапах. На этапе разработки алгоритма доказывается правильность каждого шага алгоритма, затем доказывается конечность алгоритма, проверяются допустимые входные данные и полученные по ним выходные данные. На этапе программной реализации необходимо следить за тем, чтобы в процессе преобразования правильного алгоритма получить правильную программу.
Правильностью (корректностью) программы называют свойство программы, характеризующее отсутствие в ней ошибок по отношению к целям разработки.
Каждая программа определяется правилами её представления (синтаксисом языка программирования) и правилами интерпретации её содержательного значения (семантикой). Корректная программа может быть создана только при строгом соотношении этих правил. Задача определения синтаксической правильности решается транслятором автоматически в ходе трансляции программы. Проблема доказательства семантической правильности оказывается значительно сложнее, так как процедура доказательства существенно зависит от решаемой задачи и исходных данных. Формализованное описание поставленной задачи называют спецификацией задачи. Область науки, занимающаяся доказательством соответствия между программной реализацией и спецификацией задачи, получила название верификации программ. Цель верификации программ – демонстрация их корректности.
Семантическая правильность программы проверяется путём её тестирования, то есть выполнения программы при определённых исходных данных (тестах) с целью нахождения ошибок.
6. Анализ сложности алгоритма: алгоритму решения задачи предъявляют два противоречивых требования:
а) быть простым для понимания, отладки и сопровождения;
б) быть эффективным в смысле затрат времени и памяти компьютера.
Какому из этих требований отдать предпочтение, определяется характером решаемой задачи.
При анализе с задачей связываются некоторое число, называемое размером задачи n, которое выражает меру количества (объёма) исходных данных. В качестве размера могут выступать размеры массивов, число вершин или дуг графа, число записей в файле и т.п. Время выполнения программы T зависит от n. Традиционно определяют время выполнения T(n) в наихудшем случае как меру сложности алгоритма – это так называемая временная сложность.
Типы данных
Данные характеризуются тремя качествами: семантикой, синтаксисом и прагматикой.
Семантика – это содержательная (смысловая) характеристика данных. Она определяет множество возможных значений данных и множество операций, которые можно выполнять над этими данными.
Синтаксис – это формальная характеристика данных, определяющая внешний вид (структуру) данных. Синтаксис основан на стандартах языка программирования и задаётся грамматикой, которая включает алфавит и синтаксические правила изображения данных.
Прагматика – характеристика, определяющая правила использования данных в компьютере в результате интерпретации данных, то есть прагматика данных – это алгоритмы их обработки в компьютере.
Комбинацию семантической и синтаксической характеристик данных в программировании называют типом данных. В современных языках программирования типы данных делятся на простые (скалярные) и структурированные.
Данные простых (скалярных) типов рассматриваются как цельные простые неделимые объекты. Например: целые, вещественные, символьный, логический и другие.
Данные структурированных типов представляются как составные агрегатные объекты, элементы которых могут быть данными одного и того же типа (в этом случае этот тип называется базовым) или различных типов.
Число различных значений, входящих в тип, называется мощностью этого типа.
Если для значений некоторого типа существует отношение порядка следования, то такой тип называется порядковым.
Абстрактный тип данных (АТД) – это комбинация всех трёх характеристик данных: семантической, синтаксической и прагматической, то есть это математическая модель данных с совокупностью операций, определённых в рамках этой модели. АТД представляются с помощью конкретного языка программирования в виде определённых синтаксических конструкций.
Структуры данных
Структурой данных называют совокупность элементов данных, между которыми существуют некоторые отношения, причём элементами данных могут быть как один элемент (атомарные данные), так и структуры. Все связи одного элемента данных с другими образуют элемент отношений, связанных с соответствующим элементом данных. Пару, содержащую элемент данных и элемент отношений, назовём элементом структуры.

Рис. 1. Структура данных.
На основе фундаментальных структур в программе могут строиться более сложные структуры.
Таким образом, структура данных – это организованная некоторым образом информация, которая может быть описана, создана и обработана программами.
Структура данных используется для представления абстрактного типа данных.
Существуют линейные и нелинейные структуры данных. В линейных структурах между элементами имеется отношение соседства. К линейным структурам относятся массивы, очереди, стеки, деки, линейные списки. К нелинейным структурам данных относятся графы, деревья и леса.
Структуры хранения данных
Представление определённой структуры данных в памяти компьютера называется структурой хранения данных. Одной и той же структуре данных могут соответствовать различные структуры хранения, и, наоборот, разные структуры данных могут быть представлены одной и той же структурой хранения. Структура хранения, выбранная для представления конкретной структуры данных, должна, с одной стороны, сохранить отношения, существующие между элементами данных, с другой стороны, обеспечивать наиболее простое и эффективное выполнение операций над структурой данных в целом и отдельными её элементами. Такими операциями являются создание и уничтожение структуры данных, включение и исключение её элементов, доступ к элементам и т.п.
Большинство современных вычислительных машин имеет линейную оперативную память, состоящую из последовательности ячеек памяти. Ячейка – это наименьшая адресуемая часть памяти. Возможные значения адресов образуют адресное пространство модели вычислительной машины (0,1,2,…,n). По содержимому ячейки невозможно определить, какого типа данные в ней хранятся.
Для представления адреса в языках программирования имеется особый тип данных, называемый указателем. Возможными значениями данных типа «указатель» является всё адресное пространство компьютера. Указатель содержит адрес другого объекта программы, может содержать также адрес любой ячейки памяти компьютера. Если переменная содержит адрес некоторого другого объекта, то говорят, что переменная указывает (ссылается) на этот объект. Указатель может ссылаться на любой объект программы: простую переменную, массив, строку, структуру, функцию, другой указатель.
Рассмотрим возможности представления структур данных в линейной оперативной памяти.
Первая возможность связана с получением памяти. Данные могут размещаться либо в статической, либо в динамической памяти. Память под данные в программе может быть получена двумя способами. Первый способ – это когда для отдельных данных, которые описаны в программе, при её выполнении выделяется память, определяемая типом данных. Такая память является статической и сохраняется на время выполнения программы или её частей. (Не путать со статическими данными в языке Си и других языках программирования.) Второй способ – это получение памяти по явному запросу в программе. В запросе указывается объём требуемой памяти. В случае наличия памяти операционная система выделяет одну сплошную область памяти и возвращает адрес начала этой области. Такую память будем называть динамической памятью. За её правильное использование отвечает программист. После того как потребность в динамической памяти отпала, она может быть освобождена также по явному запросу. Динамическая память может быть получена для структуры данных в целом по одному запросу. Тогда размеры структуры данных могут изменяться только в пределах фиксированной длины полученной памяти, а число элементов в структуре будет ограничено. Если же получать память для каждого элемента по отдельному запросу, число элементов не ограничивается, пока есть доступная память вычислительной машины.
Вторая возможность определяется тем, является ли обязательным совместное размещение всех элементов многоэлементной структуры в одной сплошной области памяти либо допускается размещение отдельных элементов в различных областях памяти.
Третья возможность возникает, когда отдельные элементы многоэлементной структуры данных не имеют явных связей между собой и размещаются в одной сплошной области памяти последовательно, друг за другом.
Четвёртая возможность учитывается в том случае, когда между отдельными элементами многоэлементной структуры данных существуют явные связи по размещению их в памяти, и элементы структуры размещаются либо в одной сплошной области, либо в различных областях.
Используя различные допустимые сочетания этих возможностей, можно образовать различные структуры хранения данных.
Рассмотрим три вида структур хранения данных: вектор, список и сеть, на основе которых строятся многие другие структуры хранения.
1. Вектор
Вектор является наиболее простой структурой хранения многоэлементных структур данных. Он размещается в одной сплошной области памяти. Элементы структуры данных в векторе физически размещаются последовательно один за другим. Поэтому в элементе структуры данных для вектора имеется только элемент данных и отсутствует элемент отношений, показывающий связи элемента структуры данных с другими элементами.
Такая структура хранения наиболее близко соответствует реальной организации памяти большинства ЭВМ. Все элементы структуры данных имеют одинаковую длину. Доступ к отдельному элементу осуществляется с использованием базового адреса (адреса начала) вектора и номера этого элемента. Обычно в векторной памяти размещаются массивы (одномерные и многомерные), строки, стеки, очереди, таблицы и т.п.
Для манипулирования со структурой данных, хранимой в векторе, требуется управляющая информация, определяющая адрес начала вектора, тип элементов структуры данных и их количество в векторе и т.п. Для хранения управляющей информации создаётся дескриптор (описатель) вектора или информационный вектор.
Таким образом, структура вектора состоит из двух частей: дескриптора и непосредственно вектора, в котором последовательно размещаются элементы структуры данных (рис. 2).

Рис. 2. Структура вектора.
Дескриптор вектора содержит: адрес Am начала вектора, тип элементов структуры данных или их длину L, число элементов или их начальный m и конечный n индексы. Адрес Ai элемента Ei с индексом i определяется выражением Ai = Am + (i - m) * L.
В большинстве случаев отображение структур данных в структуры хранения в виде вектора можно выполнить, используя такой тип данных, как «массив». При этом транслятор создаёт как дескриптор вектора, так и сам вектор, а обращение к элементам вектора сводится к обращению к элементам массива. Однако транслятор создаёт статический массив с фиксированными размерами, что может явиться ограничивающим фактором его применения.
В прикладной программе можно организовать хранение данных в динамическом векторе. Для этого нужно выполнить ряд операций: 1) определить структуру дескриптора; 2) получить динамическую память под дескриптор и заполнить дескриптор управляющей информацией; 3) используя данные из дескриптора, определить размер памяти для вектора и получить динамическую память; 4) при необходимости инициализировать элементы структуры данных в векторе. Адреса элементов к ним вычисляются с использованием управляющей информации из дескриптора. В программе доступ к структуре данных, хранимой в виде вектора, осуществляется посредством указателя на дескриптор (рис. 3).

Рис. 3. Доступ к вектору через дескриптор.
Иногда вместо дескриптора используется только указатель на начало вектора. Тогда остальные параметры структуры данных (тип или длина элементов, число элементов и т.п.) должны быть известны каждой из процедур обработки структуры данных, что может усложнить их реализацию.
2. Список
Список является более сложной структурой хранения, в которой элементы имеют явные связи. В списке элементы структур данных размещаются не обязательно в смежных областях памяти. Каждый элемент структуры данных содержит, по крайней мере, два поля. Одно поле – основное содержит данные этого элемента или указатель на данные, а другое поле предназначено для размещения указателя на следующий элемент. Оконечный элемент структуры данных в поле указателя содержит признак конца списка (NULL – в Си, в Паскале - Nil). Элемент структуры данных, в свою очередь, тоже может быть структурой, хранимой в виде списка. Различают списки однонаправленные, двунаправленные и циклические. Число элементов списка может изменяться. Учитывая наличие явных связей между элементами списка, иногда используют термины цепной список или связной список. Список, отражающий отношение соседства между элементами (у каждого элемента списка могут быть только один предыдущий и один последующий элементы), называется линейным. Любой другой список называется нелинейным.
Однонаправленный список (рис. 4) является простейшей формой списка.

Рис. 4. Однонаправленный список.
Достоинства однонаправленного списка – простота создания, включения и удаления элементов. Недостаток – просмотр элементов осуществляется всегда с начала списка. Правда, программа обработки ожжет запоминать указатель на текущий элемент, тогда обработку можно продолжать с него.
Циклический список (рис. 5) отличается от однонаправленного только тем, что последний элемент в поле указателя содержит не признак конца списка, а ссылку на начало списка, т.е. на первый элемент, что позволяет перейти на другую операцию обработки элементов, начиная с любого элемента списка.

Рис. 5. Циклический список.
В двунаправленном списке каждый элемент содержит два указателя – на последующий и предыдущий элементы, что позволяет вести обработку элементов как в прямом, так и в обратном направлении.
Физически список реализуется как совокупность дескриптора списка и элементов, размещённых в оперативной памяти или на внешних запоминающих устройствах (ВЗУ) и связанных друг с другом в цепочку с помощь указателей. Дескриптор обычно реализуется в виде записи и может содержать следующую информацию о списке:
· тип структуры;
· имя списка;
· указатель (адрес) начала списка;
· текущее число элементов;
· описание элемента (длина, тип и т.п.).
Вместо дескриптора можно использовать только указатель.
Элементы структуры данных в списке могут быть как одинаковых, так и различных типов. Обработка элементов в первом случае проще, однако, иногда это приводит к излишним затратам памяти. Если данные существенно различаются по длине. Если данные различаются только по длине, то каждый элемент должен содержать информацию о своей длине. При различии по формату элементы снабжаются дескрипторами, определяющими формат и длину. Однако в этом случае выгоды от экономии памяти могут быть потеряны за счёт усложнения процедур обработки элементов.
Элементы структуры данных в списке могут быть упорядочены по возрастанию или убыванию значения некоторого поля данных (по ключу). Обработка упорядоченных списков во многих случаях проще обработки неупорядоченных списков.
Списки позволяют свободное размещение отдельных элементов структуры данных в различных областях динамической памяти, что обеспечивает более гибкое использование памяти ЭВМ. Тогда для включения в список нового элемента запрашивается динамическая память, а при удалении элемента из списка занятая им память освобождается. Это обеспечивает возможность гибкого использования памяти, но получение и освобождение памяти сопряжены с обращением к средствам управления памятью операционной системы и приводит к дополнительным затратам времени.
Возможна организация списка и в смежной области памяти. В этом случае все элементы структуры данных имеют один и тот же тип, а число возможных элементов ограничено размерами области памяти. На рис. 1.7 приведён пример цепного списка, размещённого в одной сплошной области памяти (указатель списка размещён в другой области и содержит адрес списка). Элементами данных являются буквы. Последовательность букв, размещённых в списке, образует слово АЗБУКА.
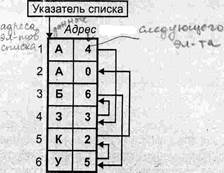
Рис. 1.7. Цепной список в смежной области памяти.
Если обработка списка предусматривает операции как включения, так и удаления элементов, то потребуются создание и ведение двух дополнительных списков: списка свободных и списка занятых элементов. Удаляемый элемент при этом включается в список свободных, а для включения элемента используется элемент из списка свободных, если таковые имеются. В качестве указателей в таких списках могут использоваться либо индексы элементов, либо их адреса.
3. Сеть
Сеть как структура хранения является дальнейшим развитием списковой структуры хранения. Каждый элемент структуры данных в сети, кроме данных, может содержать несколько указателей на другие элементы. На один и тот же элемент могут ссылаться несколько других элементов, образуя, таким образом, сложные переплетения по связи (рис. 1.8).
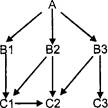
Рис. 1.8. Сеть.
В общем случае количество полей в элементах структуры данных в сети может быть различным, тогда элемент должен содержать информацию о своём формате. Вместо данных в элементе сети, как в списке, может располагаться ссылка на данные.
Сети используются для представления в памяти ЭВМ сложных структур данных, таких как графы, деревья, многоуровневые и многосвязные таблицы, структуры сложных программных изделий, организационные структуры предприятий и связи между ними и т.п.
Каждый элемент структуры данных в сети обычно размещается в динамически получаемой памяти, что обеспечивает гибкость представления и обработки данных. Сети могут быть организованы и в смежной области памяти фиксированной длины, если количество элементов и структура данных, представленная сетью, при решении задачи остаются неизменными.
Массивы
1. Структуры данных «массив»
Массивы являются наиболее широко используемыми структурами данных и предусмотрены во всех языках программирования. Массив состоит из элементов одного типа, называемого базовым, поэтому структура массива однородна. Базовый тип может быть как скалярным, так и структурированным, т.е. элементами массива могут быть числа, символы, строки, структуры, в том числе и массивы. Число элементов массива фиксировано, поэтому объём занимаемой массивом памяти остаётся неизменным. С каждым элементом массива связан один или несколько индексов. Они однозначно определяют место элемента в массиве и обеспечивают прямой доступ к нему. Индексы массива относятся к определённому порядковому типу, поэтому индексы можно вычислять. Это обеспечивает, с одной стороны, гибкость обработки элементов массива, с другой стороны, создаёт опасность выхода за пределы массива, если не предусмотрены соответствующие средства контроля.
В зависимости от числа индексов различают одномерные и многомерные массивы. Допустимое число индексов массива (размерность массива) и диапазоны изменения их значений устанавливаются языком программирования. Трансляторы с языка программирования могут уточнить эти значения. По стандарту языка Си размерность массива не может превышать 31, а нумерация индексов начинается всегда с нуля, т.е. индекс изменяется от 0 до n-1, где n – количество значений индекса (мощность индекса).
Областями применения массивов являются:
· числовые массивы в вычислительных задачах;
· матричная алгебра, экстраполяция, интерполяция;
· таблицы – массивы с элементами типа «запись»;
· управляющие и информационные таблицы в операционных системах, трансляторах, системах управления базами данных (СУБД);
· представление других структур: графов, деревьев.
2. Структуры хранения массивов
Массив в памяти хранится в виде вектора, т.е. все элементы размещаются в смежных участках памяти подряд, начиная с адреса, соответствующего началу массива. Элементы одномерного массива размещаются последовательно друг за другом a0, a1,…, an-1. Элементы двухмерного массива размещаются по строкам, т.е. наиболее быстро меняется последний индекс b0,0, b0,1,…, b0,n-1, b1,0, b1,1,…, b1,n-1,…, bm-1,n-1 (в Си, Паскале, ПЛ/1).
Вся информация, необходимая для управления массивом, задаётся при его описании в программе. Описание содержит имя массива, тип элементов, который однозначно определяет длину элемента, диапазоны изменения индексов или число значений индексов, если нижние границы индексов фиксированы. Таким образом, общее количество элементов массива и размер памяти для массива полностью определяются описанием массива. Транслятор выделяет необходимую память и строит управляющий блок массива – дескриптор, или информационный вектор, например, такого содержания (для одномерного массива):
· тип структуры;
· адрес начала массива Aн;
· тип элемента (длина элемента массива L);
· нижняя граница индекса iн;
· верхняя граница индекса iв.
В случае многомерного массива для каждого индекса задаются нижняя и верхняя границы или же для каждой строки (каждого индекса) создаётся свой дескриптор.
Этой информации достаточно как для доступа к элементам массива, так и для контроля над тем, чтобы значения индексов не выходили за установленные диапазоны. Доступ к любому i-тому элементу в одномерном массиве осуществляется по адресу:
Ai = Aн + (i - iн) * L.
То, что размеры массива, формируемого транслятором, фиксированы, может явиться ограничивающим фактором применения готовой программы. Действительно, требуется, чтобы память для массива выделялась в размерах, необходимых для решения конкретной задачи, а каковы будут её потребности, заранее может быть неизвестно. В таких ситуациях массив можно строить в динамической памяти, получаемой с помощью средств управления памятью операционной системы. Управление доступом к элементам таких массивов осуществляется самой программой по вычисляемым индексам (адресам) элементов с использованием указателя.

