 2015-06-24
2015-06-24 6212
6212Кодер речи является первым элементом собственно цифрового участка передающего тракта АЦП [43]. Основная задача кодера (английский термин encoder) – предельно возможное сжатие сигнала речи, представленного в цифровой форме, т.е. предельно возможное устранение избыточности речевого сигнала, но при сохранении приемлемого качества передачи речи. Компромисс между степенью сжатия и сохранением качества отыскивается экспериментально, а проблема получения высокой степени сжатия без чрезмерного снижения качества составляет основную трудность при разработке кодера. В приемном тракте перед ЦАП размещен декодер речи; задача декодера (английский термин decoder) – восстановление обычного цифрового сигнала речи (с присущей ему естественной избыточностью) по принятому кодированному сигналу. Сочетание кодера и декодера называют кодеком (английский термин – codec).
Прежде чем перейти к рассмотрению кодера речи, используемого в GSM, приведем некоторые общие сведения об основных методах кодирования.
Исторически [43] сложилось два направления кодирования речи: кодирование формы сигнала (waveform coding) и кодирование источника сигнала (source coding).
Первый метод основан на использовании статистических характеристик сигнала и практически не зависит от механизма формирования сигнала. Кодеры этого типа с самого начала обеспечивали высокое качество передачи речи (хорошую разборчивость и натуральность речи), но отличались меньшей по сравнению со вторым методом экономичностью. В методе кодирования формы сигнала используются три основных способа кодирования: импульсно-кодовая модуляция – ИКМ (английское наименование Pulse Code Modulation – PCM), дифференциальная ИКМ – ДИКМ (Differential PCM – DPCM) и дельта-модуляция – ДМ (Delta Modulation – DM).
Второй метод – кодирование источника сигнала, или кодирование параметров сигнала, первоначально основывался на данных о механизмах речеобразования, т.е. этот метод использовал своего рода модель голосового тракта и приводил к системам типа анализ-синтез, получившим название вокодерных систем, или вокодеров (vocoder – сокращение от voice coder, т.е. кодер голоса или кодер речи). Ранние вокодеры позволяли получать весьма низкую скорость передачи информации, но при характерном «синтетическом» качестве речи на выходе. Поэтому вокодерные методы долгое время оставались в основном областью приложения усилий исследователей и энтузиастов, не находя широкого практического применения.
Ситуация существенно изменилась с появлением метода линейного предсказания, предложенного в 1960-х годах и получившего мощное развитие в 1980-х годах на основе достижений микроэлектроники [4].
В настоящее время в системах подвижной связи получили распространение вокодерные методы на основе метода линейного предсказания. Суть кодирования речи на основе метода линейного предсказания (Linear Predictive Coding – LPC) заключается в том, что по линии связи передаются не параметры речевого сигнала, а параметры некоторого фильтра, в определенном смысле эквивалентного голосовому тракту, и параметры сигнала возбуждения этого фильтра. В качестве такого фильтра используется фильтр линейного предсказания. Задача кодирования на передающем конце линии связи заключается в оценке параметров фильтра и параметров сигнала возбуждения, а задача декодирования на приемном конце – в пропускании сигнала возбуждения через фильтр, на выходе которого получается восстановленный сигнал речи.
Метод линейного предсказания заключается в том, что очередной отсчет (выборка) речевого сигнала Sn с некоторой степенью точности предсказывается линейной комбинацией М предшествующих отсчетов:
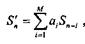
где аi – коэффициенты линейного предсказания; М — порядок предсказания. Разность между истинным Sn и предсказанным S 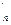 значениями отсчетов определяет ошибку предсказания (остаток предсказания):
значениями отсчетов определяет ошибку предсказания (остаток предсказания):
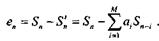
В результате z-преобразования этого разностного уравнения получаем
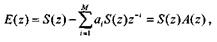
где функция A{z) интерпретируется как передаточная характеристика некоторого фильтра (инверсного фильтра или фильтра-анализатора), частотная характеристика которого обратна по отношению к частотной характеристике голосового тракта. При подаче речевого сигнала на вход инверсного фильтра на выходе фильтра получается сигнал возбуждения, подобный (с точностью до ошибок, определяемых конечностью порядка предсказания М и погрешностью оценки коэффициентов предсказания) сигналу возбуждения на входе фильтра голосового тракта.
Полученное выражение для A(z) соответствует структуре трансверсального фильтра, (рис. 3.1). Порядок предсказания выбирается из условия компромисса между качеством передачи речи и пропускной способностью линии связи, на практике М равно порядка 10.
Значения коэффициентов предсказания, постоянные на интервале кодируемого сегмента речи (на практике длительность сегмента составляет 20 мс), находятся из условия минимизации среднеквадратического значения остатка предсказания на интервале сегмента.
Для этого частные производные 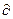 (
(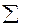 е
е 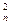 ) / ai, i =
) / ai, i = 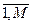 , приравниваются к нулю, что приводит к системе М линейных уравнений с М неизвестными коэффициентами аi. Матрица системы и метод ее решения оказываются несколько различными в зависимости от того, какими свойствами наделяется речевой сигнал на интервале преобразуемого сегмента речи. (Если речевой сигнал на этом интервале считается стационарным случайным процессор (автокорреляционный метод оценки коэффициентов предсказания), то матрица системы уравнений является Теплицевой и система решается с помощью итерационной процедуру алгоритма Дарбина, а фильтр-синтезатор получается заведомо устойчивым [43]. Если речевой сигнал считается нестационарным процессом (ковариационный метод оценки коэффициентов предсказания), то матрица системы симметрична, но не Теплицева, система решается с использованием разложения Холецкого, а для обеспечения устойчивости фильтра-синтезатора ковариационный метод соответствующим образом модифицируют [43].
, приравниваются к нулю, что приводит к системе М линейных уравнений с М неизвестными коэффициентами аi. Матрица системы и метод ее решения оказываются несколько различными в зависимости от того, какими свойствами наделяется речевой сигнал на интервале преобразуемого сегмента речи. (Если речевой сигнал на этом интервале считается стационарным случайным процессор (автокорреляционный метод оценки коэффициентов предсказания), то матрица системы уравнений является Теплицевой и система решается с помощью итерационной процедуру алгоритма Дарбина, а фильтр-синтезатор получается заведомо устойчивым [43]. Если речевой сигнал считается нестационарным процессом (ковариационный метод оценки коэффициентов предсказания), то матрица системы симметрична, но не Теплицева, система решается с использованием разложения Холецкого, а для обеспечения устойчивости фильтра-синтезатора ковариационный метод соответствующим образом модифицируют [43].
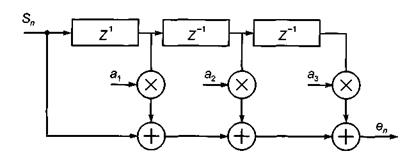
Рис. 3.1. Анализирующий трансверсальный фильтр при порядке предсказания М = 3
В обоих случаях (как в автокорреляционном методе, так и в ковариационном) в качестве побочного результата решения получаются значения так называемых коэффициентов отражения, или коэффициентов частичной корреляции (Partial Correlation Coefficients, или Parcor Coefficients ki, i= 1,..., M), число которых равно числу коэффициентов линейного предсказания ai, и которые связаны с коэффициентами аi, взаимно однозначными нелинейными функциональными соотношениями.
Коэффициенты отражения непосредственно связаны с другой формой фильтра линейного предсказания – так называемым решетчатым, или лестничным (Lattice) фильтром (рис. 3.2). Коэффициенты отражения к более удобны, чем коэффициенты линейного предсказания а для передачи по линии связи, так как в силу своих статистических характеристик в меньшей степени могут приводить к потере устойчивости фильтра при квантовании. Иначе говоря, они требуют меньшего числа разрядов при квантовании, т.е. приводят к более экономичному использованию линии связи [4]. Иногда используются также функции от коэффициентов отражения – логарифмические отношения площадей (Log-Area Ratio – LAR):
ri=log 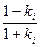
название которых связано с моделью голосового тракта в виде набора акустических труб различных сечений.
Передаточная характеристика фильтра-синтезатора H(z) обратна передаточной характеристике фильтра-анализатора A(z) с точностью до скалярного коэффициента усиления G:
H(z) = G/A{z).
Синтезирующий фильтр имеет ту же структуру, что и анализирующий (инверсный), и определяется тем же набором параметров (коэффициентов предсказания аi, или коэффициентов отражения ki, или логарифмических отношений площадей ri), но входы и выходы в анализирующем и синтезирующем фильтрах меняются местами. Если на вход синтезирующего фильтра подать сигнал возбуждения, то на его выходе будет получен речевой сигнал с тем качеством, которое обеспечивается фильтром при принятом порядке предсказания, используемом числе дискретов для квантования параметров фильтра и прочих ограничениях и погрешностях того же характера.
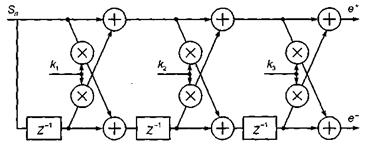
Рис. 3.2. Анализирующий решетчатый фильтр при порядке предсказания М = 3
Таким образом, процедура кодирования речи в методе линейного предсказания сводитсяся к следующему (рис. 3.3):
- оцифрованный сигнал речи нарезается на сегменты длительностью 20 мс (160 выборок по 8 разрядов в каждом сегменте);
- для каждого сегмента оцениваются параметры фильтра линейного предсказания и параметры сигнала возбуждения; в качестве сигнала возбуждения в простейшем случае может выступать остаток предсказания, получаемый при пропускании сегмента речи через фильтр линейного предсказания с параметрами, полученными из оценки для данного сегмента;
- параметры фильтра и параметры сигнала возбуждения кодируются по определенному закону и передаются в канал связи.
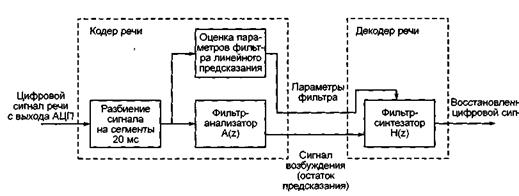
Рис. 3.3. Работа кодека речи в методе линейного предсказания
Процедура декодирования речи заключается в пропускании принятого сигнала возбуждения через синтезирующий фильтр известной структуры, параметры которого переданы одновременно с сигналом возбуждения. Приведенное описание процессов кодирования декодирования речи не является исчерпывающим, оно объясняет принцип действия кодека. Практические схемы заметно сложнее, и это связано в основном со следующими двумя моментами [43].
Во-первых, описанная схема линейного предсказания – кратковременное предсказание (Short-Term Prediction – STP) не обеспечивает достаточной степени устранения избыточности речи. Поэтому в дополнение к кратковременному предсказанию используется еще долговременное предсказание (Long-Term Prediction – LTP), в значительной мере устраняющее остаточную избыточность и приближающее остаток предсказания по своим статистическим характеристикам к белому шуму.
Во-вторых, использование остатка предсказания в качестве сигнала возбуждения оказывается недостаточно эффективным, так как требует для кодирования слишком большого числа разрядов. Поэтому практическое применение находят более экономичные (по загрузке канала связи, но не по вычислительным затратам) методы формирования сигнала возбуждения. В ранних кодеках линейного предсказания для формирования сигнала возбуждения передавались сигнал тон/шум (двоичный признак, указывающий, является ли передаваемый сегмент речи вокализованным, т.е. тональным, или невокализованным, т.е. шумовым), период основного тона и амплитуда сигнала.

