 2015-06-24
2015-06-24 1375
1375В начале 1980-х годов была предложена модель многоимпульсного возбуждения, не использующая классификацию сегментов речи по признаку вокализованный/невокализован-ный. С этой моделью связано значительное улучшение качества кодеков линейного предсказания, и в настоящее время используются исключительно различные варианты многоимпульсного возбуждения.
Остановимся на указанных двух моментах несколько подробнее. Передаточная характеристика инверсного фильтра долговременного предсказания имеет вид:
P(z) = l - 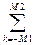 gk z
gk z 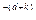
где gk – коэффициенты долговременного предсказания; порядок предсказания равен М1+М2+ 1, а временная задержка d соответствует периоду основного тона (для вокализованных звуков). Обычно долговременный предсказатель имеет порядок 1, т.е. М1 =М2 = 0, так что передаточная характеристика фильтра определяется единственным коэффициентом предсказания g и задержкой d:
P(z) = 1 – gz 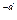 .
.
Если на вход инверсного фильтра долговременного предсказания подается остаток кратковременного предсказания е, то на выходе получается остаток (ошибка) долговременного предсказания fn, равный fn = еn – gen-d.
Ошибка fn весьма близка к белому гауссовскому шуму, что облегчает экономичное формирование параметров сигнала возбуждения. Параметры долговременного предсказания g и d могут быть определены, например, из условия минимизации среднеквадратического значения ошибки fn на некотором интервале, составляющем 20...25% от длительности передаваемого сегмента речи. Задержка d обычно заключается в пределах 20... 160 интервалов дискретизации сигнала, что соответствует диапазону частот основного тона 50...400 Гц. Передаточная характеристика R(z) долговременного фильтра-синтезатора обратна P(z) с точностью до скалярного коэффициента усиления F: R(z) = F/ P(z).
Сигнал возбуждения, аппроксимирующий (в смысле выхода фильтра-синтезатора) остаток долговременного предсказания fn, моделируется в виде определенного числа импульсов на интервале кадра возбуждения (Excitation Frame), составляющего обычно 20...50% от длительности передаваемого сегмента речи. Для оценки параметров последовательности импульсов сигнала возбуждения существует несколько методов [43, 58].
В методе многоимпульсного возбуждения (Multi-Pulse Excitation – МРЕ) оптимизируется как положение, так и амплитуды импульсов. В методе возбуждения регулярной последовательностью импульсов (Regular-Pulse Excitation – RPE) взаимное расположение импульсов предопределено заранее – используется сетка равноотстоящих импульсов, а оптимизируется расположение этой сетки в пределах кадра возбуждения (так как обычно число им- пульсов возбуждения в 3...4 раза меньше числа отсчетов в кадре) и амплитуды импульсов.
В методе стохастического кодирования, или методе линейного предсказания с кодовый возбуждением (Code-Excited Linear Prediction – CELP), с разновидностью возбуждени векторной суммой (Vector Sum Excited Linear Prediction – VSELP) наиболее подходящи вектор возбуждения выбирается из заранее составленной кодовой книги, или кодового словаря, содержащего обычно 2 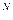 , N= 7... 10, квазислучайных векторов заданной длины с элементами, нормированными по амплитуде; амплитуда вектора возбуждения кодируется отдельно в соответствии с громкостью передаваемого элемента речи.
, N= 7... 10, квазислучайных векторов заданной длины с элементами, нормированными по амплитуде; амплитуда вектора возбуждения кодируется отдельно в соответствии с громкостью передаваемого элемента речи.
Наконец, известен эффективный метод возбуждения последовательностью бинарных импульсов с преобразованием (Transformed Binary Pulse Excitation – ТВРЕ), в котором сигналом возбуждения является последовательность равноотстоящих по времени и квазислучайных по знаку (с амплитудами ±1) импульсов, умноженных на некоторую матрицу npeoбразования.
В стандарте GSM используется метод RPE-LTP (Regular Pulse Excited Long Term Predictor – линейное предсказание с возбуждением регулярной последовательностью импульсов и долговременным предсказателем ). Упрощенная блок-схема кодека представлена на рис. 3.4.
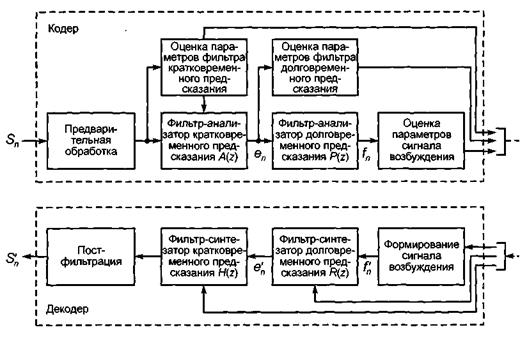
Рис. 3.4. Упрощенная блок-схема речевого кодека RPE-LTP
Рассмотрим кодер. Блок предварительной обработки кодера осуществляет [43]:
- предыскажение входного сигнала при помощи цифрового фильтра, подчеркивающего верхние частоты;
- нарезание сигнала на сегменты по 160 выборок (20 мс);
- взвешивание каждого из сегментов окном Хэмминга («косинус на пьедестале» – амплитуда сигнала плавно спадает от центра окна к краям).
Далее для каждого 20-миллисекундного сегмента оцениваются параметры фильтра кратковременного линейного предсказания – 8 коэффициентов частичной корреляции ki = 1,..., 8 (порядок предсказания М= 8), которые для передачи по каналу связи преобразуются в логарифмические отношения площадей ri, причем для функции логарифма используется кусочно-линейная аппроксимация.
Сигнал с выхода блока предварительной обработки фильтруется решетчатым фильтром-анализатором кратковременного линейного предсказания и по его выходному сигналу (остатку предсказания еn) оцениваются параметры долговременного предсказания: коэффициент предсказания g и задержка d. При этом 160-выборочный сегмент остатка кратковременного предсказания еn разделяется на 4 подсегмента по 40 выборок в каждом. Параметры g, d оцениваются для каждого из подсегментов в отдельности, причем для оценки задержки d для текущего подсегмента используется скользящий подсегмент из 40 выборок, перемещающийся в пределах предшествующих 128 выборок сигнала остатка предсказания еn. Сигнал еn фильтруется фильтром-анализатором долговременного линейного предсказания, а выходной сигнал последнего (остаток предсказания) fn – фильтруется сглаживающим фильтром и по нему формируются параметры сигнала возбуждения в отдельности для каждого из 40 - выборочных подсегментов.
Сигнал возбуждения одного подсегмента состоит из 13 импульсов, следующих через равные промежутки времени (втрое большие, чем интервал дискретизации исходного сигнала) и имеющих различные амплитуды. Для формирования сигнала возбуждения 40 импульсов подсегмента сглаженного остатка/, обрабатываются следующим образом. Последний (сороковой) импульс отбрасывается, а первые 39 импульсов разбиваются на три последовательности: в первой – импульсы 1, 4,...,37, во второй – импульсы 2, 5,...,38, в третьей – импульсы 3, 6,..., 39.
В качестве сигнала возбуждения выбирается та из последовательностей, энергия которой больше. Амплитуды импульсов нормируются по отношению к импульсу с наибольшей амплитудой, и нормированные амплитуды кодируются тремя битами каждая при линейной шкале квантования. Абсолютное значение наибольшей амплитуды кодируется шестью битами в логарифмическом масштабе. Положение начального импульса 13-элементной последовательности кодируется двумя битами, т.е. кодируется номер последовательности, выбранной в качестве сигнала возбуждения для данного подсегмента.
Таким образом, выходная информация кодера речи для одного 20-миллисекундного сегмента речи включает параметры:
- фильтра кратковременного линейного предсказания – 8 коэффициентов логарифмического отношения площадей ri (i = 1,..., 8 – один набор на весь сегмент);
- фильтра долговременного линейного предсказания (коэффициент предсказания g и задержка d) для каждого из четырех подсегментов;
- сигнала возбуждения – номер последовательности n, максимальная амплитуда v, нормированные амплитуды bi (i = 1,..., 13) импульсов последовательности – для каждого из четырех подсегментов.
Число битов, отводимых на кодирование передаваемых параметров, приведено в табл. 3.1. Всего для одного 20-миллисекундного сегмента речи передается 260 бит информации, т.е. рассмотренный речевой кодер осуществляет сжатие информации по отношеник к несжатому оцифрованному речевому сигналу (20 миллисекундному сегменту соответствует 160 восьмиразрядных отсчетов или 1280 битов) почти в 5 раз (1280: 260 = 4,92). Пере; выдачей в канал связи выходная информация кодера речи также подвергается дополнительно канальному кодированию.
Декодер. Последовательность выполняемых им функций иллюстрируется на рис. 3.4. Блок формирования сигнала возбуждения, используя принятые параметры сигнала возбуждения, восстанавливает 13-импульсную последовательность сигнала возбуждения для каждого из подсегментов сигнала речи, включая амплитуды импульсов и их расположение во времени. Сформированный таким образом сигнал возбуждения фильтруется фильтром-синтезатором долговременного предсказания, на выходе которого получается восстановленный остаток предсказания фильтра-анализатора кратковременного предсказания.
Таблица 3.1. Кодирование выходной информации кодера речи стандарта GSM
| Передаваемые параметры | Число битов кодирования | Примечания |
| Параметры фильтра кратко-временного предсказания (лога-рифмические отношения площа-дей ri, i=1,..., 8) | r1,r2-2 x 6 r3,r4-2 x 5 r5,r6-2 x 4 r7,r8-2 x 3 | |
| Параметры фильтра долго-временного предсказания (коэффициент предсказания g, задержка d для каждого 1 из четырех подсегментов) | g-2, d-7 | |
| Параметры сигнала возбуждения (номер последовательности и, максимальная амплитуда v, нормированные амплитуды импульсов bi, i = 1,...,13, для каждого из четырех подсегмен-тов) | n-2, v-6, bi-3 | |
| Всего за 20-миллисекундный сег-мент |
Последний фильтруется решетчатым фильтром-синтезатором кратковременного предсказания, причем параметры фильтра предварительно преобразуются из логарифмических отношений площадей ri в коэффициенты частичной корреляции ki. Выходной сигнал фильтра-синтезатора кратковременного предсказания фильтруется (в блоке постфильтрации) цифровым фильтром, восстанавливающим амплитудные соотношения частотных составляющих сигнала речи, т.е. компенсирующим предыскажение, внесенное входным фильтрсш блока предварительной обработки кодера. Сигнал на выходе постфильтра является восстановленным цифровым сигналом речи.

