 2015-07-14
2015-07-14 7077
7077Первый компонент, теория тестов, содержит описание статистических моделей обработки диагностических данных. Здесь содержатся модели анализа ответов в тестовых заданиях и модели подсчета суммарных результатов теста. Мелленберг (1980, 1990) назвал это «психометрией». Классическая теория тестов, современная теория тестов (или модель анализа ответов на задания тестов — IRT) и модель
выборки заданий составляют три наиболее важных типа моделей теории тестов. Предметом рассмотрения психодиагностики являются первые две модели.
Классическая теория тестов. На основе этой теории разработано большинство интеллектуальных и личностных тестов. Центральным понятием этой теории является понятие «надежности». Под надежностью понимается согласованность результатов при повторном оценивании. В справочных пособиях это понятие обычно представляется очень кратко, а затем дается подробное описание аппарата математической статистики. В этой, вводной, главе мы представим сжатое описание основного значения отмеченного понятия. В классической теории тестов под надежностью понимается повторяемость результатов нескольких процедур измерения (преимущественно измерений при помощи тестов). Понятие надежности предполагает вычисление ошибки измерения. Результаты, полученные в процессе тестирования, могут быть представлены как сумма истинного результата и ошибки измерения:
Xi = Ti + Еj
где Xi — оценка полученных результатов, Ti — истинный результат, а Еj — ошибка измерения.
Оценка полученных результатов — это, как правило, количество правильных ответов на задания теста. Истинный результат можно рассматривать как истинную оценку в платоновском смысле (Gulliksen, 1950). Широко распространенным является понятие ожидаемых результатов, т.е. представлений о баллах, которые могут быть получены в результате большого числа повторений процедур измерения (Lord & Novich, 1968). Но проведение одной и той же процедуры оценивания с одним человеком не представляется возможным. Поэтому необходим поиск других вариантов решения проблемы (Witlman, 1988).
В рамках этой концепции делаются некоторые допущения относительно истинных результатов и ошибок измерения. Последние принимаются в качестве независимого фактора, что, конечно, является вполне обоснованным предположением, так как случайные колебания результатов не дают ковариаций: rЕЕ=0.
Предполагается, что корреляции между истинными баллами и ошибками измерения не существует: rEE=0.
Суммарная ошибка равна 0, т.к. в качестве истинной оценки берется среднее арифметическое значение:
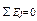
Эти допущения приводят нас в итоге к известному определению надежности как отношения истинного результата к общей дисперсии или выражению: 1 минус отношение, в числителе которого ошибка измерения, а в знаменателе — общая дисперсия:
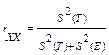
 , ИЛИ
, ИЛИ 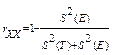
Из этой формулы определения надежности получаем, что дисперсия ошибки S2(E) равна общей дисперсии в числе случаев (1 – rXX'); таким образом, стандартная ошибка измерения определяется по формуле:
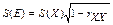
После теоретического обоснования надежности и его производных необходимо определить индекс надежности того или иного теста. Существуют практические процедуры оценивания надежности тестов, такие как использование взаимозаменяемых форм (параллельные тесты), расщепление заданий на две части, повторное тестирование и измерение внутренней согласованности. Каждый справочник содержит индексы постоянства тестовых результатов:
rXX’=r(x1, x2)
где rXX’ — коэффициент стабильности, а x1 и x2 — результаты двух измерений.
Понятие надежности взаимозаменяемых форм введено и разработано Гулликсеном (1950). Данная процедура достаточно трудоемка, поскольку связана с необходимостью создания параллельной серии заданий
rXX’=r(x1, x2)
где rXX’ — коэффициент эквивалентности, а x1 и x2 — два параллельных теста.
Следующая процедура — расщепление основного теста на две части А и В — более проста в использовании. Показатели, полученные по обеим частям теста, коррелируются. С помощью формулы Спирмена-Брауна оценивается надежность теста в целом:
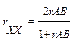 ,
,
где А и В — две параллельные части теста.
Следующий метод — определение внутренней согласованности выполнения заданий теста. Этот метод основан на определении ковариаций отдельных заданий. Sg — дисперсия произвольно выбранного задания, и Sgh — ковариация двух произвольно выбранных заданий. Наиболее часто используемый коэффициент для определения внутренней согласованности — это «коэффициент альфа» Кронбаха. Используются также формула КР20 и λ—2 (лямбда-2).
В классической концепции надежности определяются ошибки измерения, возникающие как в процессе тестирования, так и в процессе наблюдений. Источники этих ошибок различны: это могут быть и личностные особенности, и особенности условий тестирования, и сами тестовые задания. Существуют конкретные методы вычисления ошибок. Мы знаем, что наши наблюдения могут оказаться ошибочными, наши методические инструменты несовершенны так же, как несовершенны и сами люди. (Как не вспомнить Шекспира: «Ненадежен ты, чье имя человек»). То, что в классической теории тестов ошибки измерения эксплицируются и объясняются, является важным положительным моментом.
Классическая теория тестов имеет ряд существенных особенностей, которые можно рассматривать и как ее недостатки. Некоторые из этих характеристик отмечаются в справочниках, но их значение (с житейской точки зрения) подчеркивается нечасто, как не отмечается и то, что с теоретической или методической точки зрения их следует считать недостатками.
Первое. Классическая теория тестов и понятие надежности ориентированы на подсчет суммарных тестовых показателей, представляющих собой результат сложения оценок, полученных в отдельных заданиях. Так, при работе
с тестом, содержащим 40 заданий (при оценке 0 или 1балл), существует несколько возможных вариантов сочетаний конкретных заданий, при которых можно получить, например, 20 баллов. Таким образом, de facto любое задание можно заменить другим.
Второе. Коэффициент надежности предполагает оценку величины разброса измеряемых показателей. Отсюда следует, что коэффициент надежности будет ниже, если (при равенстве других показателей) выборка является более однородной. Не существует единого коэффициента внутренней согласованности заданий теста, этот коэффициент всегда «контекстуален». Крокер и Альджина (1986), например, предлагают специальную формулу «коррекции для гомогенной выборки», предназначенную для самых высоких и самых низких результатов, полученных проходящими тестирование. Для диагноста важно знать характеристики вариаций в выборочной совокупности, иначе он не сможет использовать коэффициенты внутренней согласованности, указанные в руководстве к данному тесту.
Третье. Феномен сведения к показателю среднего арифметического является логическим следствием классической концепции надежности. Если оценка в тесте колеблется (т.е. она недостаточно надежна), то вполне возможно, что при повторении процедуры субъекты, имеющие низкие показатели, получат более высокие баллы, и наоборот, субъекты с высокими показателями — низкие. Этот артефакт процедуры измерения нельзя ошибочно принять за истинное изменение или проявление процессов развития. Но в то же время разграничить их нелегко, т.к. никогда нельзя исключить возможность изменения в ходе развития. Для полной уверенности необходимо'сравнение с контрольной группой.
Четвертая характеристика тестов, разработанных в соответствии с принципами классической теории,— это наличие нормативных данных. Знание тестовых норм позволяет исследователю адекватно интерпретировать результаты тестируемых. Вне норм тестовые оценки лишены смысла. Выработка тестовых норм — это достаточно дорогостоящее предприятие, поскольку психолог должен получить результаты тестирования на репрезентативной выборке.
2 Я. тер Лаак
Если говорить о недостатках классической концепции надежности, то здесь уместно привести высказывание Сий-тсма (1992, р. 123—125). Он отмечает, что первое и главное предположение классической теории тестов состоит в том, что тестовые результаты подчиняются интервальному принципу. Однако никаких исследований, подтверждающих это предположение, нет. По сути, это «измерение по произвольно установленному правилу». Данная особенность ставит классическую теорию тестов в менее выгодное положение по сравнению со шкалами измерения установок и, конечно же, по сравнению с современной теорией тестов. Многие методы анализа данных (дисперсионный анализ. регрессионный анализ, корреляционный и факторный анализ) основаны на допущении существования интервальной шкалы. Однако оно не имеет твердого обоснования. Рассматривать шкалу истинных результатов как шкалу значений психологических характеристик (например, арифметических способностей, интеллекта, нейротизма) можно только предположительно.
Второе замечание касается того, что результаты выполнения теста — это не абсолютные показатели той или иной психологической характеристики тестируемого, их необходимо рассматривать лишь как результаты выполнения того или иного теста. Два теста могут претендовать на изучение одних и тех же психологических характеристик (например, интеллекта, вербальных способностей, экстраверсии), но это не означает, что эти два теста равноценны и обладают одинаковыми возможностями. Сравнение показателей двух людей, прошедших тестирование разными тестами, некорректно. То же относится и к заполнению двух разных тестов одним испытуемым. Третье замечание относится к предположению, что стандартная ошибка измерения одинакова применительно к любому уровню измеряемых способностей индивида. Однако не существует эмпирической проверки этого предположения. Так, например, нет гарантии того, что тестируемый с хорошими математическими способностями при работе с относительно простым арифметическим тестом получит высокие баллы. В этом случае высокую оценку скорее получит человек с низкими или средними способностями.
В рамках современной теории тестов или теории анализа ответов в заданиях теста содержится описание большого
количества моделей возможных ответов респондентов. Эти модели различаются положенными в их основу допущениями, а также требованиями по отношению к получаемым данным. Модель Раша часто рассматривается в качестве синонима теорий анализа ответов в заданиях теста (1RT). На самом деле это только одна из моделей. Представленная в ней формула для описания характеристической кривой задания g выглядит следующим образом:
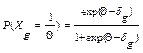
где g — отдельное задание теста; ехр — функция экспоненты (нелинейная зависимость); δ («дельта») — уровень трудности теста.
Другие задания теста, например h, также получают собственные характеристические кривые. Выполнение условия δh>δg (g означает, что h — более трудное задание. Следовательно, для любого значения показателя Θ («тета» — латентные свойства способностей тестируемых) вероятность успешного выполнения задания h меньше. Эта модель называется строгой, поскольку очевидно, что при низкой степени выраженности черты вероятность выполнения задания близка к нулю. В этой модели нет места угадыванию и предположениям. Для заданий с вариантами выбора нет необходимости делать предположения о вероятности успеха. Кроме того, эта модель строга в том смысле, что все задания теста должны иметь одинаковую дискриминатив-ную способность (высокая дискриминативность отражается в крутизне кривой; здесь возможно построение шкалы Гут-тмана, согласно которой в каждой точке характеристической кривой вероятность выполнения задания меняется от О до 1). Из-за этого условия не все задания могут быть включены в тесты, созданные на основе модели Раша.
Существует несколько вариантов этой модели (например, Birnbaura, 1968, См. Lord & Novik). Она допускает существование заданий с различной дискриминативной
способностью.
Голландский исследователь Моккен (1971) разработал две модели анализа ответов в заданиях теста, требования которых не так строги, как в модели Раша, и поэтому, возможно, более реалистичны. В качестве основного усло-
35
вия Моккен выдвигает положение о том, что характеристическая кривая задания должна следовать монотонно, без обрывов. Все задания теста при этом направлены на изучение одной и той же психологической характеристики, измерять которую должна в. Допускается любая форма этой зависимости, пока она не прервется. Следовательно, форма характеристической кривой не определяется какой-либо специфической функцией. Такая «свобода» позволяет использовать больше заданий теста, и уровень оценивания при этом оказывается не выше, чем обычный.
Методология моделей ответов на задания теста (IRT) отличается от методологии большинства экспериментальных и корреляционных исследований. Математическая модель предназначена для изучения поведенческих, когнитивных, эмоциональных характеристик, а также феноменов развития. Эти рассматриваемые феномены часто ограничиваются ответами на задания, что позволило Мел-ленбергу (1990) назвать теорию IRT «мини-теорией о мини-поведении». Результаты исследования могут быть в определенной степени представлены как кривые согласованности, особенно в тех случаях, когда теоретические представления об изучаемых характеристиках отсутствуют. До сих пор в нашем распоряжении имеются лишь единицы тестов интеллекта, способностей и личностных тестов, созданных на основе многочисленных моделей теории IRT. Варианты модели Раша чаще используются при разработке тестов достижений (Verhelst, 1993), а модели Моккена больше подходят для феноменов развития (см. также гл. 6).
Ответ тестируемого на задания теста является основной единицей моделей IRT. Тип ответа определяется степенью выраженности у человека изучаемой характеристики. Такой характеристикой могут быть, например, арифметические или пространственные способности. В большинстве случаев это тот или иной аспект интеллекта, характеристики достижений или личностные особенности. Предполагается, что между положением данного конкретного человека в некотором диапазоне изучаемой характеристики и вероятностью успешного выполнения того или иного задания существует нелинейная зависимость. Нелинейность этой зависимости в определенном смысле интуитивно понятна. Известные фразы «Всякое начало трудно» (медленный не-
линейный старт) и «Стать святым не так просто», означают что дальнейшее совершенствование после достижения определенного уровня идет трудно. Кривая медленно приближается, но почти никогда не достигает 100%-го уровня успеха.
Некоторые модели скорее противоречат нашему интуитивному пониманию. Возьмем такой пример. Человек с индексом выраженности произвольной характеристики равным 1,5 имеет 60-процентную вероятность успеха при выполнении задания. Это противоречит нашему интуитивному пониманию такой ситуации, ведь можно либо успешно справиться с заданием, либо не справиться с ним вообще. Возьмем такой пример: 100 раз человек пытается взять высоту 1м 50 см. Успех сопутствует ему 60 раз, т.е. он имеет 60-процентную вероятность успеха.
Для оценки степени выраженности характеристики необходимо, по крайней мере, два задания. Модель Раша предполагает определение выраженности характеристик вне зависимости от трудности задания. Это также противоречит нашему интуитивному пониманию: предположим, что человек имеет 80-процентную вероятность прыгнуть выше 1,30 м. Если это так, то в соответствии с характеристической кривой заданий он имеет 60-процентную вероятность прыгнуть выше 1,50 м и 40-процентную вероятность прыгнуть выше 1,70 м. Следовательно, вне зависимости от значения независимой переменной (высоты) можно оценить способность человека прыгать в высоту.
Существует около 50 моделей IRT (Goldstein & Wood, 1989).Имеется множество нелинейных функций, описывающих (объясняющих) вероятность успеха в выполнении задания или группы заданий. Требования и ограничения этих моделей различны, и эти различия могут быть обнаружены при сопоставлении модели Раша и шкалы Моккена. К требованиям этих моделей можно отнести:
1) необходимость определения исследуемой характеристики и оценку позиции человека в диапазоне этой черты;
2) оценку последовательности заданий;
3) проверку конкретных моделей. В психометрии разработано множество процедур для проверки модели.
В некоторых справочных пособиях теория IRT рассматривается как форма анализа заданий теста (см., например,
Croker& Algina, J 986). Можно, однако, отстаивать ту точку зрения, что теория IRT — это «мини-теория о мини-поведении». Сторонники теории IRT замечают, что если-несовершенны концепции (модели) среднего уровня, то что же можно сказать о более сложных конструктах в психологии?
Классическая и современная теории тестов. Люди не могут не сравнивать вещи, которые выглядят почти одинаково. (Возможно, житейский эквивалент психометрии и состоит, главным образом, в сравнении людей по значимым характеристикам и выборе между ними). Каждая из представленных теорий — и теория измерения ошибок оценивания, и математическая модель ответов на задания теста — имеет своих сторонников (Goldstein & Wood, 1986).
Модели IRT не вызывают упреков в том, что это «оценивание по правилам», в отличие от классической теории тестов. Модель IRT ориентирована на анализ оцениваемых характеристик. Характеристики личности и характеристики заданий оцениваются с помощью шкал (порядковых или интервальных). Более того, возможно сопоставление показателей выполнения разных тестов, направленных на изучение сходных характеристик. Наконец, надежность неодинакова для каждого значения на шкале, а средние показатели обычно являются более надежными, чем показатели, расположенные в начале и в конце шкалы. Таким образом, модели IRT в теоретическом отношении представляются более совершенными. Существует и различия в практическом использовании современной теории тестов и классической теории (Sijstma, 1992, стр. 127—130). Современная теория тестов более сложна по сравнению с классической, поэтому она реже используется неспециалистами. Более того, IRT предъявляет особые требования к заданиям. Это означает, что задания должны быть исключены из теста, если они не удовлетворяют требованиям модели. Данное правило относится далее к тем заданиям, которые входили в состав широко используемых тестов, построенных по принципам классической теории. Тест становится короче, и, следовательно, надежность его снижается.
IRT предлагает математические модели для изучения реальных феноменов. Модели должны помочь нам понять ключевые аспекты этих феноменов. Однако здесь кроется основной теоретический вопрос. Модели можно рассматри-
ватькак подход к изучению сложной реальности, в которой мы живем. Но модель и реальность — не одно и то же. Согласно пессимистическому взгляду, возможно моделирование лишь единичных (и притом не самых интересных) типов поведения. Также можно встретить утверждение, что реальность вообще не подлежит моделированию, т.к. она подчиняется не одним лишь причинно-следственным законам. В лучшем случае возможно моделирование отдельных (идеальных) поведенческих феноменов. Существует и другой, более оптимистичный, взгляд на возможности модели-рования. Приведенная выше позиция блокирует возможность глубокого постижения природы феноменов человеческого поведения. Применение той или иной модели поднимает некоторые обшие, фундаментальные вопросы. На наш взгляд, не подлежит сомнению, что IRT является концепцией теоретически и технически превосходящей классическую теорию тестов.
Практическим назначением тестов, на какой бы теоретической основе они не создавались, является определение значимых критериев и установление на их основе характеристик тех или иных психологических конструктов. Имеет ли модель IRT преимущества и в этом отношении? Вполне возможно, что тесты, созданные на основе этой модели, не дают более точного прогноза по сравнению с тестами, созданными на основе классической теории, и возможно, что их вклад в разработку психологических конструктов не является более весомым. Диагносты предпочитают такие критерии, которые непосредственно относятся к отдельному человеку, институту или сообществу. Модель, более совершенная в научном отношении, «ipso facto»* не определяет более подходящий критерий и в определенной степени ограничена в объяснении научных конструктов. Очевидно, что разработка тестов на основе классической теории будет продолжаться, но вместе с тем будут создаваться и новые модели IRT, распространяющиеся на изучение большего числа психологических феноменов.
В классической теории тестов различаются понятия «надежности» и «валидности». Тестовхяе результаты должны быть надежны, т.е. результаты первоначального и повторного тестировании должны согласовываться. Кроме того,
* ipso facto (лак) — сама по себе (прим. перев.).
результаты должны быть свободны (насколько это возможно) от ошибок оценивания. Наличие валидности — одно из требований, предъявляемых к полученным результатам. При этом надежность рассматривается как необходимое, но еще не достаточное условие валидности теста.
Понятие валидности предполагает, что полученные результаты относятся к чему-либо важному в практическом или теоретическом отношении. Выводы, сделанные на основе тестовых оценок, должны быть валидными. Наиболее часто говорят о двух видах валидности: прогностической (критериальной) и конструктной. Существуют также и другие виды валидности (см. гл. 3). Кроме того, валидность может быть определена и в случае квазиэкспериментов (Cook & Campbell, 1976, Cook & Shadish, 1994). Однако основным видом валидности все же является прогностическая валидность, под которой понимается возможность предсказывать по тестовому результату нечто существенное о поведении в будущем, а также возможность более глубокого понимания того или иного психологического свойства или качества.
Представленные типы валидности обсуждаются в каждом справочнике и сопровождаются описанием методов анализа валидности теста. Факторный анализ более подходит для определения конструктной валидизации, а уравнения линейной регрессии используются для анализа прогностической валидности. Те или иные характеристики (успеваемость, эффективность терапии) могут быть предсказаны на основе одного или нескольких показателей, пол-ученных при работе с интеллектуальными или личностными тестами. Такие техники обработки данных, как корреляционный, регрессионный, дисперсионный анализ, анализ частичных корреляций и дисперсий, служат для определения прогностической валидности теста.
Также часто описывается содержательная валидность. Предполагается, что все задачи и задания теста должны принадлежать специфической области (психических свойств, поведения и т.д.). Понятие содержательной валидности характеризует соответствие каждого задания теста измеряемой области. Содержательная валидность иногда рассматривается как часть надежности или «обобщаемость» (Cronbach, Gleser, Nanda & Rajaratnam, 1972). Однако при
выборе заданий для тестов достижений в конкретной предметной области важно также обращать внимание на правила включения заданий в тест.
В классической теории тестов надежность и валидность рассматриваются относительно независимо друг от друга. Но существует и другое понимание соотношения этих понятий. Современная теория тестов основывается на применении моделей. Параметры оцениваются внутри некоторой модели. Если задание не соответствует требованиям модели, то в рамках этой модели оно признается невалидным. Конструктная валидизации представляет собой часть проверки самой модели. Эта валидизации относится главным образом к проверке существования одномерной латентной исследуемой черты с известными шкальными характеристиками. Шкальные оценки, несомненно, могут быть использованы для определения соответствующих критериев, и возможна их корреляция с показателями других конструктов для сбора информации о конвергентной и дивергентной валидности конструкта.
Психодиагностика аналогична языку, описываемому как единство четырех компонентов, представленных на трех уровнях. Первый компонент, теория тестов, аналогичен синтаксису, грамматике языка. Порождающая (генеративная) грамматика — это, с одной стороны, остроумная модель, с другой — система, подчиняющаяся правилам. С помощью этих правил на основе простых утвердительных предложений строятся сложные. При этом, однако, данная модель оставляет в стороне описание того, как организован процесс коммуникации (что передается и что воспринимается), и с какими целями он осуществляется. Для понимания этого требуются дополнительные знания. То же можно сказать и о теории тестов: она является необходимой в психодиагностике, но она не способна объяснить, что психодиагност делает и каковы его цели.
1.3.2. Психологические теории и психологические конструкты
Психодиагностика — это всегда диагностика чего-то конкретного: личностных характеристик, поведения, мышления, эмоций. Тесты предназначены оценивать индивидуальные различия. Существует несколько концепций
индивидуальных различий, каждая из которых имеет свои отличительные особенности. Если признается, что психодиагностика не ограничивается только оценкой индивидуальных различий, то тогда и другие теории приобретают существенное значение для психодиагностики. Примером является оценка различий процессов психического развития и различий в социальном окружении. Хотя оценка индивидуальных различий не является непременным атрибутом психодиагностики, тем не менее существуют определенные традиции исследования в этой области. Психодиагностика начиналась с оценки различий интеллекта. Основной задачей тестов было «определение наследственной передачи гениальности» (Gallon) или отбор детей для обучения (Binet, Simon). Измерение коэффициента интеллектуальности получило теоретическое осмысление и прак-тическую разработку в трудах Спирмена (Великобритания) и Терстоуна (США). Раймонд Б.Кеттел сделал подобное для оценки личностных характеристик. Психодиагностика становится неразрывно связанной с теориями и представлениями об индивидуальных различиях в достижениях (оценка предельных возможностей) и формах поведения (уровень типичного функционирования). Эта традиция продолжает оставаться эффективной и сегодня. В учебных пособиях по психодиагностике гораздо реже оцениваются различия в социальном окружении по сравнению с рассмотрением особенностей самих процессов развития. Для этого не существует каких-либо разумных объяснений. С одной стороны, диагностика не ограничивается определенными теориями и понятиями. С другой стороны, она нуждается в теориях, поскольку именно в них определяется диагностируемое содержание (т.е. «что» диагностируется). Так, например, интеллект может рассматриваться и как общая характеристика, и как основание для множества независимых друг от друга способностей. Если психодиагностика пытается «уйти» от той или иной теории, то тогда основой психодиагностического процесса становятся представления здравого смысла. В исследованиях применяются различные способы анализа данных, и общая логика исследований определяет выбор той или иной математической модели и определяет структуру используемых психологических понятий. Такие методы математической статисти-
ки, как дисперсионный анализ, регрессионный анализ, факторный анализ, подсчет корреляций предполагают существование линейных зависимостей. В случае некорректного применения этих методов они «привносят» свою структуру в полученные данные и используемые конструкты.
Представления о различиях в социальном окружении и о развитии личности почти не оказали влияния на психодиагностику. В учебных пособиях (см., например, Murphy & Davidshofer, 1988) рассматривается классическая теория тестов и обсуждаются соответствующие методы статистической обработки, описываются известные тесты, рассматриваются вопросы использования психодиагностики в практике: в психологии управления, при отборе персонала, при оценке психологических характеристик человека.
Теории индивидуальных различий (а также представления о различиях между социальным окружением и о психическом развитии) аналогичны изучению семантики языка. Это изучение и сущности, и содержания, и значения. Значения структурируются определенным образом (подобно психологическим конструктам), например, по сходству или контрасту (аналогия, конвергенция, дивергенция).
1.3.3. Психологические тесты и другие методические средства
Третий компонент предложенной схемы — тесты, процедуры и методические средства, с помощью которых происходит сбор информации о характеристиках личности. Дрене и Сийтсма (1990, стр. 31) дают следующее определение тестам: «Психологический тест рассматривается как классификация согласно определенной системе или как процедура измерения, которая позволяет вынести определенное суждение об одной или нескольких эмпирически выделенных или теоретически обоснованных характеристиках конкретной стороны поведения человека (за рамками тестовой ситуации). При этом рассматривается реакция респондентов на определенное число тщательно подобранных стимулов, а полученные ответы сравниваются с тестовыми нормами».
Диагностике необходимы тесты и методики для сбора надежной, точной и валидной информации об особенностях
и характерных чертах личности, о мышлении, эмоциях и поведении человека. Помимо разработки тестовых процедур в этот компонент входят также следующие вопросы: как создаются тесты, как формулируются и отбираются задания, как протекает процесс тестирования, каковы требования к условиям проведения тестирования, как учитываются ошибки измерения, как подсчитываются и интерпретируются тестовые результаты.
В процессе разработки тестов различаются рациональная и эмпирическая стратегии. Применение рациональной стратегии начинается с определения основных понятий (например, понятия интеллекта, экстраверсии), и в соответствии с этими представлениями формулируются задания теста. Примером такой стратегии может служить концепция аспектного анализа (the facet theory) Гуттмана (1957, 1968, 1978). Сначала определяются различные аспекты основных конструктов, затем подбираются задачи и задания таким образом, чтобы был учтен каждый из этих аспектов. Вторая стратегия состоит в том, что задания подбираются на эмпирической основе. Например, если исследователь попытается создать тест профессиональных интересов, который бы позволял дифференцировать медиков от инженеров, то процедура должна быть такой. Обе группы респондентов должны ответить на все задания теста, и те пункты, в ответах на которые обнаружены статистически значимые различия, входят в окончательный вариант теста. Если, например, между группами существуют различия в ответах на утверждение «Я люблю ловить рыбу», то это утверждение становится элементом теста. Основным положением этой книги является то, что тест связан с концептуальной или таксономической теорией, определяющей эти характеристики.
Назначение теста обычно определено в инструкции по его применению. Тест должен быть стандартизирован для того, чтобы с его помощью можно было оценить различия между людьми, а не между условиями тестирования. Существуют, однако, отклонения от стандартизации в процедурах, называемых «тестированием границ возможностей» (testing the limits) и «тесты оценки потенциальных возможностей в обучении» (learning potential tests). В этих условиях респонденту оказывается помощь в процессе
тестирования и затем оценивается влияние такой процедуры на результат. Подсчет баллов за ответы на задания объективен, т.е. осуществляется в соответствии со стандартной процедурой. Интерпретация полученных результатов также строго определена и осуществляется на основе тестовых норм.
Третий компонент психодиагностики — психологические тесты, инструменты, процедуры — содержит определенные задания, которые являются наименьшими единицами психодиагностики и в этом смысле задания аналогичны фонемам языка. Число возможных сочетаний фонем ограничено. Лишь определенные фонематические структуры могут образовывать слова и предложения, обеспечивающие доведение информации до слушателя. Также и тестовые задания: лишь в определенном сочетании друг с другом они могут стать эффективным средством оценки соответствующего конструкта.

