 2015-08-13
2015-08-13 1245
1245Нехай задана певна навчальна вибірка 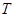 , що містить об'єкти (приклади), кожен з яких характеризується
, що містить об'єкти (приклади), кожен з яких характеризується 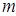 атрибутами (ознаками), причому один з цих атрибутів вказує на приналежність об'єкта до певного класу. Нехай через {C1,C2,…,Ck} позначені класи (значення мітки класу). У цьому випадку можливі три випадки:
атрибутами (ознаками), причому один з цих атрибутів вказує на приналежність об'єкта до певного класу. Нехай через {C1,C2,…,Ck} позначені класи (значення мітки класу). У цьому випадку можливі три випадки:
1. множина містить один або більше об’єктів, що відносяться до одного класу Ck. Тоді дерево рішень для – це листок, що визначає клас Ck;
2. множина не містить жодного об’єкта, тобто це порожня множина. Тоді це знову листок, і клас, що відноситься до цього листка, вибирається з іншої множини, яка відмінна від безлічі відмінного від (наприклад, з множини, що асоційована з батьком);
3. множина містить об’єкти, що відносяться до різних класів. У цьому випадку множину варто розбити на деякі підмножини. Для цього вибирається одна з ознак, що має два і більше відмінних одне від одного значень O1,O2,…,On. розбивається на підмножини T1,T2,…,Tn, де кожна підмножина 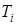 містить всі об’єкти, що мають значення
містить всі об’єкти, що мають значення 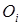 для вибраної ознаки. Ця процедура буде рекурсивно тривати доти, доки кінцева множина не буде складатися із об’єктів одного класу.
для вибраної ознаки. Ця процедура буде рекурсивно тривати доти, доки кінцева множина не буде складатися із об’єктів одного класу.
Описана вище процедура лежить в основі багатьох сучасних алгоритмів побудови дерев рішень, цей метод відомий ще за назвою «поділ та захоплення» (divide and conquer). Очевидно, що при використанні цієї методики побудова дерева рішень буде відбуватися зверху вниз. Оскільки всі об'єкти були заздалегідь віднесені до відомих нам класів, то такий процес побудови дерева рішень називається «навчанням з учителем» (supervised learning). Процес навчання також називають індуктивним навчанням або індукцією дерев (tree induction).
Нині існує велика кількість алгоритмів, що реалізують дерева рішень, проте найбільш поширеними є такі два:
- CART (ClassificationandRegressionTree) – алгоритм побудови бінарного дерева рішень – дихотомічної класифікаційної моделі. Кожний вузол дерева при розбивці має тільки двох нащадків. Як видно із назви алгоритму, він вирішує задачі класифікації та регресії.
- C4.5 – алгоритм побудови дерева рішень, в якому кількість нащадків вузла є необмеженою. Такі дерева призначені тільки для задач класифікації.
Більшість із відомих алгоритмів є «жадібними алгоритмами» (Greedyalgorithm) – вони полягають у прийнятті локально оптимальних рішень на кожному етапі, допускаючи що кінцеве рішення також виявиться оптимальним. При цьому, якщо один раз був обраний атрибут, і за ним було здійснене розбиття на підмножини, то алгоритм не може повернутися назад і вибрати інший атрибут, який дав би краще розбиття. Тому на етапі побудови не можна сказати чи в кінцевому результатів вибраний атрибут приведе до оптимального розбиття.








