 2015-08-21
2015-08-21 394
394Статические сети. Воспользуемся рассмотренной выше моделью однослойной линейной сети с двухэлементным вектором входа, значения которого находятся в интервале [–1 1], и нулевым параметром скорости настройки, как это было для случая адаптации:
% Формирование однослойной статической линейной сети с двумя входами
% и нулевым параметром скорости настройки
net = newlin([–1 1;–1 1],1, 0, 0);
net.IW{1} = [0 0]; % Значения весов
net.b{1} = 0; % Значения смещений
Требуется обучить параметры сети так, чтобы она формировала линейную зависимость вида
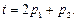
Последовательный способ. Для этого представим обучающую последовательность
в виде массивов ячеек
P = {[–1; 1] [–1/3; 1/4] [1/2; 0] [1/6; 2/3]}; % Массив векторов входа
T = {–1 –5/12 1 1}; % Массив векторов цели
Теперь все готово к обучению сети. Будем обучать ее с помощью функции train в течение 30 циклов.
В этом случае для обучения и настройки параметров сети используются функции trainwb и learnwh соответственно.
% Параметр скорости настройки весов
net.inputWeights{1,1}.learnParam.lr = 0.2;
net.biases{1}.learnParam.lr = 0; % Параметр скорости настройки смещений
net.trainParam.epochs = 30; % Число циклов обучения
net1 = train(net,P,T);
Параметры сети после обучения равны следующим значениям:
W = net1.IW{1}
W = 1.9214 0.92599
y = sim(net1, P)
y = [–0.99537] [–0.40896] [0.96068] [0.93755]
EE = mse([y{:}]–[T{:}])
EE = 1.3817e–003
Зависимость величины ошибки обучения от числа циклов обучения приведена
на рис. 3.4.
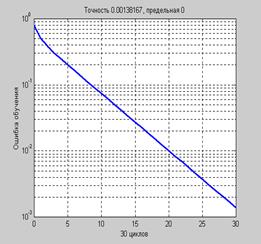 Рис. 3.4
Рис. 3.4
Это тот же самый результат, который был получен для группового способа адаптации с использованием функции adapt.
Групповой способ. Для этого представим обучающую последовательность в виде массивов формата double array:
P = [–1 –1/3 1/2 1/6; 1 1/4 0 2/3];
T = [–1 –5/12 1 1];
net1 = train(net,P,T);
TRAINWB, Epoch 0/10, MSE 0.793403/0.
TRAINWB, Epoch 10/10, MSE 0.00243342/0.
TRAINWB, Maximum epoch reached.
Параметры сети после обучения равны следующим значениям:
W = net1.IW{1}
W = 1.9214 0.92599
y = sim(net1, P)
y = –0.99537 –0.40896 0.96068 0.93755
EE = mse(y–T)
EE = 1.3817e–003
Этот результат полностью совпадает с результатом последовательного обучения этой же сети.
Динамические сети. Обучение динамических сетей выполняется аналогичным образом
с использованием метода train.
Последовательный способ. Обратимся к линейной модели нейронной сети с одним входом и одним элементом запаздывания.
Установим начальные условия для элемента запаздывания, весов и смещения равными 0, а параметр скорости настройки равным 0.5:
net = newlin([–1 1],1,[0 1],0.5);
Pi = {0}; % Начальное условие для элемента запаздывания
net.IW{1} = [0 0]; % Значения весов
net.biasConnect = 0; % Значение смещения
net.trainParam.epochs = 22;
Чтобы применить последовательный способ обучения, представим входы и цели как массивы ячеек:
P = {–1/2 1/3 1/5 1/4}; % Вектор входа
Обучим сеть формировать нужный выход на основе соотношения y(t) = 2p(t) + p(t–1), тогда
T = { –1 1/6 11/15 7/10}; % Вектор цели
Используем для этой цели М-функцию train:
net1 = train(net, P, T, Pi);
Параметры сети после обучения равны следующим значениям:
W = net1.IW{1}
W = 1.9883 0.98414
y = sim(net1, P)
y = [–0.99414] [0.17069] [0.7257] [0.6939]
EE = mse([y{:}]–[T{:}])
EE = 3.6514e–005
График зависимости ошибки обучения от числа циклов приведен на рис. 3.5.
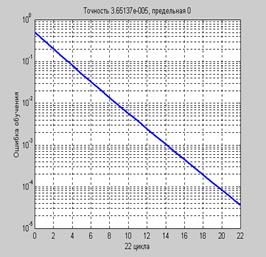 Рис. 3.5
Рис. 3.5
Предлагаем читателю самостоятельно выполнить сравнение результатов обучения
с результатами адаптации этой же сети.
Групповой способ представления обучающей последовательности для обучения динамических систем не применяется.








