 2015-08-21
2015-08-21 560
560Для построения радиальных базисных сетей с нулевой ошибкой предназначена функция newrbe, которая вызывается следующим образом:
net = newrbe(P,T,SPREAD)
Входными аргументами функции newrbe являются массивы входных векторов P
и целей T, а также параметр влияния SPREAD. Она возвращает радиальную базисную сеть с такими весами и смещениями, что ее выходы точно равны целям T. Функция newrbe создает столько нейронов радиального базисного слоя, сколько имеется входных векторов в массиве P и устанавливает веса первого слоя равными P'. При этом смещения устанавливаются равными 0.8326/SPREAD. Это означает, что уровень перекрытия радиальных базисных функций равен 0.5 и все входы в диапазоне ±SPREAD считаются значимыми. Ясно, что чем больший диапазон входных значений должен быть принят во внимание, тем большее значение параметра влияния SPREAD должно быть установлено. Это наиболее наглядно проявляется при решении задач аппроксимации функций, в чем можно убедиться, обратившись к демонстрационной программе demorb1.
Веса второго слоя IW 21 (IW{2,1} – в обозначениях системы MATLAB) и смещений b 2 (b {2}) могут быть найдены путем моделирования выходов первого слоя a1 (A{1}) и последующего решения системы линейных алгебраических уравнений (СЛАУ):
[W{2,1} b{2}] * [A{1}; ones] = T
Поскольку известны входы второго слоя A{1} и цели T, а слой линеен, то для вычисления весов и смещений второго слоя достаточно воспользоваться решателем СЛАУ
Wb = T / [P; ones(1, size(P,2))]
Здесь матрица Wb содержит веса и смещения (смещения – в последнем столбце). Сумма квадратов погрешностей сети будет всегда равна 0, так как имеем задачу с Q уравнениями (пары вход/цель) и каждый нейрон имеет Q + 1 переменных (Q весов по числу радиальных базисных нейронов и одно смещение). СЛАУ с Q уравнениями и более чем Q переменными имеет свободные переменные и характеризуется бесконечным числом решений с нулевой погрешностью.
Рассмотрим пример обучения и моделирования следующей радиальной базисной сети:
P = –1:.1:1;
T = [–.9602 –.5770 –.0729.3771.6405.6600.4609.1336...
–.2013 –.4344 –.5000 –.3930 –.1647.0988.3072.3960...
.3449.1816 –.0312 –.2189 –.3201];
plot(P,T,'*r','MarkerSize',4,'LineWidth',2)
hold on
% Создание сети
net = newrbe(P,T); % Создание радиальной базисной сети
Warning: Rank deficient, rank = 13 tol = 2.2386e–014.
net.layers{1}.size % Число нейронов в скрытом слое
ans = 21
% Моделирование сети
V = sim(net,P); % Векторы входа из обучающего множества
plot(P,V,'ob','MarkerSize',5, 'LineWidth',2)
p = [–0.75 –0.25 0.25 0.75];
v = sim(net,p); % Новый вектор входа
plot(p,v,'+k','MarkerSize',10, 'LineWidth',2)
Результаты моделирования представлены на рис. 6.4.
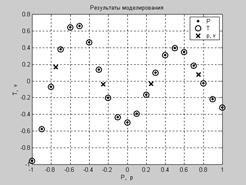 Рис. 6.4
Рис. 6.4
Здесь отмечены значения входов Р, целевых выходов Т, а также результаты обработки нового вектора р. Количество используемых нейронов в скрытом слое в данном случае равно 21, что соответствует длине обучающего множества.
Таким образом, в результате обучения функция newrbe создает радиальную базисную сеть с нулевой погрешностью на обучающем множестве. Единственное условие, которое требуется выполнить, состоит в том, чтобы значение параметра SPREAD было достаточно большим, чтобы активные области базисных функций перекрывались, чтобы покрыть весь диапазон входных значений. Это позволяет обеспечить необходимую гладкость аппроксимирующих кривых и препятствует возникновению явления переобучения. Однако значение SPREAD не должно быть настолько большим, чтобы радиальная базисная функция объявляла одинаково значимыми все значения входа.
Недостаток функции newrbe заключается в том, что она формирует сеть с числом нейронов в скрытом слое, равным числу элементов обучающего множества. Поэтому
с помощью этой функции нельзя получить приемлемого решения в случае больших размеров обучающего множества, что характерно для реальных приложений.








