2015-08-21
2015-08-21 377
377Архитектура сети GRNN показана на рис. 6.10. Она аналогична архитектуре радиальной базисной сети, но отличается структурой второго слоя, в котором используется блок normprod для вычисления нормированного скалярного произведения строки массива весов LW 21 и вектора входа a 1 в соответствии со следующим соотношением:
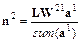 . (6.3)
. (6.3)
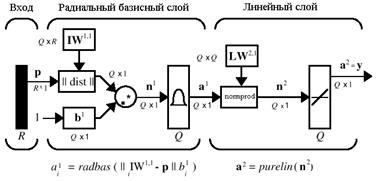 Рис. 6.10
Рис. 6.10
Первый слой – это радиальный базисный слой с числом нейронов, равным числу элементов Q обучающего множества; в качестве начального приближения для матрицы весов выбирается массив P '; смещение b 1 устанавливается равным вектор-столбцу с элементами 0.8326/SPREAD. Функция dist вычисляет расстояние между вектором входа и вектором веса нейрона; вход функции активации n 1 равен поэлементному произведению взвешенного входа сети на вектор смещения; выход каждого нейрона первого слоя a 1 является результатом преобразования вектора n 1 радиальной базисной функцией radbas. Если вектор веса нейрона равен транспонированному вектору входа, то взвешенный вход равен 0, а выход функции активации – 1. Если расстояние между вектором входа и вектором веса нейрона равно spread, то выход функции активации будет равен 0.5.
Второй слой – это линейный слой с числом нейронов, также равным числу элементов Q обучающего множества, причем в качестве начального приближения для матрицы весов LW {2,1} выбирается массив T. Предположим, что имеем вектор входа p i, близкий к одному из векторов входа p из обучающего множества. Этот вход p i генерирует значение выхода слоя a i1,близкое к 1. Это приводит к тому, что выход слоя 2 будет близок к t i.
Если параметр влияния SPREAD мал, то радиальная базисная функция характеризуется резким спадом и диапазон входных значений, на который реагируют нейроны скрытого слоя, оказывается весьма малым. С увеличением параметра SPREAD наклон радиальной базисной функции становится более гладким, и в этом случае уже несколько нейронов реагируют на значения вектора входа. Тогда на выходе сети формируется вектор, соответствующий среднему нескольких целевых векторов, соответствующих входным векторам обучающего множества, близких к данному вектору входа. Чем больше значение параметра SPREAD, тем большее число нейронов участвует в формировании среднего значения, и в итоге функция, генерируемая сетью, становится более гладкой.