 2015-08-21
2015-08-21 971
971| NEWLIN | Линейный слой LIN |
Синтаксис:
net = newlin(PR,s,id,lr)
net = newlin(PR,s,0,P)
Описание:
Линейные слои находят применение при решении задач аппроксимации, фильтрации
и предсказания сигналов, построении моделей динамических систем в задачах управления.
Функция net = newlin(PR, s, id, lr) формирует нейронную сеть в виде линейного слоя.
Входные аргументы:
PR – массив размера R´2 минимальных и максимальных значений для R векторов входа;
s – число нейронов;
id – описание линии задержки на входе сети, по умолчанию [0];
lr – параметр скорости настройки, по умолчанию 0.01.
Выходные аргументы:
net – объект класса network object с архитектурой линейного слоя.
Функция net = newlin(PR, s, 0, P), где P – матрица векторов входа, формирует линейный слой с параметром скорости настройки, гарантирующим максимальную степень
устойчивости слоя для данного входа P.
Пример:
Сформировать линейный слой, который для заданного входа воспроизводит заданный отклик системы.
Архитектура линейного слоя: линия задержки типа [0 1 2], 1 нейрон, вектор входа
с элементами из диапазона [–1 1], параметр скорости настройки 0.01.
net = newlin([–1 1], 1, [0 1 2], 0.01);
gensim(net) % Рис.11.7
Элементы линейного слоя показаны на рис. 11.7. Характерная особенность этого слоя – наличие линии задержки, что свидетельствует о том, что такая нейронная сеть является динамической.
 | |
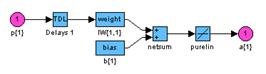 | |
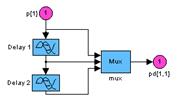 Рис. 11.7 Рис. 11.7 |
Сформируем следующие обучающие последовательности векторов входа и цели:
P1 = {0 –1 1 1 0 –1 1 0 0 1};
T1 = {0 –1 0 2 1 –1 0 1 0 1};
P2 = {1 0 –1 –1 1 1 1 0 –1};
T2 = {2 1 –1 –2 0 2 2 1 0};
Выполним обучение, используя только обучающие последовательности P1 и T1:
net = train(net,P1,T1);
Характеристика процедуры обучения показана на рис. 11.8. Из ее анализа следует, что требуемая точность обучения достигается на 73-м цикле. Соответствующие значения весов и смещения следующие:
net.IW{1}, net.b{1}
ans = 0.8751 0.8875 –0.1336
ans = 0.0619
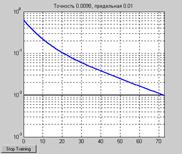 Рис. 11.8
Рис. 11.8
Выполним моделирование сети для всех значений входа, объединяющих векторы Р1 и Р2:
Y1 = sim(net,[P1 P2]);
Результаты моделирования показаны на рис. 11.10 в виде зависимости Y1; последовательность целей, объединяющая векторы T1 и T2, соответствует зависимости Т3.
Теперь выполним обучение сети на всем объеме обучающих данных, соответствующем объединению векторов входа {[P1 P2]} и векторов целей {[T1 T2]}:
net = init(net);
P3 = [P1 P2];
T3 = [T1 T2];
net.trainParam.epochs = 200;
net.trainParam.goal = 0.01;
net = train(net,P3,T3);
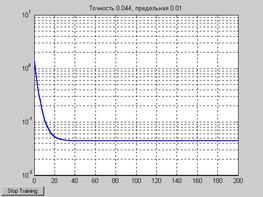 Рис. 11.9
Рис. 11.9
В этом случае процедура обучения не достигает предельной точности в течение 200 циклов обучения и, судя по виду кривой, имеет статическую ошибку.
Значения весов и смещений несколько изменяются:
net.IW{1}, net.b{1}
ans = 0.9242 0.9869 0.0339
ans = 0.0602
Соответствующая дискретная модель динамического линейного слоя имеет вид:
y k = 0.9242rk + 0.9869r k – 1 + 0.0339r k –2 + 0.0602.
Результаты моделирования показаны на рис. 11.10 в виде зависимости Y3.
Y3 = sim(net,[P1 P2])
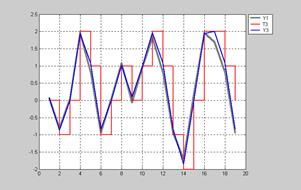 Рис. 11.10
Рис. 11.10
Из сравнения кривых Y3 и Y1 следует, что точность воспроизведения целевой последовательности на интервале тактов времени с 11-й по 19-й стала выше и несколько уменьшилась на 5-м и 9-м тактах. В целом сформированный динамический линейный слой достаточно точно отслеживает кривую цели на последовательностях входов, не участвовавших в обучении.
Алгоритм:
Линейный слой использует функцию взвешивания dotprod, функцию накопления
потенциала netsum и функцию активации purelin. Слой характеризуется матрицей весов
и вектором смещений, которые инициализируются М-функцией initzero.
Адаптация и обучение выполняются М-функциями adaptwb и trainwb, которые модифицируют веса и смещения, используя М-функцию learnwh, до тех пор пока не будет достигнуто требуемое значение критерия качества обучения в виде средней квадратичной ошибки, вычисляемой М-функцией mse.
Сопутствующие функции: NEWLIND, SIM, INIT, ADAPT, TRAIN.
| NEWLIND | Линейный слой LIND |
Синтаксис:
net = newlind(P, T)
Описание:
Линейный слой LIND использует для расчета весов и смещений процедуру решения систем линейных алгебраических уравнений на основе метода наименьших квадратов, и поэтому в наибольшей степени он приспособлен для решения задач аппроксимации, когда требуется подобрать коэффициенты аппроксимирующей функции. В задачах управления такой линейный слой можно применять для идентификации параметров динамических систем.
Функция net = newlind(P, T) формирует нейронную сеть, используя только обучающие последовательности входа P размера R´Q и цели T размера S´Q. Выходом является объект класса network object с архитектурой линейного слоя.
Пример:
Требуется сформировать линейный слой, который обеспечивает для заданного входа P выход, близкий к цели T, если заданы следующие обучающие последовательности:
P = 0:3;
T = [0.0 2.0 4.1 5.9];
Анализ данных подсказывает, что требуется найти аппроксимирующую кривую, которая близка к зависимости t = 2 p. Применение линейного слоя LIND в данном случае вполне оправдано.
net = newlind(P,T);
gensim(net) % Рис.11.11
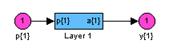 |
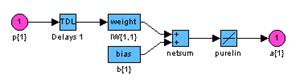 Рис. 11.11 Рис. 11.11 |
Значения весов и смещений равны:
net.IW{1}, net.b{1}
ans = 1.9800
ans = 0.3000
Соответствующая аппроксимирующая кривая описывается соотношением
y k = 1.9800rk + 0.3000.
Выполним моделирование сформированного линейного слоя:
Y = sim(net,P)
Y = 0.0300 2.0100 3.9900 5.9700
Читатель может самостоятельно убедиться, построив соответствующие графики
зависимостей, что аппроксимирующая кривая в полной мере соответствует правилу наименьших квадратов.
Алгоритм:
Функция newlind вычисляет значения веса W и смещения B для линейного уровня
с входом P и целью T, решая линейное уравнение в смысле метода наименьших квадратов:
[W b] * [P; ones] = T.
Сопутствующие функции: sim, newlin.








