 2015-08-21
2015-08-21 1158
1158В этом разделе описаны функции масштабирования, препроцессорной обработки
и восстановления данных, применяемые для повышения эффективности формирования нейронных сетей.
| PREMNMX | Приведение данных к интервалу [–1 1] |
Синтаксис:
[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t)
[pn,minp,maxp] = premnmx(p)
Описание:
Функция premnmx выполняет препроцессорную обработку обучающей последовательности путем приведения значений элементов векторов входа и цели к интервалу [–1 1].
Входные аргументы:
p – матрица векторов входа размера R´Q;
t – матрица векторов целей размера S´Q.
Выходные аргументы:
pn – матрица нормированных векторов входа размера R´Q;
minp – вектор минимальных элементов входа размера R´1;
maxp – вектор максимальных элементов входа размера R´1;
tn – матрица нормированных векторов целей размера S´Q;
mint – вектор минимальных элементов векторов целей размера S´1;
maxt – вектор максимальных элементов векторов целей размера S´1.
Пример:
Следующие команды нормализуют приведенный набор данных так, чтобы значения входа и цели попадали в интервал [–1,1]:
p = [–10 –7.5 –5 –2.5 0 2.5 5 7.5 10];
t = [0 7.07 –10 –7.07 0 7.07 10 7.07 0];
[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t)
pn = –1.0000 –0.7500 –0.5000 –0.2500 0 0.2500 0.5000 0.7500 1.0000
minp = –10
maxp = 10
tn = 0 0.7070 –1.0000 –0.7070 0 0.7070 1.0000 0.7070 0
mint = –10
maxt = 10
Если требуется нормировать только вектор входа, то можно использовать следующий оператор:
[pn,minp,maxp] = premnmx(p);
Алгоритм:
Приведение данных к диапазону [–1 1] выполняется по формуле
pn = 2 * (p – minp)/(maxp – minp) – 1.
Сопутствующие функции: PRESTD, PREPCA, POSTMNMX.
| PRESTD | Приведение данных к нормальному закону распределения |
Синтаксис:
[pn,meanp,stdp,tn,meant,stdt] = prestd(p,t)
[pn,meanp,stdp] = prestd(p)
Описание:
Функция prestd выполняет препроцессорную обработку обучающей последовательности путем приведения значений элементов векторов входа к нормальному закону распределения c нулевым средним и дисперсией, равной 1.
Входные аргументы:
p – матрица векторов входа размера R´Q;
t – матрица векторов целей размера S´Q.
Выходные аргументы:
pn – матрица приведенных векторов входа размера R´Q;
meanp – вектор средних значений векторов входа размера R´1;
stdp – вектор среднеквадратичных отклонений векторов входа размера R´1;
tn – матрица приведенных векторов целей размера S ´ Q;
meant – вектор средних значений векторов целей размера S´1;
stdt – вектор среднеквадратичных отклонений векторов целей размера S´1.
Пример:
Задана следующая обучающая последовательность векторов входа и целей. Требуется выполнить ее приведение к нормальному закону распределения с параметрами [0 1].
p = [–0.92 0.73 –0.47 0.74 0.29;
–0.08 0.86 –0.67 –0.52 0.93];
t = [–0.08 3.4 –0.82 0.69 3.1];
[pn,meanp,stdp,tn,meant,stdt] = prestd(p,t)
pn =
–1.3389 0.8836 –0.7328 0.8971 0.2910
–0.2439 1.0022 –1.0261 –0.8272 1.0950
meanp =
0.0740
0.1040
stdp =
0.7424
0.7543
tn = –0.7049 1.1285 –1.0947 –0.2992 0.9704
meant = 1.2580
stdt = 1.8982
Если задана только последовательность векторов входа, то следует применить оператор
[pn,meanp,stdp] = prestd(p);
Алгоритм:
Приведение данных к нормальному закону распределения с параметрами [0 1] выполняется по формуле
pn = (p – meanp)/stdp.
Сопутствующие функции: PREMNMX, PREPCA.
| PREРСА | Выделение главных компонентов |
Синтаксис:
[ptrans,transMat] = prepca(P,min_frac)
Описание:
Функция prepca выполняет препроцессорную обработку обучающей последовательности, применяя факторный анализ. Это позволяет преобразовать входные данные так, чтобы векторы входа оказались некоррелированными. Кроме того, может быть уменьшен и размер векторов путем удержания только тех компонентов, дисперсия которых превышает некоторое заранее установленное значение min_frac.
Входные аргументы:
P – матрица центрированных векторов входа размера R´Q;
min_frac – нижняя граница значения дисперсии удерживаемых компонентов.
Выходные аргументы:
ptrans – преобразованный набор векторов входа;
transMat – матрица преобразований.
Примеры:
Зададим массив двухэлементных векторов входа и выполним их факторный анализ, удерживая только те компоненты вектора, дисперсия которых превышает 2 % общей дисперсии. Сначала с помощью функции prestd приведем входные данные к нормальному закону распределения, а затем применим функцию prepca.
P = [–1.5 –0.58 0.21 –0.96 –0.79;
–2.2 –0.87 0.31 –1.4 –1.2];
[pn,meanp,stdp] = prestd(P)
pn =
–1.2445 0.2309 1.4978 –0.3785 –0.1058
–1.2331 0.2208 1.5108 –0.3586 –0.1399
meanp =
–0.7240
–1.0720
stdp =
0.6236
0.9148
[ptrans,transMat] = prepca(pn,0.02)
ptrans = 1.7519 –0.3194 –2.1274 0.5212 0.1738
transMat = –0.7071 –0.7071
Поскольку в данном примере вторая строка массива P почти кратна первой, то в результате факторного анализа преобразованный массив содержит только одну строку.
Алгоритм:
Функция prepca для выделения главных компонентов использует процедуру SVD-разложения матрицы центрированных векторов входа по сингулярным числам. Векторы входа умножаются на матрицу, строки которой являются собственными векторами ковариационной матрицы векторов входа. В результате получаем векторы входа с некоррелированными компонентами, которые упорядочены по величине дисперсий. Те компоненты, дисперсия которых не превышает заданное значение, удаляются; в результате сохраняются только главные компоненты [22]. Предполагается, что входные данные центрированы
с помощью функции prestd так, что их среднее значение равно 0, а дисперсия – 1.
Сопутствующие функции: PRESTD, PREMNMX.
| POSTMNMX | Восстановление данных после масштабирования функцией premnmx |
Синтаксис:
[p,t] = postmnmx(pn,minp,maxp,tn,mint,maxt)
p = postmnmx(pn,minp,maxp)
Описание:
Функция postmnmx выполняет постпроцессорную обработку, связанную с восстановлением данных, которые были масштабированы к диапазону [–1 1] с помощью функции premnmx.
Входные аргументы:
pn – матрица нормированных векторов входа размера R´Q;
minp – вектор минимальных элементов исходного массива p размера R´1;
maxp – вектор максимальных элементов исходного массива p размера R´1;
tn – матрица нормированных векторов целей размера S´Q;
mint – вектор минимальных элементов исходного массива t размера S´1;
maxt – вектор максимальных элементов исходного массива t размера S´1.
Выходные аргументы:
p – восстановленная матрица векторов входа размера R´Q;
t – восстановленная матрица векторов целей размера S´Q.
Пример:
В этом примере сначала с помощью функции premnmx выполняется масштабирование обучающей последовательности к диапазону [–1 1], затем создается и обучается нейронная сеть прямой передачи, выполняется ее моделирование и восстановление выхода с помощью функции postmnmx.
P = [–0.92 0.73 –0.47 0.74 0.29;
–0.08 0.86 –0.67 –0.52 0.93];
t = [–0.08 3.40 –0.82 0.69 3.10];
[pn,minp,maxp,tn,mint,maxt] = premnmx(P,t);
net = newff(minmax(pn),[5 1],{'tansig' 'purelin'},'trainlm');
net = train(net,pn,tn);
an = sim(net,pn)
an = –0.6493 1.0000 –1.0000 –0.2844 0.8578
a = postmnmx(an,mint,maxt)
a = –0.0800 3.4000 –0.8200 0.6900 3.1000
Восстановленный вектор выхода нейронной сети совпадает с исходным вектором целей.
Алгоритм:
Восстановление данных, масштабированных к диапазону [–1 1], выполняется по формуле
p = 0.5*(pn + 1)*(maxp – minp) + minp.
Сопутствующие функции: PREMNMX, PREPCA, POSTSTD.
| POSTSTD | Восстановление данных после применения функции prestd |
Синтаксис:
[p,t] = poststd(pn,meanp,stdp,tn,meant,stdt)
p = poststd(pn,meanp,stdp)
Описание:
Функция poststd выполняет постпроцессорную обработку, связанную с восстановлением данных, которые были масштабированы к нормальному закону распределения
с параметрами [0 1] с помощью функции prestd.
Входные аргументы:
pn – матрица масштабированных векторов входа размера R´Q;
meanp – вектор средних значений исходного массива входов размера R´1;
stdp – вектор среднеквадратичных отклонений исходного массива входов размера R´1;
tn – матрица масштабированных векторов целей размера S´Q;
meant – вектор средних значений массива целей размера S´1;
stdt – вектор среднеквадратичных отклонений массива целей размера S´1.
Выходные аргументы:
p – восстановленная матрица векторов входа размера R´Q;
t – восстановленная матрица векторов целей размера S´Q.
Примеры:
В этом примере сначала с помощью функции prestd выполняется масштабирование обучающей последовательности к нормальному закону распределения с параметрами
[0 1], затем создается и обучается нейронная сеть прямой передачи, выполняется ее моделирование и восстановление выхода с помощью функции poststd.
p = [–0.92 0.73 –0.47 0.74 0.29;
–0.08 0.86 –0.67 –0.52 0.93];
t = [–0.08 3.40 –0.82 0.69 3.10];
[pn,meanp,stdp,tn,meant,stdt] = prestd(p,t);
net = newff(minmax(pn),[5 1],{'tansig' 'purelin'},'trainlm');
net = train(net,pn,tn);
an = sim(net,pn)
an = –0.7049 1.1285 –1.0947 –0.2992 0.9704
a = poststd(an,meant,stdt)
a = –0.0800 3.4000 –0.8200 0.6900 3.1000
Восстановленный вектор выхода нейронной сети совпадает с исходным вектором целей.
Алгоритм:
Восстановление данных, масштабированных к нормальному закону распределения
с параметрами [0 1], выполняется по формуле
p = stdp * pn + meanp.
Сопутствующие функции: PREMNMX, PREPCA, POSTMNMX, PRESTD.
| POSTREG | Постпроцессорная обработка выхода сети с расчетом линейной регрессии |
Синтаксис:
[m,b,r] = postreg(A,T)
Описание:
Функция [m, b, r] = postreg(A, T) выполняет постпроцессорную обработку выхода нейронной сети и рассчитывает линейную регрессию между векторами выхода и цели.
Входные аргументы:
A – 1´Q массив выходов сети, каждый элемент которого выход сети;
T – 1´Q массив целей, каждый элемент которого целевой вектор.
Выходные аргументы:
m – наклон линии регрессии;
b – точка пересечения линии регрессии с осью Y;
Примеры:
В данном примере с помощью функции prestd нормализуется множество обучающих данных, на нормализованных данных вычисляются главные компоненты, создается и обучается сеть, затем сеть моделируется. Выход сети с помощью функции poststd денормализуется и вычисляется линейная регрессия между выходом (ненормализованным) сети
и целями, чтобы проверить качество обучения сети.
P = [–0.92 0.73 –0.47 0.74 0.29;
–0.08 0.86 –0.67 –0.52 0.93];
T = [–0.08 3.40 –0.82 0.69 3.10];
[pn,meanp,stdp,tn,meant,stdt] = prestd(P,T);
[ptrans,transMat] = prepca(pn,0.02);
net = newff(minmax(ptrans),[5 1],{'tansig' 'purelin'},'trainlm');
net = train(net,ptrans,tn);
an = sim(net,ptrans)
an = –0.7049 1.1285 –1.0947 –0.2992 0.9704
a = poststd(an,meant,stdt)
a = –0.0800 3.4000 –0.8200 0.6900 3.1000
[m,b,r] = postreg(a,t) % Рис.11.61
m = 1.0000
b = 5.6881e–014
r = 1.0000
В данном примере параметры линейной регрессии свидетельствуют о хорошей согласованности векторов выхода нейронной сети и цели, и это означает, что синтезированная нейронная сеть успешно реализует свою функцию.
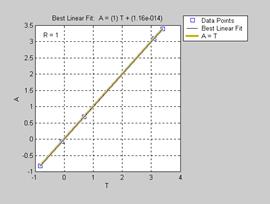 Рис. 11.61
Рис. 11.61
Сопутствующие функции: PREMNMX, PREPCA.
| TRAMNMX | Масштабирование текущих входов к диапазону [–1 1] |
Синтаксис:
pn = tramnmx(p,minp,maxp)
Описание:
Функция pn = tramnmx(p, minp, maxp) приводит текущие входные данные к диапазону
[–1 1], если известны их минимальное и максимальное значения. Эта функция применяется, когда нейронная сеть обучена с помощью данных, нормированных функцией premnmx.
Входные аргументы:
p – матрица векторов входа размера R´Q;
minp – вектор минимальных элементов входа размера R´1;
maxp – вектор максимальных элементов входа размера R´1.
Выходные аргументы:
pn – матрица нормированных векторов входа размера R´Q.
Пример:
Следующие операторы масштабируют обучающую последовательность к диапазону [–1 1], формируют и обучают нейронную сеть прямой передачи.
p = [–10 –7.5 –5 –2.5 0 2.5 5 7.5 10];
t = [0 7.07 –10 –7.07 0 7.07 10 7.07 0];
[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t);
net = newff(minmax(pn),[5 1],{‘tansig’ ‘purelin’},’trainlm’);
net = train(net,pn,tn);
Если в дальнейшем к обученной сети будут приложены новые входы, то они должны быть масштабированы с помощью функции tramnmx. Выход сети должен быть восстановлен с помощью функции postmnmx.
p2 = [4 –7];
pn = tramnmx(p2,minp,maxp);
an = sim(net,pn)
an = 0.9552 0.8589
a = postmnmx(an,mint,maxt)
a = 9.5518 8.5893
Алгоритм:
Масштабирование текущих данных к диапазону [–1 1] выполняется по формуле
pn = 2 * (p – minp)/(maxp – minp) – 1.
Сопутствующие функции: PREMNMX, PRESTD, PREPCA, TRASTD, TRAPCA.
| TRASTD | Масштабирование текущих входов к нормальному закону распределения |
Синтаксис:
pn = trastd(p,meanp,stdp)
Описание:
Функция pn = trastd(p, meanp, stdp) приводит текущие входные данные к нормальному закону распределения с параметрами [0 1], если они принадлежат к множеству с известными средним значением и среднеквадратичным отклонением. Эта функция применяется, когда нейронная сеть была обучена с помощью данных, нормированных функцией prestd.
Входные аргументы:
p – матрица векторов входа размера R´Q;
meanp – вектор средних значений элементов входа размера R´1;
stdp – вектор среднеквадратичных отклонений элементов входа размера R´1.
Выходные аргументы:
pn – матрица нормированных векторов входа размера R´Q.
Пример:
Следующие операторы масштабируют обучающую последовательность к нормальному закону распределения с параметрами [0 1], формируют и обучают нейронную сеть прямой передачи.
p = [–0.92 0.73 –0.47 0.74 0.29;
–0.08 0.86 –0.67 –0.52 0.93];
t = [–0.08 3.4 –0.82 0.69 3.1];
[pn,meanp,stdp,tn,meant,stdt] = prestd(p,t);
net = newff(minmax(pn),[5 1],{'tansig' 'purelin'},'trainlm');
net = train(net,pn,tn);
Если в дальнейшем к обученной сети будут приложены новые входы, то они должны быть масштабированы с помощью функции trastd. Выход сети должен быть восстановлен с помощью функции poststd.
p2 = [1.5 –0.8;
0.05 –0.3];
pn = trastd(p2,meanp,stdp);
an = sim(net,pn)
an = 0.8262 –1.0585
a = poststd(an,meant,stdt)
a = 2.8262 –0.7512
Алгоритм:
Масштабирование текущих данных к нормальному закону распределения с параметрами [0 1] выполняется по формуле
pn = (p – meanp)/stdp.
Сопутствующие функции: PREMNMX, PREPCA, PRESTD, TRAPCA, TRAMNMX.
| TRAPCA | Масштабирование текущих входов с учетом факторного анализа |
Синтаксис:
Ptrans = trapca(P,TransMat)
Описание:
Функция Ptrans = trapca(P, TransMat) преобразует текущие входные данные с учетом факторного анализа, примененного к обучающей последовательности. Эта функция применяется, когда нейронная сеть была обучена с помощью данных, предварительно обработанных функциями prestd и prepca.
Входные аргументы:
P – матрица текущих векторов входа размера R´Q;
TransMat – матрица преобразования, связанная с факторным анализом.
Выходные аргументы:
Ptrans – преобразованный массив векторов входа.
Пример:
Следующие операторы выполняют главный факторный анализ обучающей последовательности, удерживая только те компоненты, которые имеют дисперсию, превышающую значение 0.02.
P = [–1.5 –0.58 0.21 –0.96 –0.79;
–2.2 –0.87 0.31 –1.40 –1.20];
t = [–0.08 3.4 –0.82 0.69 3.1];
[pn,meanp,stdp,tn,meant,stdt] = prestd(P,t);
[ptrans,transMat] = prepca(pn,0.02)
ptrans = 1.7519 –0.3194 –2.1274 0.5212 0.1738
transMat = –0.7071 –0.7071
net = newff(minmax(ptrans),[5 1],{'tansig' 'purelin'},'trainlm');
net = train(net,ptrans,tn);
Если в дальнейшем к сети будут приложены новые входы, то они должны быть масштабированы с помощью функций trastd и trapca. Выход сети должен быть восстановлен
с помощью функции poststd:
p2 = [1.50 –0.8;
0.05 –0.3];
p2n = trastd(p2,meanp,stdp);
p2trans = trapca(p2n,transMat)
p2trans = –3.3893 –0.5106
an = sim(net,p2trans)
an = 0.7192 1.1292
a = poststd(an,meant,stdt)
a = 2.6231 3.4013
Алгоритм:
Масштабирование текущих данных с учетом факторного анализа выполняется
по формуле
Ptrans = TransMat * P.
Сопутствующие функции: PRESTD, PREMNMX, PREPCA, TRASTD, TRAMNMX.








