 2015-08-21
2015-08-21 747
747Входной массив P, соответствующий TS моментам времени, может быть представлен в виде массива ячеек Pseq, каждая из которых содержит данные для фиксированного момента времени (сечение по времени):
Pseq = { [ p 1(1), p 2(1), …, p Q(1)]
[ p 1(2), p 2(2), …, p Q(2)]
………
[ p 1(TS), p 2(TS), …, p Q(TS)] }.
Этот массив имеет TS ячеек, каждая из которых содержит числовой массив размера R´Q.
Такое описание входного массива ячеек соответствует последовательному представлению наблюдаемых данных во времени.
Если сформировать временные последовательности, то входной массив Р можно описать иначе. Тогда можно говорить о том, что на вход сети подается R реализаций из интервала времени [1 TS], которые могут быть описаны следующим числовым массивом Pcon:
Pcon = [ [ p 1(1), p 1(2), …, p 1(TS)];
[ p 2(1), p 2(2), …, p 2(TS)];
…….;
[ p Q(1), p Q(2), …, p Q(TS)] ].
Представление входов как числового массива реализаций в формате double соответствует групповому представлению данных.
| CELL2MAT | Преобразование массива числовых ячеек в массив double |
Синтаксис:
M = cell2mat(C)
Описание:
Функция M = cell2mat(C) преобразует массив числовых ячеек C = {M11 M12...; M21 M22...;...} в числовой массив M = [M11 M12...; M21 M22...;...].
Пример:
С = {[1 2] [3]; [4 5; 6 7] [8; 9]};
cellplot(С) % Рис. 11.63
 Рис. 11.63
Рис. 11.63
M = cell2mat(С)
M =
1 2 3
4 5 8
6 7 9
Сопутствующие функции: MAT2CELL.
| COMBVEC | Объединение выборок разных размеров |
Синтаксис:
P = combvec(P1, P2, …)
Описание:
Функция P = combvec(P1, P2, …) объединяет выборки разных размеров в единую выборку по следующему правилу. Процедура выполняется рекуррентно так, что на каждом шаге объединяются только 2 выборки. Рассмотрим первый шаг, когда объединяются массивы P 1 размера m 1´ n 1 и P2 размера m 2´ n 2. Тогда образуется массив вида
P = 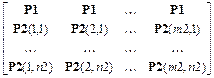 .
.
Этот массив имеет m 1+ m 2 строк и n 1´ n 2 столбцов. На следующем шаге массив Р принимается за Р 1, а массив Р 3 – за массив Р 2 и процедура повторяется.
Пример:
Рассмотрим следующие 2 выборки Р 1 и Р 2 и рассчитаем объединенную выборку Р:
P1 = [1 2 3;
4 5 6];
P2 = [7 8;
9 10];
P = combvec(P1,P2)
P =
1 2 3 1 2 3
4 5 6 4 5 6
7 7 7 8 8 8
9 9 9 10 10 10
Добавим выборку Р3:
P3 = [4 5 6];
P = combvec(P,P3)
P =
1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3
4 5 6 4 5 6 4 5 6 4 5 6 4 5 6 4 5 6
7 7 7 8 8 8 7 7 7 8 8 8 7 7 7 8 8 8
9 9 9 10 10 10 9 9 9 10 10 10 9 9 9 10 10 10
4 4 4 4 4 4 5 5 5 5 5 5 6 6 6 6 6 6
Тот же самый результат будет получен, если применить оператор P = combvec(P1,P2,P3).
| CON2SEQ, SEQ2CON | Прямое и обратное преобразования группового и последовательного представления данных |
Синтаксис:
| S = con2seq(P) | P = seq2con(S) |
| S = con2seq(P, TS) |
Описание:
Функция S = con2seq(P) преобразует числовой массив P размера Q´TS, соответствующий групповому представлению данных, в массив ячеек S размера 1´TS, содержащих числовые массивы размера Q´1 и соответствующий последовательному представлению данных.
Функция S = con2seq(P, TS) преобразует массив ячеек P размера Q´m*TS, соответствующий групповому представлению данных, в массив ячеек S размера Q´TS, соответствующий последовательному представлению. При этом каждая ячейка содержит числовой массив размера 1´m.
Функция P = seq2con(S) преобразует массив ячеек S размера Q´TS, содержащих числовые массивы размера R´m, в массив ячеек Р размера Q´1. При этом каждая ячейка содержит числовой массив размера R´m*TS.
Пример:
Преобразуем числовой массив P размера 2´3, соответствующий групповому представлению данных, в массив ячеек S размера 1´3, содержащих числовые массивы размера 2´1, соответствующий последовательному представлению данных:
P = [1 4 2;
2 5 3]
S = con2seq(P)
p2 = [2´1 double] [2´1 double] [2´1 double]
Преобразуем массив ячеек P размера Q´1, содержащих массивы размера R´m*TS, который соответствует структуре группового представления, в массив ячеек S размера Q´TS, содержащих массивы размера R´m, который соответствует структуре последовательного представления данных:
P = { [1 2; 1 2];
[3 4; 3 4];
[5 6; 5 6] };
S = con2seq(P,2)
S =
[2´1 double] [2´1 double]
[2´1 double] [2´1 double]
[2´1 double] [2´1 double]
Этому массиву соответствует следующее описание:
cell2mat(S), cellplot(S)
| ans = 1 2 1 2 3 4 3 4 5 6 5 6 |  |
Преобразуем массив ячеек S размера Q´TS, содержащих числовые массивы размера R´m, в массив ячеек Р размера Q´1. При этом каждая ячейка содержит числовой массив размера R´m*TS:
S = {[1; 1] [5; 4] [1; 2];
[3; 9] [4; 1] [9; 8]}
P = seq2con(S)
S =
[2´1 double] [2´1 double] [2´1 double]
[2´1 double] [2´1 double] [2´1 double]
P =
[2´3 double]
[2´3 double]
Сформируем числовой массив P, соответствующий групповому представлению:
P = cell2mat(P)
P =
1 5 1
1 4 2
3 4 9
9 1 8
Сопутствующие функции: CONCUR.
| CONCUR | Создание группы векторов смещений |
Синтаксис:
B = concur(b, q)
Описание:
Функция B = concur(b, q) преобразует вектор смещения b размера S´1 или массив ячеек размера Nl´1, содержащий векторы смещения для Nl слоев сети, в массив размера S´q или в массив ячеек размера Nl´1, содержащий числовые массивы размера S´q.
Примеры:
Функция concur создает 3 копии вектора смещения для данного слоя нейронной сети:
b = [1; 3; 2; –1];
B = concur(b,3)
ans =
1 1 1
3 3 3
2 2 2
–1 –1 –1
Двухслойная нейронная сеть имеет 2 вектора смещения, которые для применения функции concur необходимо объединить в вектор ячеек:
b1 = [1; 3; 2; –1];
b2 = [3; 2; –1];
b = {b1; b2}
B = concur(b,3)
b =
[4´1 double]
[3´1 double]
B =
[4´3 double]
[3´3 double]
Применение функции:
Следующий оператор вычисляет взвешенный вход для слоя с функцией накопления netsum, двумя векторами весов и одним вектором смещения:
n = netsum(z1, z2, b)
Это соотношение реализуется, если векторы z1, z2 и имеют одинаковые размеры,
например S´q. Однако если сеть моделируется с помощью функций sim, adapt или train как отклик на q групп векторов, то массивы z1 и z2 должны иметь размер S´q. Прежде чем объединить вектор смещения b с массивами z1 и z2, следует сделать q его копий:
n = netsum(z1,z2,concur(b,q))
Сопутствующие функции: NETSUM, NETPROD, SIM, SEQ2CON, CON2SEQ.
| IND2VEC, VEC2IND | Прямое и обратное преобразования вектора индексов классов в матрицу связности |
Синтаксис:
vec = ind2vec(ind)
ind = vec2ind(vec)
Описание:
Функция vec = ind2vec(ind) преобразует вектор индексов классов в матрицу связности с единицами в каждом столбце, расположенными в строке, соответствующей значению индекса. Матрица связности определена в классе разреженных матриц.
Функция ind = vec2ind(vec) преобразует матрицу связности в вектор индексов классов так, что индекс класса соответствует номеру строки.
Примеры:
Преобразовать вектор индексов классов в матрицу связности.
ind = [1 3 2 3], vec = ind2vec(ind), vec = full(vec)
ind = 1 3 2 3
| vec = (1,1) 1 (3,2) 1 (2,3) 1 (3,4) 1 | vec = 1 0 0 0 0 0 1 0 0 1 0 1 |
Преобразовать матрицу связности в вектор индексов классов.
vec = [1 0 0 0;
0 0 1 0;
0 1 0 1];
ind = vec2ind(vec)
ind = 1 3 2 3
| MAT2CELL | Преобразование числового массива в массив ячеек |
Синтаксис:
C = mat2cell(M, mrow, ncol)
Описание:
Функция C = mat2cell(M, mrow, ncol) преобразует числовой массив M размера row´col в массив ячеек, содержащих блоки, разбиение на которые задается векторами mrow и ncol. При этом должно соблюдаться условие: sum(mrow) = row, sum(ncol) = col.
Пример:
Преобразовать числовой массив М размера 3´4 в массив ячеек с разбиением
mrow = [2 1], ncol = [1 2 1].
M = [1 2 3 4; 5 6 7 8; 9 10 11 12];
C = mat2cell(M,[2 1],[1 2 1])
C =
[2´1 double] [2´2 double] [2´1 double]
[ 9] [1´2 double] [ 12]
[C{1,:}; C{2,:}]
ans =
1 2 3 4
5 6 7 8
9 10 11 12
Сопутствующие функции: CELL2MAT.
| MINMAX | Вычисление минимальных и максимальных элементов векторов входа |
Синтаксис:
pr = minmax(P)
Описание:
Функция pr = minmax(P) вычисляет минимальные и максимальные значения элементов массива P векторов входа размера R´Q и возвращает массив pr размера R´2 минимальных и максимальных значений строк массива P.
Примеры:
P = [0 1 2; –1 –2 –0.5];
pr = minmax(P)
pr =
0 2.0000
–2.0000 –0.5000
| NORMC, NORMR | Нормировка матрицы по строкам и столбцам |
Синтаксис:
Mr = normr(M)
Mc = normc(M)
Описание:
Функция Mr = normr(M) нормирует длины строк матрицы M к 1.
Функция Mc = normc(M) нормирует длины столбцов матрицы M к 1.
Примеры:
Нормировать матрицу М по строкам и столбцам.
M = [1 2;
3 4];
normr(M)
ans =
0.4472 0.8944
0.6000 0.8000
normc(M)
ans =
0.3162 0.4472
0.9487 0.8944
Анализируя результаты, нетрудно убедиться, что нормированные первая строка
и второй столбец одинаковы, поскольку они коллинеарны.
Сопутствующие функции: PNORMC.
| PNORMC | Псевдонормировка столбцов матрицы |
Синтаксис:
pM = pnormc(M,r)
Описание:
Функция pM = pnormc(M, r) нормирует столбцы до заданной длины r, добавляя дополнительную строку к исходной матрице. Такая операция определена как псевдонормировка матрицы. Необходимо соблюдать условие, чтобы длина столбцов исходной матрицы не превышала r.
При вызове функции с одним входным аргументом в форме pM = pnormc(M) по умолчанию принимается, что r равно 1.
Пример:
M = [0.1 0.6;
0.3 0.1];
pM = pnormc(M)
pM =
0.1000 0.6000
0.3000 0.1000
0.9487 0.7937
Сопутствующие функции: NORMC, NORMR.
| QUANT | Округление элементов массива до ближайшего кратного базису округления |
Синтаксис:
qP = quant(P, q)
Описание:
Функция qP = quant(P, q) округляет элементы массива Р до ближайшего значения, кратного базису округления q.
Пример:
Округлим элементы массива Р с точностью до 0.1:
P = [1.333 4.756 –3.897];
qP = quant(P,0.1)
qP = 1.3000 4.8000 –3.9000
| SUMSQR | Сумма квадратов элементов массива |
Синтаксис:
s = sumsqr(M)
Описание:
Функция s = sumsqr(M) вычисляет сумму квадратов всех элементов массива M.
Пример:
M = [ 1 2 3;
4 5 6];
s = sumsqr(M)
s = 91








