2015-09-06
2015-09-06 1100
1100На етапі визначається ступінь можливого розпаралелення задачі. Іноді декомпозиція поставленої задачі природним чином випливає з самої задачі тому є очевидною, іноді – ні. Чим менший розмір підзадач, отриманих в результаті декомпозиції, чим більша їх кількість, тим гнучкішим виявляється паралельний алгоритм і тим легше забезпечити рівномірне завантаження процесорів обчислювальної системи. Надалі, можливо доведеться укрупнити алгоритм, оскільки слід прийняти до уваги інтенсивність обміну даними та інші фактори. Сегментувати можна як обчислювальний алгоритм, так і дані. Застосовуються різні варіанти декомпозиції.
В методі декомпозиції даних спочатку сегментуються дані, а потім алгоритм їх обробки. Дані розбиваються на сегменти приблизно однакового розміру. З фрагментами даних пов’язуються операції їх обробки, з яких і формуються підзадачі. Визначаються необхідні правила обміну даними. Перекриття частин, на які розбивається задача, повинне бути мінімальним. Це дозволяє уникнути дублювання обчислень. Схема розбиття може в подальшому уточнюватися. Іноді, якщо це необхідно для зменшення кількості обмінів, допускається збільшення ступені перекриття фрагментів задачі.
При декомпозиції даних спочатку аналізуються структури даних найбільшого розміру, або ті, до яких найчастіше відбувається звертання. На різних стадіях розрахунків можуть використовуватися різні структури даних, тому можуть бути необхідними динамічні, тобто такі, що міняються в часі, схеми декомпозиції цих структур.
В методі функціональної декомпозиції спочатку сегментується обчислювальний алгоритм, а потім під цю схему підбирається схема декомпозиції даних. Успіх у цьому випадку не завжди гарантовано, оскільки схема може вимагати багатьох додаткових пересилань даних. Використання методу корисне при відсутності структур даних, які б могли бути розпаралелені очевидним чином. Функціональна декомпозиція відіграє важливу роль і як метод структурування програм. Вона може виявитися корисною при моделюванні складних систем, що складаються з множини простих підсистем, зв’язаних між собою набором інтерфейсів.
Розмір блоків, з яких складається паралельна програма, може бути різним. В залежності від розміру блоків, алгоритм може мати різну “ зернистість ”. Її виміром в найпростішому випадку є кількість операцій у блоці. Виділяють три ступені зернистості: дрібнозернистий, середньоблоковий та великоблоковий. Зернистість пов’язана з рівнем паралелізму.
Паралелізм на рівні команд найбільш дрібнозернистий. Його масштаб менше ніж 20 команд на блок. Кількість підзадач, що паралельно виконуються – від однієї до кількох тисяч., при чому середній масштаб паралелізму складає приблизно з п’яти команд на блок.
Наступний рівень - паралелізм на рівні циклів. Переважно, цикл містить не більше ніж 500 команд. Якщо ітерації циклу незалежні, вони можуть виконуватися, наприклад, за допомогою конвеєра або на векторному процесорі. Це також дрібнозернистий паралелізм.
Паралелізм на рівні підзадач – середньоблоковий. Розмір блоку – до 2000 команд. При реалізації такого паралелізму слід враховувати можливі міжпроцедурні залежності. Вимоги до комунікацій менші, ніж у випадку паралелізму на рівні команд.
Паралелізм на рівні програм (задач) – великоблоковий. Він означає виконання незалежних програм на паралельному комп’ютері і повинен підтримуватися операційною системою.
Обмін даними через спільні/розподілені змінні використовується на рівнях дрібнозернистого і середньоблокового паралелізму, а на великоблоковому – засобами передачі повідомлень.
Досягнути ефективності роботи паралельної програми можна, якщо збалансувати зернистість алгоритму і затрати часу на обмін даними.
Частини програми можуть виконуватися паралельно, лише якщо вони незалежні. Є такі види незалежності:
- незалежність за даними (дані, які обробляються однією частиною програми не модифікуються іншою її частиною);
- незалежність за керуванням (послідовність виконання частин програми може бути визначена лише під час виконання програми - наявність залежності по виконанню наперед визначає порядок виконання);
- незалежність за ресурсами (забезпечується достатньою кількістю комп’ютерних ресурсів - об’єм пам’яті, кількість функціональних вузлів та ін.);
- незалежність за виводом виникає, якщо дві підзадачі виконують запис в одну і ту ж змінну. А залежність за вводом/виводом, якщо оператори вводу/виводу двох чи декількох підзадач звертаються до одного файлу(чи змінної).
Тобто, дві підзадачі можуть виконуватися паралельно, якщо вони незалежні за даними, за керуванням і за операціями вводу/виводу.
Приклад декомпозиції даних для сіткових методів (застосовуються в інженерних і наукових розрахунках) наведений на рис.4.2. Декомпозиція в цьому випадку може бути одновимірною (великоблочна, рис.4.2.а), двовимірною (рис.4.2.б), тривимірною (дрібнозерниста, рис.4.2.в),
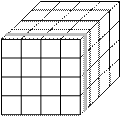
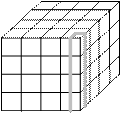
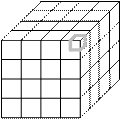



На практиці частіше використовується декомпозиція даних.
Для забезпечення ефективності декомпозиції необхідно дотримуватись таких рекомендацій:
- кількість підзадач після декомпозиції повинна приблизно на порядок переважати кількість процесорів (забезпечується гнучкість на наступних етапах);
- необхідно уникати лишніх обчислень і пересилань даних (в іншому випадку програма буде погано масштабованою і не дозволить досягнути високої ефективності при розв’язанні задач великого обсягу);
- підзадачі повинні бути приблизно однакового розміру (легше забезпечити збалансованість завантаження процесора);
- в ідеалі: сегментація повинна бути такою, щоб з збільшенням об’єму задачі кількість підзадач також зростала, при збереженні постійного розміру однієї підзадачі (забезпечує хорошу масштабованість).
Добитися ефективної роботи другої програми можна шляхом збалансування “зернистості” алгоритму і затрати часу на обмін даними.