 2015-10-16
2015-10-16 550
550В таблице результатов группировки субъектов федерации по двум классам совокупность не упорядочена по номерам, поэтому прежде чем приступать к оценки регрессионных уранвений отельно по первому и второму кластерам необходимо ранжировать изучаемые объекты по переменной КЛАСТЕР.
Шаг 1. Упорядочим имеющиеся данные по возрастанию для этого в главном меню выберем Данные® Сортировка, либо нажмем кнопку  на панели Форматирование.
на панели Форматирование.
Шаг 2. В появившемсяокне (рисунок 4.35)необходимо указать по какой переменной производится сортировка, в данном случае это КЛАСТЕР (как видим на рисунке 4.35, существует также возможность сортировать по нескольким переменным).
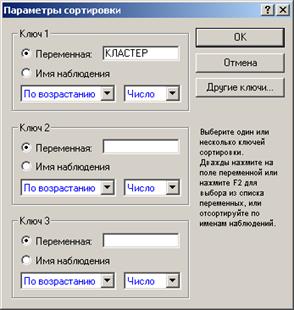
Рисунок 4.35 – Опции сортировки данных
Шаг 3. В главном меню выбираем Анализ ® Основные статистики и таблицы ® Парные и частные корреляции. Тем самым будет запущена процедура оценки парных линейных коэффициентов корреляции.
Шаг 4. В окне Парные и частные корреляции выделим переменные участвующие в анализе 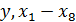 . Также в этом же окне необходимо выбрать кнопу Выбор значений
. Также в этом же окне необходимо выбрать кнопу Выбор значений  .
.
Шаг 5. В появившемся окне Условия выбора наблюдений Анализа, выделим Задать условия выбора ® Заданные и в поле Наблюдения, удовлетворяющие условию укажем v0 <23 (рисунок 4.36), т.е. корреляционные показатели будут рассчитываться на основе не всей совокупности, а лишь на основе первых 22 значений (что соответствует наблюдениям попавшим в первый кластер).
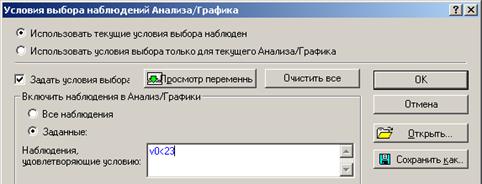
Рисунок 4.36 – Окно выбора подмножества для оценки коэффициентов корреляции по первому кластеру (приведена часть исходного окна)
Шаг 6. После нажатия кнопки ОК переходим к матрице парных коэффициентов корреляции по первым 22 наблюдениям (рисунок 4.37).
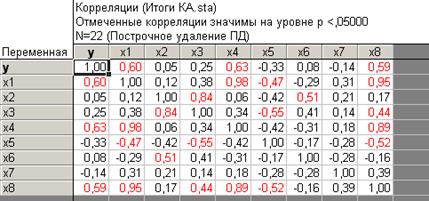
Рисунок 4.37 - Матрица парных коэффициентов корреляции по первому кластеру
Согласно приведенных данных, наибольшее влияние на зависимую переменную в данном кластере оказывают факторы 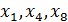 , но также стоит отметить наличие мультиколлениарности между этими показателями.
, но также стоит отметить наличие мультиколлениарности между этими показателями.
Шаг 7. Возвращаемся в модуль Множественная регрессия, необходимо обратить внимание на то, что кнопка остается во включенном положении.
Оценивая регрессионные уравнения с приведенными выше факторами получаем следующее статистически значимое уравнение (рисунок 4.38):
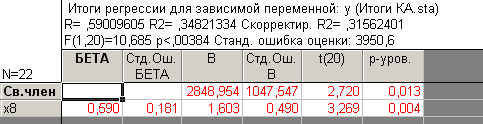
Рисунок 4.38 - Результаты оценивания парного линейного уравнения регрессии по первому кластеру с фактором x8
Используя данное уравнение, можно провести имитационные расчеты, при этом используется алгоритм описанный выше.
Шаг 8. Вернемся в модуль Парные и частные корреляции выберем кнопку и изменим условия выбора подмножеств указав вместо v0 <23 выражение v0 >22. Тем самым в анализе будут участвовать оставшиеся в совокупности единицы, которые попали во второй кластер (рисунок 4.39).
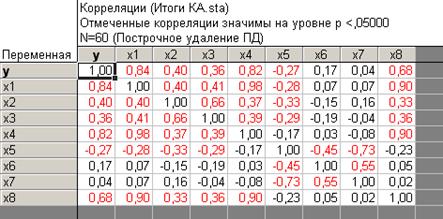
Рисунок 4.39 - Матрица парных коэффициентов корреляции по второму кластеру
Согласно приведенному рисунку, во втором кластере свое влияние проявляют большее число факторов, но при этом также наблюдается значительная мультиколлениарность, которая не позволяет нам построить множественного уравнения регрессии.
Шаг 9. Переходим в модуль Множественная регрессия (кнопка остается во включенном положении) и оцениваем регрессионные уравнения по второму кластеру, в результате получаем следующее статистически значимое уравнении (рисунок 4.40):
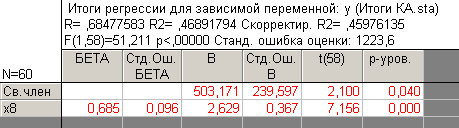
Рисунок 4.40 - Результаты оценивания парного линейного уравнения регрессии по второму кластеру с фактором x8








