 2015-10-16
2015-10-16 1055
1055Так как в нашем распоряжении имеются данные, представленные двумя группами, обратимся к методике использования в классической линейной регрессии фиктивных переменных и построим модель на основе всей совокупности. Данный подход обладает следующими важными преимуществами:
- во-первых, даст нам возможность выявить новые закономерности;
- во-вторых, имеется простой способ проверки, является ли воздействие качественного фактора значимым;
- в-третьих, при условии выполнения определенных предположений регрессионные оценки оказываются более эффективными.
В нашем случае имеем дело с регрессионной моделью, в которой фиктивная переменная находится в правой части модели и имеет две альтернативы:
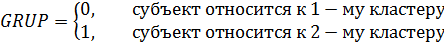
Регрессионная модель примет следующий вид:
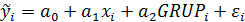
Коэффициент 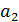 в приведенной модели называется дифференциальным коэффициентом свободного члена, так как он показывает, на какую величину отличается свободный член модели при значении фиктивной переменной, равной единице, от свободного члена модели при базовом значении фиктивной переменной.
в приведенной модели называется дифференциальным коэффициентом свободного члена, так как он показывает, на какую величину отличается свободный член модели при значении фиктивной переменной, равной единице, от свободного члена модели при базовом значении фиктивной переменной.
В результате ожидаемый объем ИЖК при соответствующем значении фактора х будет:
- 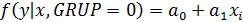 для 1-го кластера;
для 1-го кластера;
- 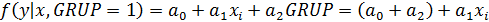 для 2-го кластера
для 2-го кластера
Шаг 1. Проведем перекодировку переменной КЛАСТЕР согласно выделенному условию, для этого в главном меню выберем Данные ® Перекодировать (рисунок 4.41).
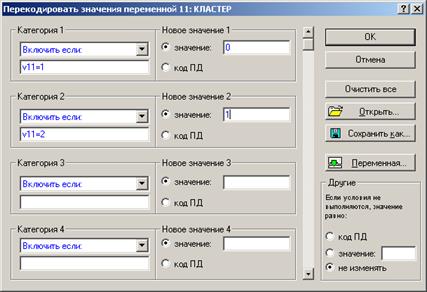
Рисунок 4.41 – Запись условия перекодирования переменной
В появившемся окне Перегруппировка значений переменной укажем условия:
- Категория 1 - v 11=1, Новое значение 1 укажем 0
- Категория 2 - v 11=2, Новое значение 2 укажем 1
Шаг 2. Возвращаемся в модель Множественная регрессия и выберем в качестве зависимой переменной y, в качестве не зависимых  и КЛАСТЕР (кнопка
и КЛАСТЕР (кнопка  должна быть выключена). Результатом выполнения процедуры станет статистически значимое множественное уравнение регрессии (рисунок 4.42).
должна быть выключена). Результатом выполнения процедуры станет статистически значимое множественное уравнение регрессии (рисунок 4.42).
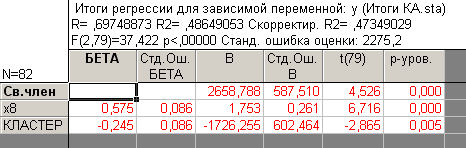
Рисунок 4.42 - Результаты оценивания множественного линейного уравнения регрессии с фиктивной переменной
Представленная на рисунке 4.42 регрессионная модель указывает на существенность различий влияния фактора 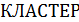 , так как параметр при переменной этой переменной получен статистически значим. При этом < 0, что указывает на «перевес» в сторону первого кластера. Частные уравнения регрессии будут иметь следующий вид:
, так как параметр при переменной этой переменной получен статистически значим. При этом < 0, что указывает на «перевес» в сторону первого кластера. Частные уравнения регрессии будут иметь следующий вид:
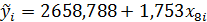 для 1-го кластера;
для 1-го кластера;
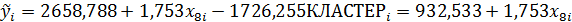 для 2-го кластера.
для 2-го кластера.
Шаг 3. В пакете STATISTICA возможно представить результаты построения модели с фиктивными переменным в наглядном виде. Для этого необходимо находясь в окне Результаты множественной регрессии выбрать вкладку Остатки / предсказанные / наблюдаемые значения и нажать кнопку Анализ остатков (рисунок 4.43).
Рисунок 4.43 - Анализ результатов построения регрессионного уравнения
Шаг 4. В появившемся окне Анализ остатков выбрать вкладку Сохранить и нажать единственно доступную кнопку Сохранить остатки и предсказания.
При запросе перечня переменных которые будут выведены совместно с результатами необходимо указать: y, и КЛАСТЕР.
Шаг 5. В главном меню выберем Графика ® Диаграммы рассеяния. В появившемся окне выделим вкладку Дополнительно. В качестве независимой переменной укажем , в качестве зависимых y и Предск. Далее в поле Тип графика выберем Составной, в поле Подгонка - Выкл.
После нажатия кнопки ОК, получим следующий рисунок 4.44:

|
|
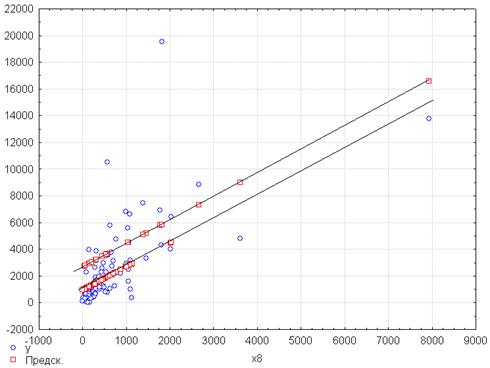
Рисунок 4.44 – Результаты построения регрессионной модели зависимости объема ИЖК от ввода в действие жилых домов и дифференциации на кластеры
Согласно представленной информации регрессионное уравнение по первому кластеру находится выше, чем по второму.
На основе полученной модели можно также проводить имитационные расчеты, вводя различные значения факторов и получая теоретические значения зависимой переменной по каждому кластеру.
Приложение Б
(обязательное)








