 2015-10-16
2015-10-16 1237
1237Тема 4. Построение регрессионного уравнения на основе результатов кластерного анализа (типологическая регрессия)
Проведенный корреляционно-регрессионный анализ привел к построению парной линейно регрессии, таким образом, значительный объем исходных данных не был использован. Причиной сложившейся ситуации является неоднородность рассматриваемой совокупности, поэтому необходимо прибегнуть к методу группировки с целью образования однородных групп, что (очевидно) позволит сформировать уравнения множественной регрессии в выделенных кластерах.
Построение многомерной группировки
Разновидностью многомерной группировки является кластерный анализ.
Кластерный анализ осуществляет классификацию многомерных наблюдений на основе определения расстояний между объектами в целях получения однородных в некотором смысле групп, называемых кластерами. Кластерный анализ объединяет несколько методов, для которых не требуется априорной информации о распределении генеральной совокупности.
В отличие от комбинированных группировок, в кластерном анализе используется иной принцип образования групп: так называемый политетическийподход. Все группировочные признаки одновременно участвуют в группировке, т.е. они учитываются все сразу при отнесении наблюдения в ту или иную группу.
Согласно работе С. А. Айвазяна и В.С. Мхитаряна «Прикладная статистика. Основы эконометрики», все многообразие кластер-процедур можно представить в виде следующей схемы (рисунок 4.23):

Рисунок 4.23 – Классификация задач, решаемых с помощью кластерного анализа
Применительно к решаемой нами задачи используем метод древовидной кластеризации, который относится к иерархическим процедурам. Данный выбор объясняется отсутствием предварительной информации о количестве кластеров (групп), на которое необходимо разбивать имеющуюся совокупность объектов.
Для реализации процедуры кластерного анализа в пакете STATISTICA необходимо:
Шаг 1. В главном меню выбирать Анализ ® Многомерный разведочный анализ ® Кластерный анализ.
Шаг 2. В появившемся окне Методы кластеризации, укажем Иерархическую классификацию и нажмем ОК (рисунок 4.24).
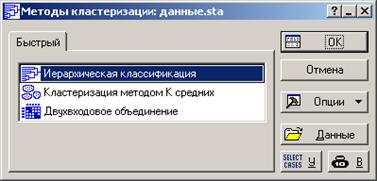
Рисунок 4.24 - Выбор кластер-процедуры
Шаг 3. В появившемся окне Кластерный анализ: иерархическая классификация необходимо выбрать вкладку Дополнительно (рисунок 4.25).
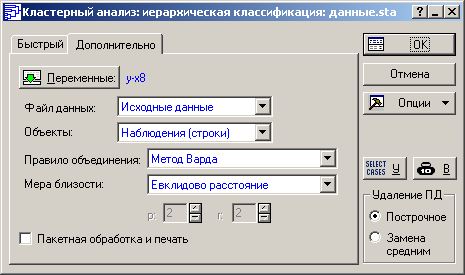
Рисунок 4.25 - Установки для выполнения иерархической классификации
Нажав кнопку, Переменные выделим зависимую переменную и все независимые (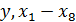 ). В поле Объекты выставим Наблюдения (строки), тем самым будет проведено разделение совокупности по субъектам федерации.
). В поле Объекты выставим Наблюдения (строки), тем самым будет проведено разделение совокупности по субъектам федерации.
Важное место в построении классификационных процедур занимает проблема выбора способа вычисления расстояния между подмножествами объектов. Полезное обобщение большинства используемых в статистической практике вариантов вычисления расстояний между двумя группами объектов дает расстояние, подсчитываемое как обобщенное степенное среднее всевозможных попарных расстояний между представителями рассматриваемых двух групп. Но, помимо него, в экономических исследованиях используются другие метрики, представленные на рисунке 4.26.

Рисунок 4.26 – Алгоритмы объединения объектов в кластеры
В поле Правило объединения выставим Метод Варда в качестве алгоритма объединения единиц в группы.
Этот метод отличается от всех других методов, поскольку он использует методы дисперсионного анализа для оценки расстояний между кластерами. Метод минимизирует сумму квадратов для любых двух (гипотетических) кластеров, которые могут быть сформированы на каждом шаге. В целом метод представляется очень эффективным, однако он стремится создавать кластеры малого размера.
Немаловажным вопросом проведения кластер-процедуры является выбор метрики (или меры близости) между объектами, каждый из которых представлен значениями характеризующего его многомерного признака. В каждой конкретной задаче этот выбор должен производиться по-своему, в зависимости от главных целей исследования, физической и статистической природы анализируемого многомерного признака, априорных сведений о его вероятностной природе и т. д.
При рассмотрении методов кластерного анализа оперируют следующими метриками, приведенными на рисунке 4.27.
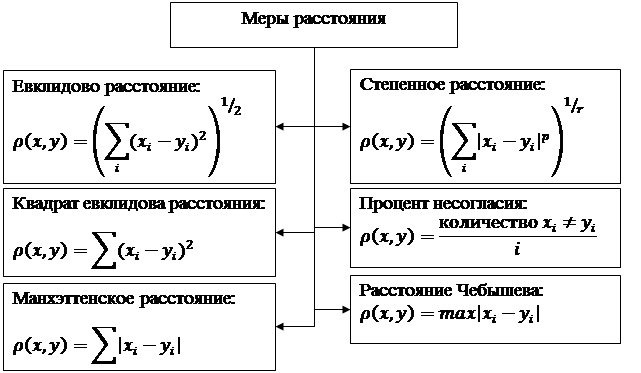
Рисунок 4.27 – Метрики вычисления расстояния между объектами в пространстве
Имеющиеся в нашем распоряжении данные относятся к натуральным, поэтому в качестве меры расстояния используем Евклидово расстояние. Поэтому в поле Мера близости выделим Евклидово расстояние.
Евклидово расстояние - наиболее общий тип расстояния. Оно попросту является геометрическим расстоянием в многомерном пространстве. Данная метрика вычисляется по исходным, а не по стандартизованным данным. Это обычный способ его вычисления, который имеет определенные преимущества (например, расстояние между двумя объектами не изменяется при введении в анализ нового объекта, который может оказаться выбросом). Тем не менее, на расстояния могут сильно влиять различия между осями, по координатам которых вычисляются эти расстояния. К примеру, если одна из осей измерена в сантиметрах, а вы потом переведете ее в миллиметры (умножая значения на 10), то окончательное евклидово расстояние (или квадрат евклидова расстояния), вычисляемое по координатам, сильно изменится, и, как следствие, результаты кластерного анализа могут сильно отличаться от предыдущих.
Шаг 4. После установки всех параметров и нажатия кнопки ОК, переходим в окно Результаты иерархической классификации.
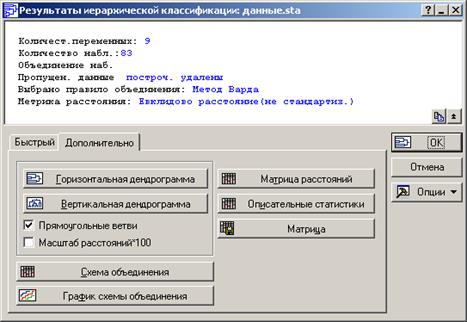
Рисунок 4.28 - Просмотр результатов древовидной кластеризации
 Согласно приведенному рисунку 4.28, выполненная процедура предоставляет исследователю ограниченный набор инструментов анализа результатов. Самым значимым является график результатов, который называется дендограмма (рисунок 4.29).
Согласно приведенному рисунку 4.28, выполненная процедура предоставляет исследователю ограниченный набор инструментов анализа результатов. Самым значимым является график результатов, который называется дендограмма (рисунок 4.29).
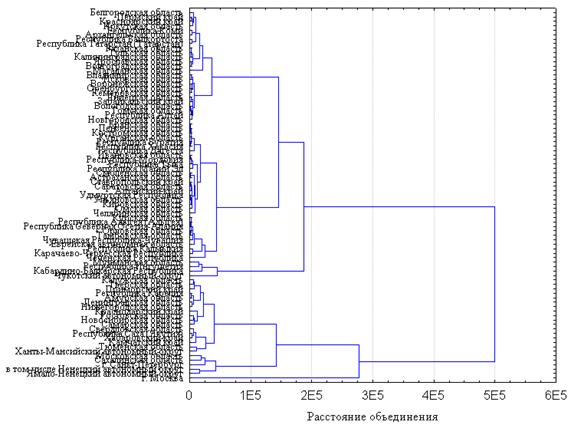
Рисунок 4.29 – Древовидная диаграмма групп субъектов РФ (полная совокупность)
По оси абсцисс расположены субъекты РФ, по оси ординат отражено значение интегрального показателя, представляющее величину, сформированную на основе отобранных показателей. Данный показатель не имеет единицы измерения и является своего рода многомерной статистической оценкой.
В силу наличия значительного количества рассматриваемых объектов читаемость на графике имен единиц очень низкая, поэтому дендограмму можно использовать лишь в качестве «разведочного» анализа для получения предварительной информации о количестве групп на которое необходимо разбить совокупность.
В нашем случае имеем 2 группы, первая заключена между Белгородской областью и Чукотским автономным округом (см. рисунок 4.29 с верху вниз), вторая между Калужской областью и Ненецким автономным округом. Помимо этого наблюдается «выброс» (объект с аномальными значениями) которым является г.Москва, сложившаяся ситуация очевидна, так как данный субъект является финансовым центром страны с большим количеством населения (более 15 млн. чел.). Поэтому в дальнейшем анализе данный город не будет учитываться, соответственно необходимо удалить его из рабочей таблицы.
Определившись с количеством однородных групп (2 группы) переходим к следующей процедуре кластерного анализа.
Шаг 5. В окне Методы кластеризации, укажем Кластеризация методом k средних и нажмем ОК.
Шаг 6. Выберем вкладку Дополнительно, укажем переменные участвующие в анализе и в поле Объекты выделим Наблюдения (строки), после чего нажмем ОК (рисунок 4.30).
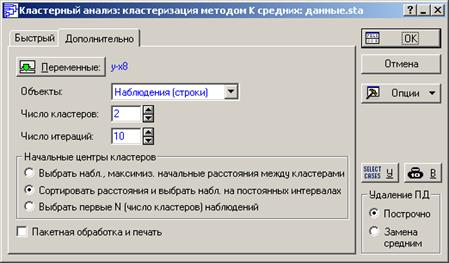
Рисунок 4.30 - Установки процедуры k средних
Шаг 7. В окне Результаты метода k средних представлено заметно большее количество инструментов анализа (рисунок 4.31).
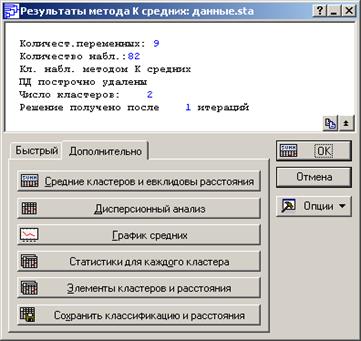
Рисунок 4.31 - Окно результатов процедуры k средних
В первую очередь выберем График средних, который наглядным образом покажет нам различия в кластерах, а также позволит судить о качестве разбиения (рисунок 4.32).
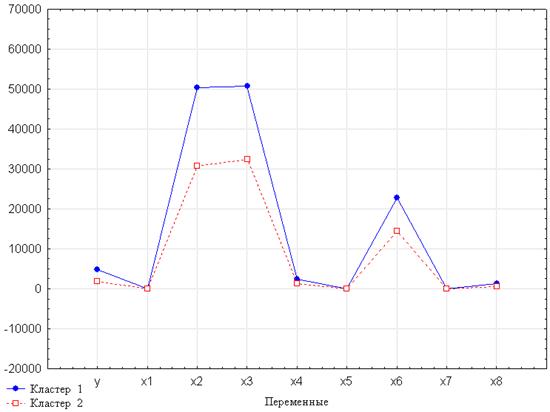
Рисунок 4.32 – Средние по кластерам
Согласно полученному рисунку 4.32, исходная совокупность разделена на два кластерами.
Как видим на графике самый большой 1 кластер (синяя линия) характеризуется максимальными значениями переменных. Соответственно кластер №2 характеризуется минимальными значениями показателей.
Так как средние кластеров по переменным 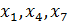 практически совпадают можно предположить о низком качестве разбиения в этих точках. Более точно можно сказать, обратившись к F -статистике Фишера, для ее инициализации необходимо выбрать кнопку Дисперсионный анализ (рисунок 4.33).
практически совпадают можно предположить о низком качестве разбиения в этих точках. Более точно можно сказать, обратившись к F -статистике Фишера, для ее инициализации необходимо выбрать кнопку Дисперсионный анализ (рисунок 4.33).
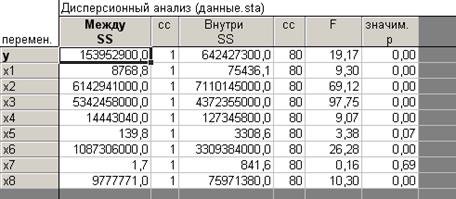
Рисунок 4.33 - Результаты дисперсионного анализа
Уровень значимости указывает на достаточно высокое качество разбиения совокупности на группы, так как значения практически по всем переменных не превышает порог в 0,05, исключением являются переменные 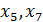 , т.е. по этим переменным не удалось однозначно разделить совокупность на две группы.
, т.е. по этим переменным не удалось однозначно разделить совокупность на две группы.
Шаг 8. Для использования результатов группировки в дельнейших исследованиях необходимо выбрать кнопку Сохранить классификацию и расстояния.
В появившемся окне Выберете перем. для сохранения с класт. идентиф. выделим все переменные участвующие в анализе и нажмем кнопку ОК.
Результатом будет являтся новая таблица содержащая наряду с переменными и номера кластеров в которые попадают изучаемые субъекты федерации (рисунок 4.34, столбец №11).

Рисунок 4.34 - Рабочая таблица с переменными и номерами кластеров
Рекомендуется сохранить полученную таблицу для дальнейшего ее использования в анализе.

