 2015-10-16
2015-10-16 935
935У мультипрограмному (багатопрограмному, багатозадачному) режимі процесор може одразу виконувати кілька програм. При цьому одну окрему задачу процесор виконує так, начебто всіх інших немає. Потреба в такому режимі роботи пов'язана з необхідністю раціонального використання машинного часу процесора. Справа в тому, що при виконанні деяких програм час роботи самого процесора виявляється значно меншим від того часу, що витрачається на процедури введення та виведення даних. Для того, щоб процесор у цей час не простоював, доцільно завантажити його виконанням якоїсь іншої програми. Якщо ж і ця програма дійде до моменту, коли стане потрібним уведення або виведення (а роботу по введенню та виведенню в першій програмі ще не завершено), процесор може перейти до виконання третьої програми тощо.
Таке маневрування з прикладними програмами спрямоване на найбільш раціональне використання машинного часу процесора (так, щоб у його роботі не було простоїв), здійснюється спеціальною системною програмою, що має назву супервізора або програми-
диспетчера.
Для того, щоб краще зрозуміти, як здійснюється в мультипрограмному режимі подібний перехід від одної програми до іншої, розглянемо модельну ситуацію, коли два процесори А та В використовують загальний ресурс, але виконують дві різні програми. Припустимо, що необхідно обміняти місцями програми, які виконуються цими процесорами. Як це зробити?
Стан процесора в будь-який момент часу цілком визначається вмістом робочих і сегментних регістрів, регістра ознак та лічильника команд. Вони показують, яка команда виконується, до якої комірки пам'яті або зовнішнього пристрою звертається процесор і містять іншу важливу та вичерпну інформацію.
Отже, нам треба лише обміняти місцями вміст регістрів обох процесорів: у процесор А передається вміст усіх регістрів процесора В, а в процесор В - відповідні дані від процесора А.
Подібно до цього здійснюється "перемикання задач", наприклад, у процесорі 80386. Після того, як у програмі дається сигнал "вивільнити мікросхему", вміст усіх регістрів переписується в область пам'яті, що має назву сегмента стану задачі (TSS - Taske State Segment). А у вивільнені регістри процесора завантажується вміст іншого TSS, де зберігалась уся інформація про другу програму, якій тепер передається керування процесором. Після цього виконується нова програма, а стара чекає виклику. Таке перемикання можна здійснювати дуже швидко. Наприклад, TSS у процесорі 80386 містить 26 подвійних слів (104 байтів). Перемикання здійснюється за 268 тактів, що при тактовій частоті в 16 МГц складає лише 17 мкс. Отже, якщо один процесор обслуговує, наприклад, одночасно кілька терміналів, то циклічне перемикання програм користувачів може відбуватися багато разів за секунду. Окремий користувач не буде відчувати, що окрім нього є ще й інші користувачі. У нього буде складатися враження, що процесор обслуговує тільки його одного.
При роботі в мультипрограмному режимі можуть виникати певні труднощі з використанням оперативної пам'яті, котра стає тепер уже загальною для кількох задач. Можливі непередбачені ситуації, коли одна програма буде "залізати" в область пам'яті, де розташовані сегменти, що належать іншій програмі. Для запобігання таких ситуацій доводиться вживати заходи щодо захисту записаної інформації від вторгнення чужих програм. Для цього в процесорах, що працюють у мультипрограмному режимі, використовується ціла система захисту та обмеження доступу до записаної в пам'яті інформації.
Окрім цього окремим програмам надаються певні привілеї на позачергове виконання. Ці привілеї враховуються супервізором при наданні програмам машинного часу.
Кеш-пам 'ять
Мабуть, найістотнішою характеристикою електронно-обчислювальної машини є її швидкодія. Вона визначається як процесором, так і оперативною пам'яттю, до якої процесор постійно звертається. У зв'язку з появою нових швидкодіючих процесорів
останніх поколінь виник певний розрив між швидкодією процесора й оперативною пам'яттю, котра стала тепер найповільнішою ланкою в системі процесор - пам'ять.
Справа в тому, що великі об'єми пам'яті, які використовуються в сучасних ЕОМ, засновані на динамічних КМОН-структурах (DRAM), котрі, у принципі, не можуть бути дуже швидкодіючими. Адже в основі їх дії лежить процес зарядження та розрядження ємності, який завжди потребує певного часу. Звичайно, було б краще за все замінити КМОН-структури на більш швидкодіючі статичні ТТЛШ-пристрої (SRAM), але сучасна технологія не спроможна поки що зробити їх порівнянними з КМОН-структурами за розмірами, енергоспоживанням та вартістю.
Тому пішли компромісним шляхом - поруч із великою, але повільно діючою основною пам'яттю стали створювати невелику, але швидкодіючу, у котрій зберігаються найнеобхідніші на даний момент блоки програми. Вміст її весь час поповнюється з основних резервів. Така пам'ять дістала назву кеш-пам'яті. Вона створюється на основі статичних елементів, швидкодія яких узгоджена зі швидкодією процесора.
Концепція кеш-пам'яті базується на передбаченні того, які саме дані вимагатиме процесор при виконанні наступних команд та випереджувальному занесенні цих даних до кеш-пам'яті. Таке завбачення адреси наступного звернення до пам'яті було б неможливим, якщо б програма зверталась до пам'яті випадковим чином. Насправді ж програми мають тенденцію звертатися до пам'яті за адресою, близькою до цдреси попереднього звернення. Це явище має назву локальності програми або локальності посилань. Локальність програм є саме те, що робить кеш-пам'ять можливою та ефективною.
При зверненні до пам'яті процесор звертається спершу до контролера кеш-пам'яті. Якщо в ній є інформація з потрібною адресою, то виграється кілька тактів. Це має назву кеш-потрапляння. Якщо ж потрібної адреси в кеші немає, то доводиться звертатися до основної пам'яті. На невдалому зверненні до кеш-пам'яті (кеш-похибка) втрачається кілька тактів, але тепер потрібна адреса разом із близькими до неї кількома (2 - 16) байтами записується до кеш-пам'яті. Старі ж записи з усіма зробленими в них змінами
повертаються до основної пам'яті за попередніми адресами. Загальний об'єм кеш-пам'яті може складати кілька десятків або навіть сотні кілобайтів.
Добре зроблений кеш може дати майже подвійний виграш у швидкодії. Можна передбачати, що з появою в майбутньому дешевих і компактних швидкодіючих ОЗП потреба в кеш-пам'яті зникне.
Кеш-пам'ять може знаходитись як ззовні процесора й бути окремою ГМС, так і всередині його. Так, наприклад, у процесорі 80486 є внутрішній кеш об'ємом у 8 Кбайтів (так званий перший рівень кешування), а також зовнішній на 256 Кбайтів (другий рівень кешування).
Обмін між кешем та основною пам'яттю може відбуватися двомам методами: наскрізним та зворотним. При наскрізному запис у кеш виконується одночасно зі зміною вмісту комірок як у кеші, так і в основній пам'яті. Цей метод є характерним для внутрішніх кешів. При зворотному узгодження кеша з основною пам'яттю відбувається не одразу. Зміна вмісту комірок кеш-пам'яті викликає встановлення спеціальної ознаки (біта "сміття"). При черговому оновленні вмісту кеша блоки інформації, помічені цим бітом, повертаються в основну пам'ять у першу чергу. Такий механізм звичайно реалізується в кеш-пам'яті другого рівня. Узагалі ж при очищенні кеша в першу чергу видаляється інформація, до якої вже давно не зверталися. Для цього при кожному зверненні відповідна комірка кеша помічається спеціальним бітом ознаки.
Подвоєння тактової частоти процесора
Як уже згадувалось, окрім зовнішнього кеша, що знаходиться поза процесором, у деяких процесорах останніх моделей є ще й внутрішня кеш-пам'ять, що міститься на самому кристалі процесора й має велику швидкодію.
Це дозволяє застосувати ще один метод прискорення роботи системи - подвоєння тактової частоти процесора (і разом із ним внутрішнього кеша) порівняно з тактовою частотою всієї решти ІМС, що входять до складу ЕОМ.
Процесор працює з підвищеною частотою, лише інколи звертаючись до основної пам'яті й зовнішнього кеша, котрі працюють з допустимою для них тактовою частотою. Звичайно,
помноження тактової частоти є можливим лише тоді, коли процесор має досить розвинену внутрішню кеш-пам'ять. Застосування помноження частоти дозволяє збільшити на 60-70 % швидкодію та продуктивність подібних систем.
Черга команд
команд створюються для більш раціонального використання машинного часу блоків процесора так, щоб жоден із них не простоював, очікуючи надходження інформації.
З чергою команд ми вже зустрічалися, розглядаючи структурну схему МП-86. У найпростіших процесорах 8080 та 8085 по закінченні виконання будь-якої команди процесор звертається до пам'яті за наступною командою й поки відбувається вибірка цієї команди та її рух по системній шині, сам процесор простоює.
У МП-86 передбачається випереджувальна вибірка команди. Поки процесор обробляє та виконує чергову команду й системна шина вільна, викликається наступна команда й записується в спеціальний регістр. Отже, до моменту закінчення виконання процесором попередньої команди в нього на вході стоїть уже нова команда (або навіть декілька). У МП-86 таких регістрів шість і в них утворюється черга команд, підготовлених до виконання. Як тільки два байти в регістрах черги вивільнюються, вони заповнюються наступними командами. У результаті АЛЛ уже не доводиться простоювати в очікуванні надходження команди.
Цей принцип так добре себе виправдав, що в мікропроцесорах наступних поколінь таких черг організується декілька. Так, наприклад, після дешифратора команд створюється ще одна черга -тепер уже черга мікрокоманд, готових до виконання процесором. У МП-286 це три 69-розрядні регістри мікрокоманд, а в МП-386 - 8 регістрів по 100 розрядів.
повертаються до основної пам'яті за попередніми адресами. Загальний об'єм кеш-пам'яті може складати кілька десятків або навіть сотні кілобайтів.
Добре зроблений кеш може дати майже подвійний виграш у швидкодії. Можна передбачати, що з появою в майбутньому дешевих і компактних швидкодіючих ОЗП потреба в кеш-пам'яті зникне.
Кеш-пам'ять може знаходитись як ззовні процесора й бути окремою ІМС, так і всередині його. Так, наприклад, у процесорі 80486 є внутрішній кеш об'ємом у 8 Кбайтів (так званий перший рівень кешування), а також зовнішній на 256 Кбайтів (другий рівень кешування).
Обмін між кешем та основною пам'яттю може відбуватися двомам методами: наскрізним та зворотним. При наскрізному запис у кеш виконується одночасно зі зміною вмісту комірок як у кеші, так і в основній пам'яті. Цей метод є характерним для внутрішніх кешів. При зворотному узгодження кеша з основною пам'яттю відбувається не одразу. Зміна вмісту комірок кеш-пам'яті викликає встановлення спеціальної ознаки (біта "сміття"). При черговому оновленні вмісту кеша блоки інформації, помічені цим бітом, повертаються в основну пам'ять у першу чергу. Такий механізм звичайно реалізується в кеш-пам'яті другого рівня. Узагалі ж при очищенні кеша в першу чергу видаляється інформація, до якої вже давно не зверталися. Для цього при кожному зверненні відповідна комірка кеша помічається спеціальним бітом ознаки.
Подвоєння тактової частоти процесора
Як уже згадувалось, окрім зовнішнього кеша, що знаходиться поза процесором, у деяких процесорах останніх моделей є ще й внутрішня кеш-пам'ять, що міститься на самому кристалі процесора й має велику швидкодію.
Це дозволяє застосувати ще один метод прискорення роботи системи - подвоєння тактової частоти процесора (і разом із ним внутрішнього кеша) порівняно з тактовою частотою всієї решти ІМС, що входять до складу ЕОМ.
Процесор працює з підвищеною частотою, лише інколи звертаючись до основної пам'яті й зовнішнього кеша, котрі працюють з допустимою для них тактовою частотою. Звичайно,
помноження тактової частоти є можливим лише тоді, коли процесор має досить розвинену внутрішню кеш-пам'ять. Застосування помноження частоти дозволяє збільшити на 60-70 % швидкодію та продуктивність подібних систем.
Черга команд
команд створюються для більш раціонального використання машинного часу блоків процесора так, щоб жоден із них не простоював, очікуючи надходження інформації.
З чергою команд ми вже зустрічалися, розглядаючи структурну схему МП-86. У найпростіших процесорах 8080 та 8085 по закійченні виконання будь-якої команди процесор звертається до пам'яті за наступною командою й поки відбувається вибірка цієї команди та її рух по системній шині, сам процесор простоює.
У МП-86 передбачається випереджувальна вибірка команди. Поки процесор обробляє та виконує чергову команду й системна шина вільна, викликається наступна команда й записується в спеціальний регістр. Отже, до моменту закінчення виконання процесором попередньої команди в нього на вході стоїть уже нова команда (або навіть декілька). У МП-86 таких регістрів шість і в них утворюється черга команд, підготовлених до виконання. Як тільки два байти в регістрах черги вивільнюються, вони заповнюються наступними командами. У результаті АЛЛ уже не доводиться простоювати в очікуванні надходження команди.
Цей принцип так добре себе виправдав, що в мікропроцесорах наступних поколінь таких черг організується декілька. Так, наприклад, після дешифратора команд створюється ще одна черга -тепер уже черга мікрокоманд, готових до виконання процесором. У МП-286 це три 69-розрядні регістри мікрокоманд, а в МП-386 - 8 регістрів по 100 розрядів.
Конвеєризація адреси
Ще один захід, який дозволяє дещо прискорити роботу процесора, має назву конвеєризації адреси. Він пов'язаний знову ж таки з тим, що швидкодія процесора перевищує швидкість ОЗП і при зверненні до останнього доводиться пропускати один або два такти, очікуючи, поки у відповідь на видану адресу ОЗП виставить на ШД відповідні дані.

Але в тих процесорах, де ША і ШД не мультиплексовані, одержання даних для чергової команди та виставлення адреси для наступної команди можна об'єднати в часі.
Будемо вважати, що час очікування на видачу даних складатиме один такт. Тоді на одне звернення до пам'яті потрібно три такти: видача адреси, очікування та одержання даних (рис. 17.1, а). При конвеєризації адреси на кожне звернення потрібно лише два такти (рис. 17.1,6).
Конвеєризація команд
Цей самий принцип можна застосувати й до команд, якщо для їх виконання використовуються послідовно декілька апаратних блоків. Так, наприклад, нехай таких ступенів виконання буде п'ять: вибірка команди, два ступеня дешифрування, виконання та видача даних (рис. 17.2).. Будемо вважати, що на проходження кожного з цих
ступенів витрачається один такт. Команда проходить послідовно через п'ять пристроїв, кожний з яких відповідає своєму ступеню. Коли вивільнюється перший ступінь, до нього одразу надходить наступна команда. Отже, хоча на виконання кожної команди витрачається п'ять тактів, на вихід системи кожного такту потрапляє результат одної виконаної команди.
Конвеєрна система виконання команд виявляється особливо ефективною, якщо до складу процесора входять виконавчі ступені з жорсткою логікою, які здатні діяти самостійно й автономно, не потребуючи керування з боку мікрокоманд. Таких жорстких виконавчих ступенів може бути декілька й вони можуть працювати
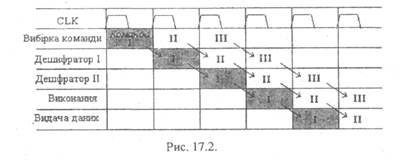
одночасно, паралельно обробляючи декілька команд.
Узагалі сучасні потужні процесори поділяються на два основні класи:
- векторні, що виконують багато обчислень одночасно й паралельно, завдяки своїй багатопроцесорній структурі;
- скалярні, які обробляють команди послідовно. Проміжними між ними є так звані суперскалярні процесори, що
вважаються підкласом скалярних. Вони здатні обробляти декілька команд одночасно, завдяки тому, що в їх структурі є кілька жорстких конвеєрів.
Динамічне виконання (оптимізуюча компіляція)
Але навіть при конвеєризації команд та наявності кеш-пам'яті неповна зайнятість процесора залишається проблемою.
Дійсно, при кеш-похибці повинно відбуватися перезавантаження кеша й процесор має чекати кілька тактів, доки перезавантаження відбудеться та процесор одержить потрібні дані. Ідея динамічного виконання полягає в тому, щоб процесор у цей час не простоюяв, а виконував наступні команди, котрі повністю забезпечені наявним вмістом кеша та робочих регістрів. Розглянемо як приклад такий фрагмент програми:
(1) Rl <— KESHMEMR ^завантаження робочого регістра R1 з кеша
(2) R2 <- R2 + R1;додавання R1 і R2
(3) R5<-R5 + 1;інкрементК5
(4) R6 <- R6 - R3;віднімання R3 з R6.
При виконанні першої з команд (завантаження робочого регістра R1 з кеша) може відбутися кеш-похибка. Звичайний процесор буде змушений простоювати, аж поки шинний інтерфейс не прочитає потрібні дані з основної пам'яті та не завантажить їх у кеш. Тільки тоді можна буде виконати команди (1) та (2). Але наступні команди (3) та (4) можна виконувати, бо регістри R3, R5 та R6 уже завантажені й для цього не потрібний кеш і його даними. Отже, процесор, не чекаючи виконання команд (1) та (2), може виконати команди (3) та (4) і надіслати їх результати на тимчасове зберігання в область пам'яті, що має назву пула команд. Там вони перебуватимуть доти, доки не виникне потреба повернути їх у порядку природної черговості програми. Отже, процесор виконує команди не в порядку їх запису в програмі, а відповідно до їх готовності для обробки. У сучасних процесорах такий "перегляд уперед" відбувається на 20 - ЗО команд щодо існуючого на даний момент стану лічильника команд. Він здійснюється за допомогою оптимізуючих компіляторів, які аналізують вхідні коди й частково змінюють порядок виконання команд. Динамічне виконання є ще одним засобом узгодження швидкодії процесора й пам'яті (на цей раз кеш-пам'яті), що дозволяє істотно збільшити швидкодію ЕОМ у цілому. Цей метод уже давно застосовувався у великих машинах і RISC-процесорах. Зараз він знайшов застосування й у процесорах останніх поколінь.








