 2015-10-22
2015-10-22 2862
2862Во время конструирования абстрактных представлений данных важно различать, является структура данных статической или динамической, то есть меняется ли со временем ее форма и размер. Например, если конструируемый абстрактный инструмент — это список имен, важно решить, останется ли его размер фиксированным на все время существования списка или он будет уменьшаться и увеличиваться с удалением и добавлением имен.
В целом, статическими структурами (static structure) проще управлять, чем динамическими (dynamic structure). Если структура статическая, нам необходимо только обеспечить способы доступа к различным элементам данных и, возможно, способы изменения значений элементов, находящихся на определенных местах. Но в случае динамической структуры также необходимо решать проблемы добавления и удаления элементов данных и поиска пространства в памяти для увеличения размера структуры. Излишнее разрастание плохо организованной структуры может привести к тому, что она целиком будет копироваться в другую, большую по размерам область памяти — а для этого требуется много времени.
Указатели
Вспомните, что ячейки в оперативной памяти машины идентифицируются числовыми адресами. Эти числовые значения можно также хранить в ячейках памяти. Указатель (pointer) — это ячейка (или блок ячеек) памяти, содержащая адрес другой ячейки памяти. Применительно к структурам данных, указатели используются для записи адресов элементов данных. Таким образом, элемент данных может храниться в какой-либо ячейке памяти, а адрес этой ячейки — в указателе, при помощи которого можно позже получить эти данные. То есть значение указателя сообщит нам, где искать данные. В некотором смысле указатель указывает на данные, отчего и получил такое название.
Мы уже встречались с концепцией указателей в контексте счетчика команд процессора, который содержит адрес очередной инструкции для выполнения. Фактически, другое название счетчика команд — указатель команд (instruction pointer). Адреса, также называемые URL, которые используются для связи гипертекстовых документов, также могут служить примером концепции указателей, но они указывают местоположения в сети Интернет, а не в оперативной памяти компьютера.
Во многих современных языках программирования указатели включены в набор основных типов данных. Можно объявлять, выделять память и манипулировать указателями так же, как целыми числами или строками. При помощи такого языка программист может создавать развитые сети элементов данных в памяти машины, где каждый блок ячеек памяти содержит указатели на другие блоки. Следуя указателям, можно проследить эти пути от блока к блоку.
В качестве примера давайте представим, что в компьютерной памяти хранится список рассказов, отсортированный в алфавитном порядке по названию. Такая организация удобна во многих приложениях, но одновременно затрудняет поиск всех рассказов, написанных одним автором, так как они беспорядочно разбросаны по списку. Для решения этой проблемы можно зарезервировать в каждом блоке ячеек памяти, представляющем один рассказ, отдельную ячейку типа указатель. Тогда в каждом из этих указателей можно хранить адрес другого блока, представляющего произведение того же автора, и все рассказы одного автора будут связаны в замкнутую цепь (рис. 7.1). Отыскав один рассказ заданного автора, мы можем найти и все остальные, переходя по указателям от книги к книге.

Массивы
В главе 5 мы узнали, что многие языки высокого уровня позволяют программисту разрабатывать алгоритм так, как если бы необходимые данные хранились в прямоугольной структуре, называемой однородным массивом, где термин «однородный» означает, что все элементы массива принадлежат одному типу. В этом разделе мы изучим, как же на самом деле организованы такие массивы, и как транслятор преобразует массив, найденный в исходной программе, в термины ячеек памяти и адресов.
Представьте, что алгоритм для обработки суточных замеров температуры написан на языке высокого уровня. Программисту удобно представлять эти показания в виде одномерного массива с названием Readings, ссылки на элементы которого зависят от их положения в списке. Тогда к первому показателю можно обращаться как к Readings[l], ко второму — как к Readings[2] и т. д. (В языках программирования С, C++, С# и Java эти обращения будут выглядеть как Readi ngs [0] и Readi ngs [1], но нам удобнее нумеровать элементы массива, начиная с единицы. Это преобразование выполняется однозначно — см. вопрос 4 в «Вопросах и упражнениях» в конце раздела.)
Переход от этого одномерного массива к фактической организации данных в памяти машины очень прост, так как данные могут храниться в 24 последовательных ячейках памяти в том же порядке, в каком видит элементы массива программист. Зная адрес первой ячейки последовательности, транслятор может преобразовывать такие ссылки, как Readi ngs [4], в соответствующие термины памяти. Он просто вычитает единицу из индекса нужного элемента и прибавляет результат к адресу ячейки памяти, содержащей первое значение температуры. Если первый показатель находится по адресу х (рис. 7.2), четвертый будет найден по адресу х + (4 - 1).

Теперь представим, что программист планирует написать программу для обработки продаж отдела сбыта компании за неделю. Эти данные можно представить в виде таблицы, где в левом столбце перечислены имена сотрудников отдела, а в верхней строке — дни недели. Следовательно, программисту удобно представить данные в программе как двумерный массив, каждая строка которого обозначает продажи, осуществленные определенным сотрудником, а значения в столбце — это все продажи, сделанные в один день.
Память машины организована не как таблица, а скорее как цепочка ячеек с последовательными адресами. Поэтому требуемую прямоугольную структуру массива придется имитировать. Чтобы сделать это, представим, что массив статичен, то есть его размер не изменяется по мере внесения изменений в данные. Теперь подсчитаем объем памяти, необходимый для всего массива, и зарезервируем непрерывный блок ячеек памяти полученного размера. Начиная с первой ячейки этого блока, последовательно в каждую ячейку записываем значения из первой строки массива; после первой строки таким же образом записываем вторую, третью и т. д. (рис. 7.3). Такая система хранения называется построчной (row major order), в отличие от постолбцовой (column major order), где один за другим записываются все столбцы массива.
Давайте теперь подумаем, как найти ячейку памяти, содержащую значение на пересечении третьей строки и четвертого столбца массива, если данные организованы подобным образом. Представим себя на месте первой ячейки зарезервированного блока машинной памяти. Начиная с этого положения, можно найти данные первой строки массива, за ней второй, третьей и т. д. Для получения данных третьей строки необходимо пройти первую и вторую строки. Так как в каждой строке содержится по пять элементов (по одному на каждый день с понедельника по пятницу), мы пройдем 10 ячеек и окажемся на первом элементе третьей строки. С этого места нам придется пропустить еще три элемента, чтобы попасть на четвертый столбец массива. Итого, для достижения элемента из третьей строки и четвертого столбца мы проходим 13 элементов от начала блока.

Упомянутые ранее расчеты можно обобщить на случай процесса, при помощи которого транслятор преобразует ссылки в терминах положения в строке и столбце в фактические адреса памяти. В частности, пусть с представляет количество столбцов в массиве (то есть количество элементов в каждой строке), тогда адрес элемента на пересечении г-й строки hj'-го столбца:
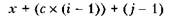
где х — адрес ячейки, содержащей элемент на пересечении первой строки и первого столбца. Таким образом, для достижения i-й строки нам нужно пропустить i - 1 строк, в каждой из которых с элементов, а затем для достижения j-vo элемента в этой строке — еще j — 1 элементов. В предыдущем примере с = 5, г = 3 и j = 4, поэтому, если первый элемент массива находится по адресу х, элемент из третьей строки и четвертого столбца будет находиться по адресу

(Выражение (с х (г - 1)) + (/' - 1) иногда называют адресным полиномом (address polynomial).)
Зная этот алгоритм, можно написать приложение для преобразования запросов в виде номеров строк и столбцов в адреса внутри блока памяти, содержащего массив. Например, транслятор при помощи этой техники преобразует запросы вида Sales[2.4] в фактические адреса памяти. А программист тем временем может представлять данные в табличной форме (абстрактная структура), даже если на самом деле они хранятся в одной строке (фактическая структура).
Списки
Список — это набор записей, выстроенных в определенной последовательности. Примерами могут служить список учащихся класса, список дел на день или словарь. Менее очевидные примеры — это предложения, которые можно рассматривать как последовательности слов, и слова, состоящие из последовательностей букв. В отличие от однородных массивов, имеющих статическую природу1, списки могут быть как статическими, так и динамическими. В этом разделе мы узнаем об особенностях, возникающих при реализации динамического списка в сравнении со статическим.
Непрерывные списки
Рассмотрим способы хранения списков имен в оперативной памяти компьютера. Одна из стратегий — это запись всего списка в один блок ячеек памяти с последовательными адресами. Предположив, что в каждом имени не более восьми букв, мы можем разделить большой блок ячеек на подблоки, содержащие по восемь ячеек. В каждом подблоке можно хранить имя, записав его в кодах ASCII и используя для каждой буквы одну ячейку. Если длины имени не хватает для заполнения всех ячеек в выделенном для него подблоке, оставшиеся ячейки можно заполнить кодом ASCII для пробела. Этот подход требует 80 последовательных ячеек памяти для хранения списка из 10 имен.








