2015-10-22
2015-10-22 510
510Во время написания программы программисту часто приходится решать, реали-зовывать ли список в виде непрерывной или связной структуры. После того как решение принято и список создан, программист должен оставить эти вопросы и сконцентрироваться на прочих деталях. Вкратце, программа должна быть сконструирована так, чтобы к списку можно было обратиться как к абстрактному инструменту из любой части программы.
Возьмем задачу разработки приложения для обработки и регистрации списков студентов, предназначенную для секретаря университета. Программист, занимающийся этой задачей, может создать для каждой группы отдельные списки имен студентов, отсортированные в алфавитном порядке. Как только списки созданы, внимание программиста должно быть обращено на общие концепции задачи, и он не должен постоянно отвлекаться на такие детали, как смещение элементов в непрерывном списке или перемещение указателей в связном списке.
С этой целью программист может написать набор процедур, выполняющих такие действия, как добавление новой записи, удаление старой записи, поиск записи или печать списка, а затем использовать эти процедуры в приложении для управления списками регистрационной системы. Например, чтобы поместить студента J. W. Brown в группу Physics 208, программист может написать оператор такого типа:
Insert ("Brown. J.W.". Physics208)
и передать ответственность за выполнение действий по вставке элемента процедуре Insert. Таким же образом программист будет разрабатывать другие части программы, не сосредотачиваясь на технических подробностях добавления элементов.
Примером такого подхода может служить процедура PrintList (листинг 7.1), предназначенная для печати связного списка имен. На первую запись списка указывает указатель головы; каждая запись состоит из двух частей: имени и указателя на следующую запись. После того как такая процедура написана, ее можно использовать как абстрактный инструмент для печати списков и не думать о шагах, которые фактически предпринимаются для выполнения этой операции. Например, чтобы распечатать список группы Economics 301, программист напишет: PrintList CEconomics301) Листинг 7.1. Процедура печати связного списка
procedure PrintList (List)
CurrentPointer <- указатель головы списка List.
while (CurrentPointer не NIL) do
(Печать имени из элемента списка, на который указывает CurrentPointer: Считывание указателя из элемента списка List, на который указывает CurrentPointer. и присваивание этого значения CurrentPointer.)
Стеки
Одним из свойств списка, делающих связную структуру более привлекательной по сравнению с непрерывной, является простота добавления и удаления записей внутри списка. Вспомните, что в случае непрерывного списка для выполнения этой операции могло понадобиться смещение всего массива имен для заполнения или создания свободного места. Если же разрешить добавление и удаление только в начале и конце структуры, то использовать смежную структуру становится удобнее. Примером такой структуры является стек (stack), то есть список, в котором элементы добавляются и удаляются только на одном конце. Следствием такого ограничения является то, что последний добавленный элемент всегда будет удален первым — из-за этого стеки называют структурами LIFO (last-in, first-out, последним прибыл — первым убыл).
Тот конец стека, где добавляются и удаляются элементы, называется вершиной стека (top). Другой конец часто называют основанием стека (stack's base). Чтобы отразить тот факт, что доступ к стеку ограничен верхней записью, мы используем для обозначения операций добавления и удаления специальные термины. Процесс добавления объекта в стек называется проталкиванием (push), а процесс удаления — выталкиванием (pop). To есть запись проталкивается в стек или выталкивается из него.
Откат
Классическое применение стека можно наблюдать, когда программный модуль запрашивает выполнение процедуры. Для выполнения этого запроса компьютер должен передать управление процедуре; затем, когда процедура выполнится, компьютеру необходимо вернуться к тому месту в программном модуле, откуда был сделан запрос. Таким образом, для осуществления передачи управления должен существовать механизм запоминания местоположения, куда управление будет затем возвращено.
Ситуация усложняется тем, что сама процедура может запросить выполнение другой процедуры, которая, в свою очередь, вызовет еще одну и т. д. (рис. 7.8). Следовательно, накапливаются местоположения, которые необходимо запомнить, чтобы вернуть туда управление. После того как выполнены все процедуры, управление должно быть возвращено к должному месту программного модуля, который вызвал первую процедуру. Таким образом, точки возврата должны сохраняться в системе и затем восстанавливаться в правильном порядке.
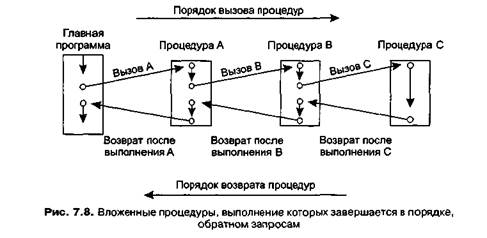
Стек — это идеальная структура для такой системы. При вызове каждой процедуры указатель на соответствующую точку возврата проталкивается в стек. Затем, по завершении очередной процедуры, выталкивается верхняя запись стека, причем гарантируется возврат к правильному месту в программе.
Этот пример наглядно иллюстрирует общую идею приложений, использующих стеки, так как он демонстрирует отношения между стеками и процессом отката. Под термином «откат» (backtracking) мы понимаем поиск выхода из ситуации путем выполнения действий, которые привели нас туда, в обратном порядке. Классический пример — это оставление следов в лесу, следуя по которым в обратную сторону, можно вернуться в исходную точку. Этими следами являются системы LIFO, и поэтому концепция стеков воплощается во всех процессах, где выход из системы производится в порядке, обратном входу.
Приведем другой пример. Предположим, что нам необходимо напечатать имена, собранные в связный список (описанный в разделе 7.2), в обратном порядке, то есть чтобы последнее имя напечаталось первым. Но вызывает трудность то, что получить доступ к именам можно, только пройдя по связной структуре. Следовательно, нам требуется способ хранения каждого полученного имени до тех пор, пока все следующие за ним имена не будут получены и напечатаны. Решить эту проблему можно, пройдя список от начала до конца, одновременно проталкивая найденные имена в стек. Когда мы достигнем конца списка, то начнем выталкивать имена из стека и печатать их (рис. 7.9). Процедура решения приведена на листинге 7.2.
Листинг 7.2. Процедура печати связного списка в обратном порядке с использованием вспомогательного стека
procedure ReversePrint (List)
CurrentPointer <- указатель головы списка List
while (CurrentPointer не NIL) do
(push (проталкивание) имени из элемента, на который указывает CurrentPointer. в стек:
Считывание указателя из элемента списка List, на который указывает CurrentPointer,
и присваивание этого значения CurrentPointer.) while (стек не пустой) do
(pop (выталкивание) имени из стека и печать.)

Реализация стека
Для реализации стека в компьютерной памяти обычно резервируют блок смежных ячеек памяти достаточного размера, чтобы вместить стек с учетом его увеличения или уменьшения. (Решение о размере этого блока зачастую является критическим. Если зарезервировано слишком мало места, в конечном итоге размер стека превысит размер выделенного пространства; если зарезервировано слишком много места, оно не будет полностью использовано.) Один из концов блока обозначен как основание стека. Здесь хранится первая протолкнутая в стек запись, а все остальные помещаются за ней, и стек растет по направлению к другому концу зарезервированного блока.
Таким образом, по мере проталкивания и выталкивания записей вершина стека перемещается вперед и назад в пределах зарезервированного блока ячеек памяти. Для того чтобы отслеживать положение вершины, ее адрес хранится в дополнительной ячейке памяти, называемой указателем стека (stack pointer). To есть указатель стека — это указатель на вершину стека.
Система стека работает следующим образом (рис. 7.10): для того чтобы протолкнуть в стек новую запись, значение указателя стека переопределяется — теперь он указывает на свободное место за вершиной стека. Затем на это место записывается новый элемент. Чтобы вытолкнуть элемент из стека, мы считываем данные, на которые указывает указатель стека, а затем переопределяем этот указатель, чтобы он указывал на предыдущую запись в стеке.

Как и для списков, программисту, очевидно, будет удобнее написать процедуры для выполнения операций проталкивания и выталкивания и использовать стек как абстрактный инструмент. Обратите внимание, что эти процедуры должны обрабатывать такие случаи, как попытки выталкивания записей из пустого стека и проталкивания элементов в полный стек. Таким образом, полная система стека предполагает наличие процедур для проталкивания и выталкивания записей, а также для проверки, пуст ли стек и есть ли в нем свободные места.
Между абстрактной структурой и фактической организацией в памяти стека, реализованного в виде блока смежных ячеек памяти, практически нет различий. Но допустим, что предсказать максимальный размер стека и зарезервировать точно подходящий по размеру фиксированный блок памяти невозможно. Решить эту проблему можно, реализовав стек в виде связной структуры, похожей на ту, которую мы рассматривали в разделе 7.2. Таким образом, можно обойти ограничения, налагаемые фиксированным размером блока памяти, так как записи стека будут размещены в различных, даже в самых маленьких свободных областях памяти. Но в этом случае абстрактная структура стека будет отличаться от фактической организации его в памяти.
Очереди
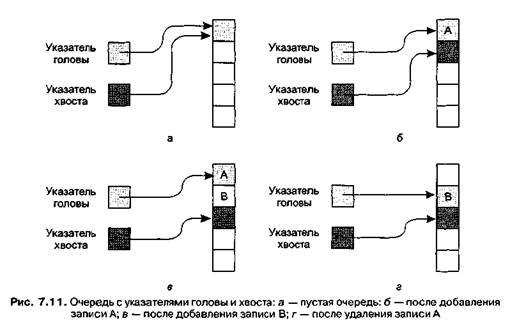
В противоположность стеку, где вставка и удаление производятся на одном и том же конце, очередь (queue) — это список, в который записи добавляются с одной стороны, а удаляются с другой. Мы уже встречались с этой структурой, обсуждая очереди в главе 3, где определили их как системы хранения типа FIFO (first-in, first-out, первым прибыл — первым обслужен). В действительности концепция очередей обязательно присутствует в любой системе, где объекты обслуживаются в порядке поступления. Концы очереди получили свои названия по аналогии с очередью ожидания. Тот конец, откуда записи удаляются, называется головой (head) (или началом) очереди, так же как в кафе мы можем сказать, что следующим будет обслужен человек, стоящий в начале очереди. Аналогично, конец, куда добавляются записи, называется хвостом очереди (tail).
Можно реализовать очередь в памяти компьютера в блоке смежных ячеек, схожим со стеком образом. Так как нам необходимо производить операции на обоих концах структуры, то, в отличие от стека, где требуется одна дополнительная ячейка, здесь мы отдельно заводим еще две ячейки памяти для использования в качестве указателей. Один из них, называемый указателем головы, предназначен для отслеживания головы очереди; другой, указатель хвоста, предназначен для хвоста очереди. Если очередь пуста, оба указателя указывают на одно и то же место в памяти (рис. 7.11). Новая запись помещается по адресу, содержащемуся в указателе хвоста, а затем значение этого указателя изменяется на адрес следующего свободного места в памяти. Таким образом, указатель хвоста всегда указывает на первое свободное место в очереди. Для удаления записи из очереди необходимо считать значение, на которое указывает указатель головы, а затем изменить его значение, чтобы он указывал на запись, следующую за удаленной.
С этой системой хранения связана другая проблема. Если не управлять очередью, она постепенно будет перемещаться по памяти, как ледник, разрушая остальные данные на своем пути (рис. 7.12). Это движение является результатом «эгоцентричного» правила добавления новых элементов путем размещения их рядом с предыдущим и соответствующего переопределения указателя хвоста. Если добавить достаточно записей, хвост очереди, в конце концов, доберется до конца машинной памяти.

Причиной такого расходования памяти является не размер очереди, а недостаток ее реализации. (Для небольшой, но часто изменяющейся очереди может потребоваться больше машинной памяти, чем для большой, но практически неподвижной.) Можно решить эту проблему, перемещая элементы очереди вперед при каждом удалении записей из ее начала, так же как в очереди к театральной кассе люди делают шаг вперед, как только первый человек приобретает свои билеты. Но этот подход не эффективен в компьютерной технологии, так как требует массовых перемещений данных.
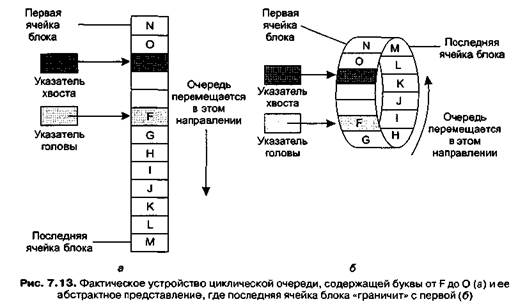
Наиболее распространенный способ управления очередью в памяти компьютера состоит в выделении блока памяти, с одного края которого очередь начинается и перемещается к концу блока. Затем, когда хвост очереди достигает конца блока, мы просто начинаем добавлять записи в начало этого блока, где к этому времени освобождается место. Когда последняя запись в блоке станет головой очереди и будет удалена, головной указатель переместится обратно к началу блока, куда были добавлены новые записи, ожидающие обработки. Таким образом, очередь как бы ходит по кругу внутри одного блока, а не перемещается по всей памяти компьютера.
Этот способ реализации называется циклической очередью (circular queue), так как образуется цикл из ячеек памяти, выделенных для очереди (рис. 7.13). С точки зрения этой очереди последняя ячейка в блоке соседствует с первой.
Необходимо еще раз обратить внимание на разницу между абстрактной структурой, как ее представляет пользователь, и фактической циклической структурой, реализованной в памяти машины. Как и в случае с предыдущими структурами, программное обеспечение скрывает эти различия. То есть помимо набора ячеек памяти, в которых хранятся данные, реализация очереди должна включать в себя несколько процедур для добавления и удаления записей из очереди и определения, пуста очередь или заполнена. Тогда программист, работающий с другим программным модулем, сможет производить вставку и удаление записей при помощи этих процедур, не думая о деталях организации очереди в памяти.
Проблема указателей
Также как использование блок-схем привело к созданию запутанных алгоритмов (глава 4), а бессистемное употребление оператора goto — к появлению плохо спроектированных программ (глава 5), необдуманное использование указателей может служить причиной излишней сложности и подверженности структур данных ошибкам. Чтобы внести порядок в этот хаос, многие языки программирования ограничивают гибкость указателей. Например, в языке Java указатели в общей форме запрещены. Вместо этого он разрешает использование ограниченной формы указателей, называемой ссылкой. Одно из различий состоит в том, что ссылку нельзя изменить, применив арифметическую операцию. То есть если Java-программист захочет переместить ссылку Next на следующую запись в непрерывном списке, ему придется использовать оператор типа переназначить Next на следующую запись списка тогда как С-программист может применить оператор, эквивалентный следующему: присвоить Next значение Next + 1
Обратите внимание, что оператор Java лучше отражает желаемую цель. Более того, для успешного выполнения оператора Java в списке должна существовать еще хотя бы одна запись, а в случае, если Next уже указывает на последнюю запись списка, оператор С приведет к тому, что Next будет содержать адрес каких-то не относящихся к списку данных — эту ошибку часто делают начинающие и даже опытные С-программисты.
Деревья
Последняя структура данных, с которой мы познакомимся, — это деревья (tree), которыми являются организационные диаграммы типичных компаний (рис. 7.14). Здесь президент находится на вершине, от которой отходят линии к вице-президентам, за которыми следуют региональные менеджеры и т. д. Чтобы дать интуитивное определение дерева, мы наложим дополнительное ограничение, состоящее в том (в терминах организационной диаграммы), что ни один сотрудник компании не подчиняется двум разным начальникам. То есть разные ветви организации не сливаются на нижнем уровне.


Каждый элемент дерева называется узлом (node) (рис. 7.15). Узел, находящийся наверху, называется корневым (root node). Если перевернуть рисунок вверх ногами, этот узел будет находиться на месте основания или корня дерева. Узлы на противоположном конце дерева называются терминальными (terminal node) (или листовыми). Если мы выберем любой нетерминальный узел дерева, то обнаружим, что он вместе с узлами, находящимися ниже, также образует дерево. Эти меньшие структуры называются поддеревьями (subtrees). Иногда мы рассматриваем структуру деревьев так, как если бы каждый узел порождал узлы, находящиеся сразу же под ним. Так определяются предки и потомки. Потомки узла называются дочерними узлами (children), а его предок —родителем (parent). Узлы, имеющие одного и того же родителя, называются братьями (siblings). И, наконец, можно определить глубину дерева (depth) как количество узлов в наиболее длинном пути от корня до листа. Другими словами, глубина дерева — это количество горизонтальных уровней в нем.
В следующих главах мы часто будем встречаться с деревьями, поэтому сейчас нет необходимости работать над приложениями. Далее в этом разделе и во время обсуждения организации индексов в главе 8 мы увидим, что данные, в которых требуется проводить быстрый поиск данных, часто организованы в виде дерева, а в главе 10 узнаем, как можно проанализировать игру в терминах деревьев.
Реализация дерева
Для обсуждения способов хранения деревьев мы ограничимся бинарными деревьями (binary tree), то есть деревьями, где у каждого узла может быть максимум два потомка. Подобные деревья обычно хранятся в памяти при помощи связной структуры, похожей на связные списки. Но в этом случае каждая запись (или узел) бинарного дерева состоит не из двух компонентов (данные и указатель на следующую запись), а из трех: (1) данные, (2) указатель на первого потомка узла и (3) указатель на второго потомка узла. Хотя в компьютере не различаются лево и право, полезно считать первый указатель указателем на левого потомка, а второй — указателем на правого потомка, отображая таким образом способ рисования дерева на бумаге. Каждый узел дерева представлен небольшим непрерывным блоком ячеек памяти, формат которых показан на рис. 7.16.

Хранение дерева в памяти включает поиск свободных блоков ячеек памяти для записи узлов и связывание этих узлов согласно желаемой структуре дерева. Это означает, что в каждый указатель должен быть записан адрес левого или правого потомка соответствующего узла, или ему должно быть назначено значение NIL, если в этом направлении дерева более нет узлов. Таким образом, терминальный узел отличается тем, что значения обоих его указателей равны NIL. Наконец, перейдем к специальному месту в памяти, называемому корневым указателем (root pointer), где хранится адрес корневого узла. При помощи корневого указателя осуществляется первоначальный доступ к дереву.
Концептуальная схема структуры бинарного дерева существенно отличается от возможной схемы фактической организации дерева в компьютерной памяти (рис. 7.17). Обратите внимание, что в действительности узлы в оперативной памяти компьютера расположены не так, как на абстрактной схеме дерева. Блоки памяти, представляющие отдельные узлы, могут быть разбросаны по достаточно большой области памяти. Однако, следуя корневому указателю, мы всегда можем найти корневой узел и от него проследить любой путь вниз по дереву, проходя по соответствующим указателям от узла к узлу.

Альтернативой связной системе хранения бинарных деревьев является способ выделения непрерывного блока ячеек памяти, запись корневого узла в первые ячейки (для простоты предполагаем, что для хранения каждого узла дерева требуется одна ячейка памяти), запись левого потомка корневого узла во вторую ячейку, правого потомка — в третью и т. д. Общая концепция этого метода — левый и правый потомки узла, находящегося в ячейке п, записываются в ячейки 2п и 2п + 1 соответственно. Ячейки блока, в которых не хранятся узлы текущей структуры дерева, помечены определенным набором битов, указывающим отсутствие данных. На рис. 7.18 показано, как будет храниться дерево
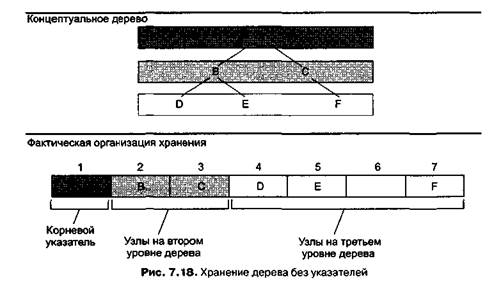
с использованием этого способа. Обратите внимание, что узлы, находящиеся на одном уровне, записываются друг за другом одним блоком. Таким образом, первой записью в блоке является корневой узел, за ним — потомки корневого узла, затем — внуки корневого узла и т. д.
Сбор мусора
С добавлением и удалением данных в динамические структуры занимается и освобождается пространство для хранения. Процесс восстановления незадействованного пространства для будущего использования называется сбором мусора. Сбор мусора требуется в различных условиях. Диспетчер памяти в операционной системе должен производить сбор мусора по мере выделения и восстановления пространства в памяти. Диспетчер файлов проводит сбор мусора во время записи и удаления файлов с носителей компьютера. Более того, любому процессу, выполняющемуся под управлением диспетчера, может понадобиться произвести сбор мусора в пределах выделенного ему пространства в памяти.
В процессе сбора мусора есть несколько коварных проблем. В случае связных структур при каждом изменении значения указателя на элемент данных сборщик мусора должен решать, нужно ли восстанавливать область памяти, на которую ранее указывал этот указатель. Проблема усложняется в переплетенных структурах данных, включающих множество путей указателей. Неправильная работа сборщика мусора может привести к потере данных или к неэффективному использованию пространства хранения. В частности, если сборщик не будет восстанавливать пространство, доступное место в памяти будет постепенно сокращаться; этот процесс называется утечкой памяти (memory leak).

В отличие от описанной ранее связной системы, эта альтернативная система хранения обеспечивает удобный способ поиска родителей или братьев каждого узла. (Конечно, это можно сделать и в связной структуре, задействовав дополнительные указатели.) Положение родителя узла определяется путем деления адреса этого узла на 2 без учета остатка (родитель узла по адресу 7 — это узел по адресу 3). Если узел находится на четном месте, для поиска его брата нужно добавить 1 к адресу этого узла, а если на нечетном — отнять единицу (брат узла на 4 позиции — это узел на 5 позиции; брат узла на 3 позиции — это узел на 2 позиции). Помимо этого такая система хранения предполагает эффективное использование пространства, если бинарные деревья практически сбалансированы (то есть оба поддерева, находящиеся ниже корневого узла, имеют одинаковую глубину) и полные (в деревьях нет длинных тонких ветвей). Если же деревья не отвечают этим характеристикам, такая система станет довольно неэффективной (рис. 7.19).