2015-10-22
2015-10-22 694
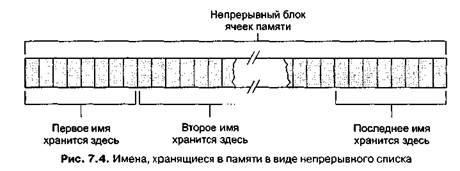
694Примитивы для конструирования и манипуляции массивами, предлагаемые в большинстве языков программирования высокого уровня, являются также удобными инструментами для создания и работы с непрерывными списками. Если все элементы списка принадлежат одному примитивному типу данных, тогда список — это не что иное, как одномерный однородный массив. Рассмотренный в этом разделе список из десяти имен, каждое из которых не длиннее восьми символов, представляет более сложный пример. В таком случае программист может создать непрерывный список в виде двумерного массива символов, состоящего из десяти строк и восьми столбцов, размещение которого в непрерывном блоке оперативной памяти показано на рис. 7.4 (мы предполагаем, что массив хранится построчно).
Во многих языках программирования высокого уровня есть возможности для подобной реализации списков. Например, в описанном ранее двумерном массиве символов MemberList выражение MemberList[3,5] будет относиться к одному символу на пересечении третьей строки и пятого столбца, но в некоторых языках выражение MemberList[3] используется для обращения ко всей третьей строке, являющейся третьей записью в списке.
Важно заметить, что весь список в соответствии с описанной выше системой хранения располагается в одном большом блоке памяти (рис. 7.4), и элементы списка записаны один за другим в последовательные ячейки памяти. Такая организация данных называется непрерывным списком (contiguous list).
Непрерывный список — это удобная структура хранения для реализации статических списков, но у него есть недостатки, делающие его не слишком подходящим для динамических случаев. Предположим, например, что нам потребовалось удалить имя из непрерывного списка. Если имя находится в начале списка, и мы хотим сохранить существующий порядок в списке (например, алфавитный), придется переместить все имена, стоящие за удаленным, ближе к началу списка, чтобы закрыть отверстие, появившееся при удалении. Более серьезная проблема появляется с необходимостью добавления имен, поскольку может потребоваться переместить весь список для освобождения непрерывного блока ячеек, достаточного для расширения списка.
Связные списки
Проблем, возникающих при работе с динамическими списками, можно избежать, разрешив хранение отдельных имен в различных областях памяти, а не вместе, в одном большом непрерывном блоке. Чтобы разобраться в этом, вернемся к нашему примеру хранения списка имен, каждое из которых не длиннее восьми символов. Можно хранить каждое имя в блоке из девяти смежных ячеек памяти. Первые восемь необходимы для записи самого имени, а последняя ячейка будет использоваться как указатель на следующее имя в списке. Следуя этому принципу, список можно раскидать по небольшим блокам, каждый из 9 ячеек, которые связаны между собой указателями. Из-за такой системы связей подобная организация называется связным списком (linked list).
Для того чтобы определить начало связного списка, отдельно определяется еще один указатель, в котором хранится адрес первой записи. Так как этот указатель указывает на начало, или голову списка, он называется указателем головы (head pointer).
Для определения конца связного списка мы используем пустой указатель (NIL pointer), который является просто определенного вида набором битов и находится в последней записи, указывая, что за ним в списке более нет элементов. Например, если мы условимся никогда не хранить элементы списка по адресу О, значение 0 никогда не будет являться разрешенным значением указателя, и поэтому его можно использовать как пустой указатель.
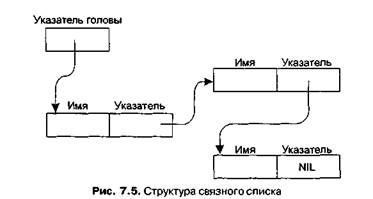
На диаграмме (рис. 7.5) отдельные блоки памяти, в которых хранятся элементы связного списка, представлены в виде прямоугольников. Строение каждого прямоугольника обозначено надписями. Указатели представлены стрелками, идущими от самого указателя к адресу, на который тот указывает. Для прохождения списка нужно последовать указателю головы — так мы найдем первую запись.
Далее необходимо следовать указателям, хранящимся в записях, и по ним переходить от элемента к элементу до достижения пустого (NIL) указателя.
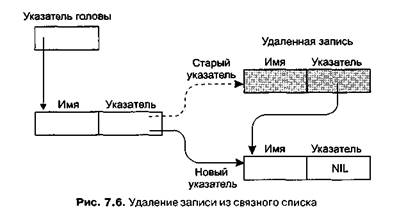
Теперь вернемся к вопросу удаления и добавления элементов в список. Нам нужно увидеть, как использование указателей устраняет необходимость перемещения имен, возникающую при хранении списка в одном связном блоке. Для начала заметим, что удалить имя можно, изменив один указатель. Это означает, что указатель, который ранее указывал на удаленное имя, изменяется и указывает теперь на имя, следующее за удаленным (рис. 7.6). И тогда при прохождении списка удаленное имя пропускается, поскольку не является более элементом цепочки.
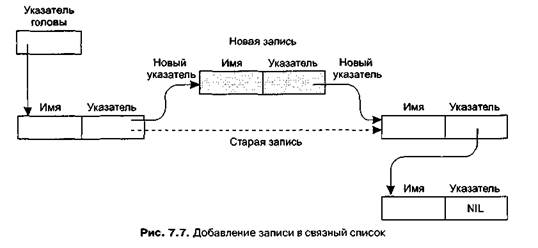
Добавление нового имени ненамного сложнее. Сначала находим неиспользуемый блок из девяти ячеек памяти, записываем новое имя в первые восемь ячеек, а в девятую записываем адрес имени, которое должно следовать в списке за новым. Затем изменяем указатель, связанный с именем, которое должно предшествовать новому имени в списке так, чтобы он указывал на этот новый блок (рис. 7.7). После этого новую запись можно будет найти на нужном месте при прохождении списка.