2015-10-22
2015-10-22 510
510Как и для других структур, которые мы уже изучали, полезно отделить технические детали реализации деревьев от прочих составляющих приложения. Поэтому программист обычно выделяет действия, которые будут производиться с деревом, и пишет для их выполнения процедуры, которые затем используются для доступа к дереву из других частей программы. Эти процедуры вместе с областью хранения составляют пакет, применяемый как абстрактный инструмент.
Чтобы продемонстрировать такой пакет, вернемся к вопросу хранения списка имен в алфавитном порядке. Мы предполагаем, что с этим списком можно выполнять следующие действия:
♦ искать, существует ли определенная запись;
♦ печатать список в алфавитном порядке;
♦ вставлять новую запись.
Наша цель — разработать систему хранения и набор процедур для выполнения этих операций.
Начнем с обсуждения вариантов процедур поиска в списке. Если список создан на основе модели связного списка, рассмотренной в разделе 7.3, поиск в нем придется осуществлять последовательно, а этот процесс, как мы узнали в главе 4, крайне неэффективен в длинных списках. Таким образом, надо найти способ реализации, позволяющий использовать алгоритм бинарного поиска (см. главу 4). Для применения этого алгоритма в системе хранения должен быть возможен поиск центральных записей в последовательно уменьшающихся блоках списка. Это несложно сделать в непрерывном списке, так как адрес центральной записи можно вычислить, так же как местоположение записей в массиве. Но при использовании непрерывных списков возникают проблемы с добавлением элементов, рассмотренные в разделе 7.3.
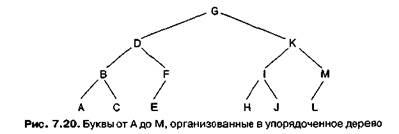
Эту проблему можно решить хранением списка в связном бинарном дереве вместо какой-либо традиционной системы хранения списков. Центральная запись списка становится корневым узлом, центральная запись первой половины списка — левым потомком корня, а центральная запись второй половины — правым потомком. Центральные записи оставшихся четвертей списка становятся потомками детей корня и т. д. Например, бинарное дерево на рис. 7.20 представляет список букв А, В, С, D, E, F, G, H, I, J, К, L и М. (Если часть списка состоит из четного количества записей, центральной мы будем считать запись с большим значением.)
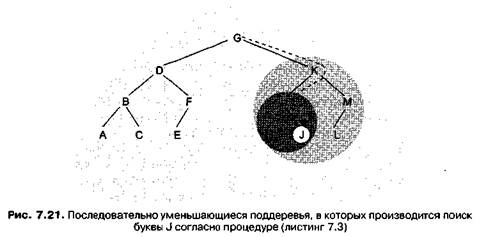
Для осуществления поиска в списке, хранящемся таким образом, мы сравниваем значение, которое требуется найти, со значением в корневом узле. Если они равны, поиск успешно завершен. Если они не равны, то, в зависимости от того, меньше или больше искомое значение корневого, мы переходим, соответственно, к левому или правому потомку — который становится корневым узлом поддерева, в котором будет продолжаться поиск. Процесс сравнения и перехода к потомку продолжается до тех пор, пока искомое значение не будет найдено (то есть поиск завершится успешно) или пока мы не достигнем пустого указателя, не найдя искомое значение (то есть поиск завершится неудачей).
Листинг 7.3 показывает, как может быть реализован такой процесс поиска в связном бинарном дереве. Обратите внимание, что приведенная процедура является усовершенствованием обсуждавшейся ранее процедуры (см. листинг 4.4) — исходного варианта реализации бинарного поиска. Различия между ними чисто внешние. В первой процедуре (смю листинг 4.4) поиск осуществлялся в последовательно уменьшающихся частях списка, а в последней (листинг 7.3) — в последовательно уменьшающихся поддеревьях (рис. 7.21).
Листинг 7.3. Бинарный поиск в списке, реализованном в виде связного бинарного дерева
procedure SearchCTree. TargetValue) if (корневой указатель дерева Tree = NIL) then (Объявление неудачного завершения поиска) else (Выполнение одного из блоков операций, приведенных ниже, в соответствии с подходящим
вариантом) case I: TargetValue = значение корневого узла
(Поиск завершен успешно) case 2: TargetValue < значения корневого узла
(Вызов процедуры Search для поиска TargetValue в поддереве, определенном указателем на левого потомок корня, и получения отчета о результатах поиска) case 3: TargetValue > значения корневого узла
(Вызов процедуры Search для поиска TargetValue в поддереве, определенном указателем на правого потомка корня, и получения отчета о результатах поиска)) end if
Поскольку естественное последовательное расположение элементов списка было изменено в целях упрощения поиска, вы можете подумать, что процесс печати списка в алфавитном порядке теперь усложнится. Выясняется, однако, что это предположение неверно. Для выполнения этой операции нам необходимо просто напечатать в алфавитном порядке левое поддерево, затем корневой узел, а после этого — правое поддерево (рис. 7.22). Мы знаем, что элементы в левом поддереве меньше элемента в корневом узле, а записи в правом поддереве, наоборот, больше. Так выглядит набросок процедуры печати:
if (дерево не пусто)
then (печать левого поддерева в алфавитном порядке:
печать корневого узла;
печать правого поддерева в алфавитном порядке)
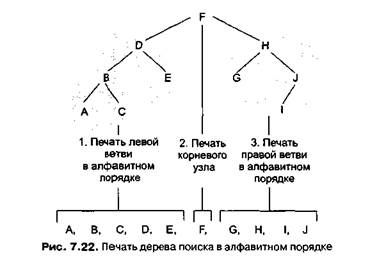
Вы можете возразить, что эта схема не приближает нас к разработке полной процедуры печати, так как включает задачи печати левого и правого поддеревьев в алфавитном порядке, в точности повторяющие нашу исходную задачу. Однако печать поддерева — это меньшая по размерам задача по сравнению с печатью целого дерева. Таким образом, в решение проблемы печати дерева входят решения меньших задач печати поддеревьев, что приводит к идее рекурсивного подхода.
Следуя этой идее, мы можем расширить наш набросок до полной процедуры печати дерева, написанной на псевдокоде (листинг 7.4). Мы назначили процедуре имя PrintTree и вызываем PrintTree для печати левого и правого поддеревьев. Обратите внимание, что условие завершения рекурсивного процесса (получение
пустого поддерева) будет гарантированно достигнуто, так как при каждом новом вызове процедура работает с поддеревом, меньшим по размеру, чем предыдущее.
Листинг 7.4. Процедура печати данных бинарного дерева
procedure PrintTree (Tree) if (дерево Tree не пусто) then
(Применение процедуры PrintTree к дереву на левом узле дерева Tree;
Печать корневого узла дерева Tree;
Применение процедуры PrintTree к дереву на правом узле дерева Tree)
Задача добавления новой записи в дерево также проще, чем может показаться на первый взгляд. Можно решить, что для получения необходимого для добавления определенных элементов пространства может потребоваться разрезать дерево, но в действительности любой добавляемый узел может быть присоединен к дереву как новый лист, независимо от его значения. Чтобы найти подходящее место для новой записи, мы следуем вниз по дереву по тому же пути, по которому шли бы для поиска этой записи. Так как такого значения в дереве нет, в конце концов, мы придем к пустому указателю. Это и будет подходящим местом для нового узла (рис. 7.23). Действительно, мы нашли место, к которому нас приведет поиск нового значения.
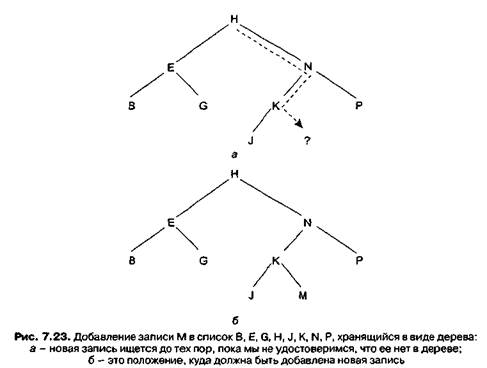
Процедуру, реализующую этот процесс в случае связного дерева, содержит листинг 7.5. Сначала в дереве проводится поиск вставляемого значения (оно называется NewValue), затем на место пустого указателя помещается указатель на
новый листовой узел, содержащий NewValue. Если же значение, которое мы хотим вставить в дерево, найдено при поиске, оно повторно не добавляется.
Листинг 7.5. Процедура для добавления новой записи в список, хранящийся в виде бинарного дерева
procedure Insertdree, NewValue)
if (Корневой указатель дерева Tree = NIL)
then (Корневой указатель переопределяется и указывает на новый лист,
содержащий NewValue)
else (Выполнение одного из блоков операций ниже в соответствии с подходящим вариантом) case I: NewValue - значение корневого указателя
(Ничего не делать) case 2: NewValue < значения корневого указателя
(if (указатель на левого потомка корневого узла = NIL)
then (Этот указатель переопределяется и указывает на новый лист, содержащий NewValue) else (Применение процедуры Insert для добавления NewValue в поддерево, определяемое
указателем на левого потомка) case 3: NewValue > значения корневого указателя
(if (указатель на правого потомка корневого узла = NIL)
then (Этот указатель переопределяется и указывает на новый лист, содержащий NewValue) else (Применение процедура Insert для добавления NewValue в поддерево,
определяемое указателем на правого потомка)) end if
Резюмируем, что программный пакет, состоящий из структуры связного дерева и процедур для поиска, печати и добавления записей, является полным и может использоваться как абстрактный инструмент нашим гипотетическим приложением.