 2015-10-22
2015-10-22 1119
1119Альтернативой измерению сложности в терминах времени является изменение пространственных требований — такое измерение известно под названием пространственной сложности (space complexity). Пространственная сложность задачи определяется количеством машинной памяти, необходимой для решения задачи. В этой главе мы узнали, что временная сложность сортировки списка из п записей равна О(л 1д п). Пространственная сложность той же задачи не превышает О(л + 1) = О(л). Действительно, для сортировки списка из п записей методом вставки необходимо пространство для хранения самого списка и еще одной временной записи. Таким образом, если нам потребуется сортировка все более длинных списков, мы увидим, что время, требуемое для выполнения каждой задачи, будет увеличиваться быстрее, чем расходуемое пространство. Это достаточно распространенный феномен. Так как использование пространства требует времени, пространственная сложность задачи никогда не будет увеличиваться быстрее, чем ее временная сложность.
Часто между временной и пространственной сложностью ищутся какие-либо компромиссы. В некоторых приложениях удобнее выполнять определенные вычисления заранее и хранить результаты в таблице, из которой при необходимости их легко восстановить. Такая техника табличного поиска сокращает время, необходимое конечной системе, за счет дополнительного пространства, которое занимает таблица. С другой стороны, сжатие данных зачастую применяется для сокращения требований к пространству, но при этом необходимо дополни-; тельное время для сжатия и восстановления данных.
Наши исследования процессов поиска и сортировки приводят к выводу, что задача поиска в списке длиной п (когда все, что мы знаем о списке — что он был предварительно упорядочен) принадлежит O(lg n), так как эту задачу может решить бинарный поиск. Кроме того, исследователи показали, что проблема поиска в действительности принадлежит 0(lg n), то есть бинарный поиск является оптимальным решением задачи. С другой стороны, мы знаем, что задача сортировки списка длиной п (когда мы ничего не знаем об исходном распределении значений в списке) принадлежит О(п2), потому что алгоритм сортировки вставкой может решить эту задачу. Однако, как показали исследования, задача сортировки принадлежит Q(n lg n), то есть алгоритм сортировки вставкой — это не оптимальное решение (в смысле временной сложности).
Примером лучшего решения является алгоритм сортировки слиянием. Он состоит в объединении небольших отсортированных частей списка для получения более крупных отсортированных фрагментов, которые объединяются в еще более длинные отсортированные отрезки списка. Каждый процесс слияния выполняется при помощи алгоритма слияния (листинг 8.1), который мы рассмотрели при обсуждении последовательных файлов. Для удобства мы еще раз расмот-рим его (листинг 11.3), в этот раз на примере слияния двух упорядоченных списков. Полный (рекурсивный) алгоритм сортировки слиянием представлен в виде процедуры MergeSort (листинг 11.4). Когда эта процедура получает список для сортировки, сначала она проверяет, содержится ли в списке более одной записи. Если нет, то задача процедуры выполнена. Если записей больше одной, процедура делит список на две части, которые отправляет для сортировки другим копиям процедуры MergeSort, а затем объединяет отсортированные части для получения конечного отсортированного варианта списка.
Листинг 11.3. Процедура MergeLists для объединения двух упорядоченных списков
procedure MergeLists (InputListA. InputListB, OutputList)
if (оба входных списка пусты) then (Остановиться, список OutputList пуст)
if (InputListA пуст)
then (Объявляем его пустым)
else (Объявляет его первую запись его текучей записью) if- (InputListB пуст)
then (Объявляем его пустым)
else (Объявляет его первую запись его текущей записью) while (ни один из входных списков не пуст) do
(Поместить "меньшую" текущую запись в OutputList;
if (эта текущая запись - последняя в соответствующем входном списке) then (Объявить этот входной список пустым) else (Объявить следующую запись этого входного списка текущей записью этого списка)
) Начиная с текущей записи непустого входного списка, скопировать оставшиеся записи
в OutputList.
Листинг 11.4. Алгоритм сортировки слиянием, реализованный в процедуре MergeSort
procedure MergeSort (List) if (В списке List более одной записи) then
(Применить процедуру MergeSort для сортировки первой половины списка List: Применить процедуру MergeSort для сортировки второй половины списка List:
Применить процедуру MergeLists для объединения первой и второй половины списка List
и получения отсортированной версии List)
Чтобы проанализировать сложность этого алгоритма, сначала найдем количество сравнений записей списка, необходимое для слияния списка длиной г со списком длиной s. Процесс слияния заключается в последовательном сравнении записей из одного списка с записями другого и помещении меньшего значения в выходной список. Таким образом, каждый раз, когда производится сравнение, количество оставшихся записей уменьшается на одну. Так как алгоритм начинает работать на г + s записей, мы делаем вывод, что процесс слияния двух списков потребует не более г + s сравнений.
Теперь рассмотрим алгоритм сортировки слиянием полностью. Он решает задачу сортировки списка длиной п так, что исходная задача сортировки разделяется на две меньших, когда сортируются списки длиной приблизительно "/2. Эти две задачи, в свою очередь, делятся еще раз, и мы получаем четыре задачи сортировки списков длиной приблизительно "Д. Этот процесс деления можно представить при помощи дерева на рис. 11.5, где каждый узел соответствует одной задаче в рекурсивном процессе, а ветви, исходящие из каждого узла, — это задачи меньшего размера, полученные из родительской задачи. Следовательно, мы можем найти общее количество сравнений, производимых в процессе сортировки, сложив количество сравнений, найденное в узлах дерева.
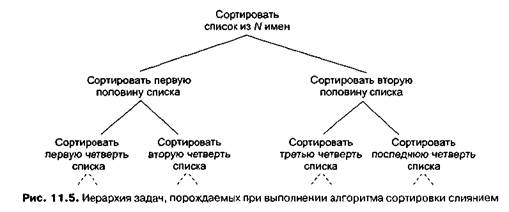
Сначала определим количество сравнений на каждом уровне дерева. Задача каждого узла на определенном уровне дерева — сортировать уникальный сегмент исходного списка. Это делается при помощи процесса слияния и, следовательно, требует сравнений не больше, чем есть записей в сегменте списка, что мы уже показали. Поэтому на каждом уровне дерева количество сравнений будет не больше общего количества записей в сегментах списка, а так как сегменты на данном уровне дерева являются непересекающимися частями исходного списка, конечное число сравнений будет не больше длины исходного списка. Следовательно, на каждом уровне дерева потребуется не более п сравнений. (Конечно, на нижнем уровне выполняется сортировка списков длиной 1 или менее, и сравнения не требуются вовсе.)
Теперь подсчитаем количество уровней в дереве. Для этого обратите внимание, что процесс деления задач на меньшие продолжается, пока не будут получены списки длиной менее двух. Поэтому количество уровней в дереве определяется количеством возможных операций деления на два, начиная со значения п до получения результатов, не превышающих единицу, то есть lg п. Точнее, в дереве может быть не более fig n\ уровней, требующих сравнений, где обозначение fig п\ — это округление lg п до ближайшего целого, большего lg п.
Наконец, общее количество сравнений, которые выполняет алгоритм сортировки слиянием при сортировке списка длиной п, получается умножением количества сравнений на каждом уровне на количество уровней, на которых требуются сравнения. Мы делаем вывод, что оно не превышает п Fig n\ Так как график функции пFig n\имеет ту же форму, что и график п lg n, то алгоритм сортировки слиянием принадлежит О(«lg n). Учитывая тот факт, что сложность задачи сортировки равна Q(n lg n), можно утверждать, что алгоритм сортировки слиянием является оптимальным решением задачи сортировки.








