 2018-01-08
2018-01-08 1725
1725
5.1.1. Основные идеи вычислительного метода динамического программирования. Некоторые задачи математического программирования обладают специфическими особенностями, которые позволяют свести их решение к рассмотрению некоторого множества более простых «подзадач». В результате вопрос о глобальной оптимизации некоторой функции сводится к поэтапной оптимизации некоторых промежуточных целевых функций. В динамическом программировании* рассматриваются методы, позволяющие путем поэтапной (многошаговой) оптимизации получить общий (результирующий) оптимум.
* Динамическое программирование как научное направление возникло и сформировалось в 1951-1953 гг. благодаря работам Р. Беллмана и его сотрудников.
Обычно методами динамического программирования оптимизируют работу некоторых управляемых систем, эффект которой оценивается аддитивной, или мультипликативной, целевой функцией. Аддитивной называется такая функция нескольких переменных f (х 1, x 2, ...,хn), значение которой вычисляется как сумма некоторых функций fj, зависящих только от одной переменной хj:
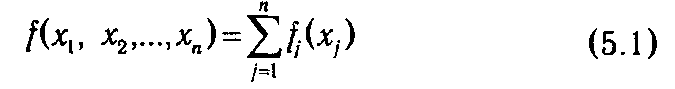
Слагаемые аддитивной целевой функции соответствуют эффекту решений, принимаемых на отдельных этапах управляемого процесса. По аналогии, мультипликативная функция распадается на произведение положительных функций различных переменных:
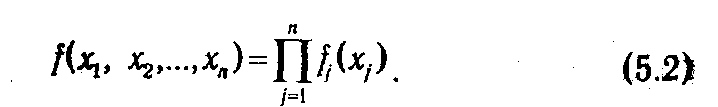
Поскольку логарифм функции типа (5.2) является аддитивной функцией, достаточно ограничиться рассмотрением функций вида (5.1).
Изложим сущность вычислительного метода динамического программирования на примере задачи оптимизации
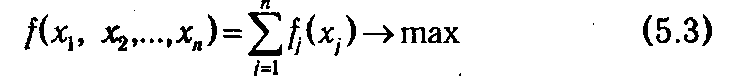
при ограниченияx
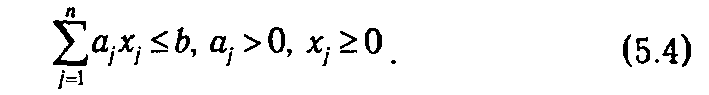
Отметим, что в отличие от задач, рассмотренных в предыдущих главах, о линейности и дифференцируемости функций fj (xj) не делается никаких предположений, поэтому применение классических методов оптимизации (например, метода Лагранжа) для решения задачи (5.3)-(5.4) либо проблематично, либо просто невозможно.
Содержательно задача (5.3)-(5.4) может быть интерпретирована как проблема оптимального вложения некоторых ресурсов j, приводимых к единой размерности (например, денег) с помощью коэффициентов aj, в различные активы (инвестиционные проекты, предприятия и т. п.), характеризующиеся функциями прибыли fj, т. е. такого распределения ограниченного объема ресурса (b), которое максимизирует суммарную прибыль. Представим ситуацию, когда она решается последовательно для каждого актива. Если на первом шаге принято решение о вложении в n -й актив xn единиц, то на остальных шагах мы сможем распределить b-anxn единиц ресурса. Абстрагируясь от соображений, на основе которых принималось решение на первом шаге (допустим, мы по каким-либо причинам не могли на него повлиять), будет вполне естественным поступить так, чтобы на оставшихся шагах распределение текущего объема ресурса произошло оптимально, что равнозначно решению задачи
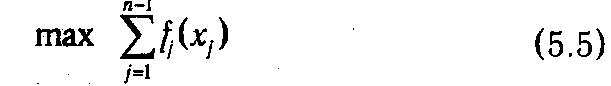
при ограничениях
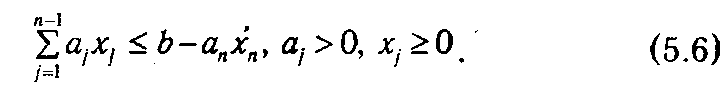
Очевидно, что максимальное значение (5.5) зависит от размера распределяемого остатка, и если оставшееся количество ресурса обозначить через ξ, то величину (5.5) можно выразить как функцию от ξ:
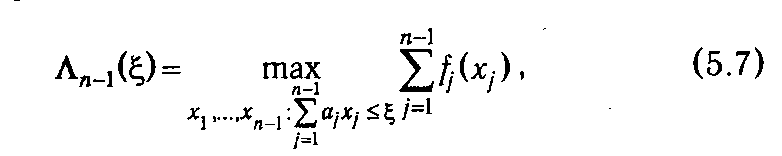
где индекс п -1 указывает на оставшееся количество шагов. Тогда суммарный доход, получаемый как следствие решения, принятого на первом шаге, и оптимальных решений, принятых на остальных шагах, будет
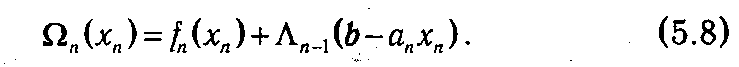
Если бы имелась возможность влиять на xn , то мы для получения максимальной прибыли должны были бы максимизировать Ω n по переменной xn, т. е. найти Λ n (b) и фактически решить задачу:
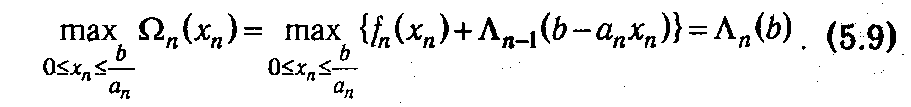
В результате мы получаем выражение для значения целевой функции задачи при оптимальном поэтапном процессе принятия решений о распределении ресурса. Оно в силу построения данного процесса равно глобальному оптимуму целевой функции
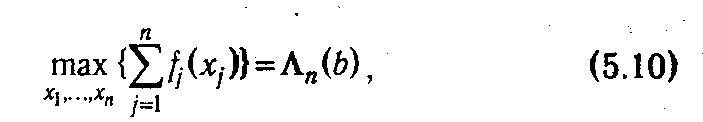
т. е. значению целевой функции при одномоментном распределении ресурса.
Если в выражении (5.9) заменить значения b на ξ, и п на k, то его можно рассматривать как рекуррентную формулу, позволяющую последовательно вычислять оптимальные значения целевой функции при распределении объема ресурса ξ за k шагов:
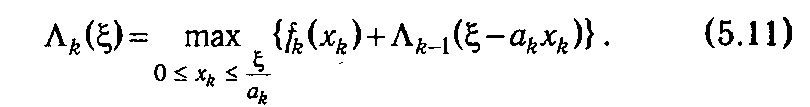
Значение переменной xk, при котором достигается рассматриваемый максимум, обозначим  k (ξ).
k (ξ).
При k = 1 формула (5.11) принимает вид
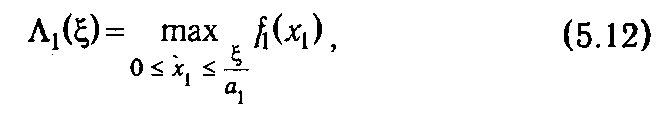
т. е. допускает непосредственное вычисление функций Λ1(ξ) и 1(ξ).
Воспользовавшись (5.12) как базой рекурсии, можно с помощью (5.11) последовательно вычислить Λ k (ξ) и k (ξ), k ∊2: n. Положив на последнем шаге ξ = b, в силу (5.9), найдем глобальный максимум функции (5.3), равный Λ n (b), и компоненту оптимального плана хn* = n (b). Полученная компонента позволяет вычислить нераспределенный остаток на следующем шаге при оптимальном планировании: ξ= b – аnх*n, и, в свою очередь, найти х*n- 1= n- 1(ξ n- 1). В результате подобных вычислений последовательно будут найдены все компоненты оптимального плана.
Таким образом, динамическое программирование представляет собой целенаправленный перебор вариантов, который приводит к нахождению глобального максимума. Уравнение (5.11), выражающее оптимальное решение на k -м шаге через решения, принятые на предыдущих шагах, называется основным рекуррентным соотношением динамического программирования. В то же время следует заметить, что описанная схема решения при столь общей постановке задачи имеет чисто теоретическое значение, так как замыкает вычислительный процесс на построение функций Λ k (ξ) (k ∊1: n), т. е. сводит исходную задачу (5.3)—(5.4) к другой весьма сложной проблеме. Однако при определенных условиях применение рекуррентных соотношений может оказаться весьма плодотворным. В первую очередь это относится к задачам, которые допускают табличное задание функций Λ k (ξ).
5.1.2. Задачи динамического программирования, допускающие табличное задание рекуррентных соотношений. Рассмотрим процесс решения модифицированного варианта задачи (5.3)-(5.4), в котором переменные хj и параметры aj, b могут принимать только целочисленные значения, а ограничение (5.4) имеет вид равенства. В рамках предложенной в п. 5.1.1 интерпретации о вложении средств в активы данные предпосылки вполне реалистичны и, более того, могут быть даже усилены требованием о кратности значений хj, например, 1000 единицам.
Чтобы не усложнять обозначения, условимся операции целочисленной арифметики записывать стандартным образом, полагая, что промежуточные результаты подвергаются правильному округлению. Так, например, будем считать, что 12/5=2.
В соответствии с общей схемой вычислительного алгоритма на первом шаге мы должны построить функцию
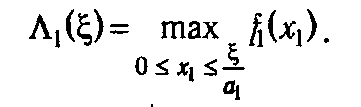
Поскольку ξ≤ b, x 1 принимает конечное число целых значений от 0 до b / a 1. Это позволяет, например, путем перебора значений f 1(x 1) найти функцию Λ1(ξ) и задать ее в форме таблицы следующей структуры (табл. 5.1).
Последняя колонка табл. 5.1 ( 1(ξ)) содержит значение x 1, на котором достигается оптимальное решение первого шага. Его необходимо запоминать для того, чтобы к последнему шагу иметь значения всех компонент оптимального плана.
На следующем (втором) шаге можно приступить к вычислению функции Λ2(ξ), значения которой для каждого отдельно взятого ξ∊ 0: b находятся как
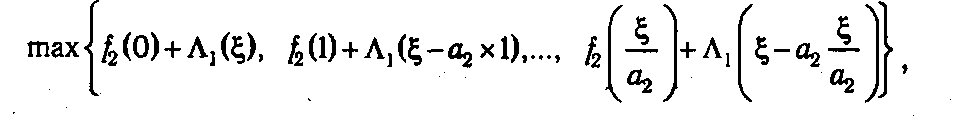
где значения
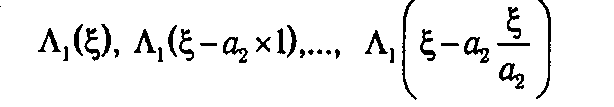
берутся из табл. 5.1. В результате вычислений формируется таблица значений Λ2(ξ), содержащая на одну колонку больше по сравнению с табл. 5.1, так как теперь необходимо запомнить оптимальные решения первого ( 1(ξ)) и второго шагов ( 2(ξ)).
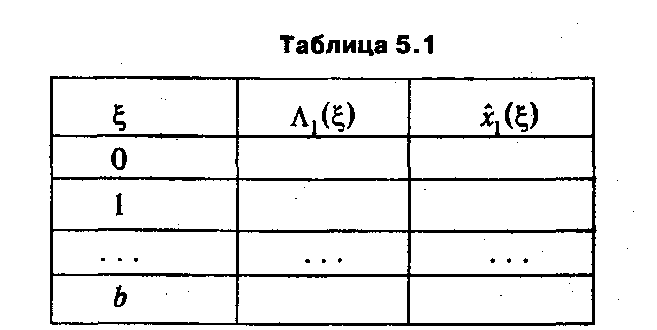
На последующих шагах с номером k (k ∊2:(n-l)) осуществляются аналогичные действия, результатом которых становятся таблицы значений Λ k (ξ), где ξ ∊{0, 1,..., b } (см. табл. 5.2).

На последнем n -ом шаге нет необходимости табулировать функцию Λ n (ξ), так как достаточно определить лишь Λ n (b) = f ( n (b)). Одновременно определяется и оптимальное значение n -й компоненты оптимального плана x*n = n (b). Далее, используя таблицу, сформированную на предыдущем шаге, определяем оптимальные значения остальных переменных:
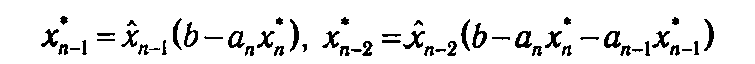
и т. д. или, в общем виде,
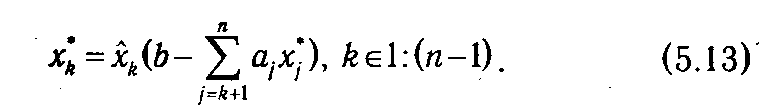
Подчеркнем одно из преимуществ описанного метода с точки зрения его практической реализации в рамках программного обеспечения для ЭВМ: на каждом шаге алгоритма непосредственно используется только таблица, полученная на предыдущем шаге, т. е. нет необходимости сохранять ранее полученные таблицы. Последнее позволяет существенно экономить ресурсы компьютера.
Выигрыш, который дает применение рассмотренного алгоритма, может также быть оценен с помощью следующего простого примера. Сравним приблизительно по числу операций (состоящих, в основном, из вычислений целевой функции) описанный метод с прямым перебором допустимых планов задачи (5.3)-(5.4) при а 1 = a 2 =... аn = 1.
Количество допустимых планов такой задачи совпадает с количеством целочисленных решений уравнения
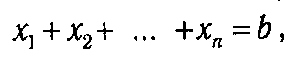
т. е. равно числу сочетаний с повторениями из n элементов по b. Следовательно, при простом переборе число возможных вариантов составит
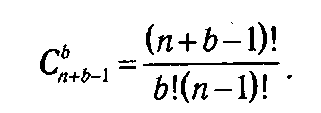
В случае применения метода динамического программирования для вычисления таблицы значений функции Λ k (ξ) при фиксированном ξ необходимо выполнить (ξ+1) операций. Поэтому для заполнения одной таблицы необходимо проделать
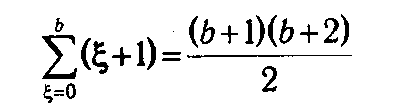
операций, из чего получаем, что для вычисления всех функции 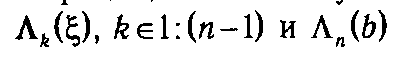 потребуется
потребуется
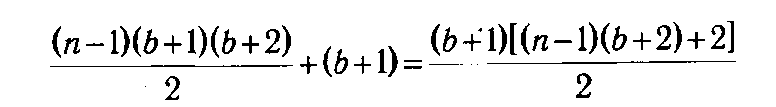
операций, что при больших n и b существенно меньше, чем в первом случае. Например, если п = 6 и b = 30, то непосредственный перебор потребует выполнения 324 632 операций, а метод динамического программирования — только 2511.
5.1.3. Принцип оптимальности Беллмана. Еще раз подчеркнем, что смысл подхода, реализуемого в динамическом программировании, заключен в замене решения исходной многомерной задачи последовательностью задач меньшей размерности.
Перечислим основные требования к задачам, выполнение которых позволяет применить данный подход:
Ø Ø объектом исследования должна служить управляемая система (объект) с заданными допустимыми состояниями и допустимыми управлениями;
Ø Ø задача должна позволять интерпретацию как многошаговый процесс, каждый шаг которого состоит из принятия решения о выборе одного из допустимых управлений, приводящих к изменению состояния системы;
Ø Ø задача не должна зависеть от количества шагов и быть определенной на каждом из них;
Ø Ø состояние системы на каждом шаге должно описываться одинаковым (по составу) набором параметров;
Ø Ø последующее состояние, в котором оказывается система после выбора решения на k -м. шаге, зависит только от данного решения и исходного состояния к началу k -го шага. Данное свойство является основным с точки зрения идеологии динамического программирования и называется отсутствием последействия.
Рассмотрим вопросы применения модели динамического программирования в обобщенном виде. Пусть стоит задача управления некоторым абстрактным объектом, который может пребывать в различных состояниях. Текущее состояние объекта отождествляется с некоторым набором параметров, обозначаемым в дальнейшем ξ и именуемый вектором состояния. Предполагается, что задано множество Ξ всех возможных состояний. Для объекта определено также множество допустимых управлений (управляющих воздействий) X, которое, не умаляя общности, можно считать числовым множеством. Управляющие воздействия могут осуществляться в дискретные моменты времени k (k ∊1: n), причем управленческое решение заключается в выборе одного из управлений xk ∊ Х. Планом задачи или стратегией управления называется вектор х = (х 1, х 2,.., xn -1), компонентами которого служат управления, выбранные на каждом шаге процесса. Ввиду предполагаемого отсутствия последействия между каждыми двумя последовательными состояниями объекта ξ k и ξ k +1 существует известная функциональная зависимость, включающая также выбранное управление: ξ k +1 = φ k (xk, ξ k), k ∊1: п -1. Тем самым задание начального состояния объекта ξ1∊Ξ и выбор плана х однозначно определяют траекторию поведения объекта, как это показано на рис. 5.1.
Эффективность управления на каждом шаге k зависит от текущего состояния ξ k , выбранного управления xk и количественно оценивается с помощью функций fk (хk, ξ k), являющихся слагаемыми аддитивной целевой функции, характеризующей общую эффективность управления объектом. (Отметим, что в определение функции fk (хk, ξ k) включается область допустимых значений хk, и эта область, как правило, зависит от текущего состояния ξ k .) Оптимальное управление, при заданном начальном состоянии ξ1, сводится к выбору такого оптимального плана х*, при котором достигается максимум суммы значений fk на соответствующей траектории.
Основной принцип динамического программирования заключается в том, что на каждом шаге следует стремиться не к изолированной оптимизации функции fk (хk, ξ k), а выбирать
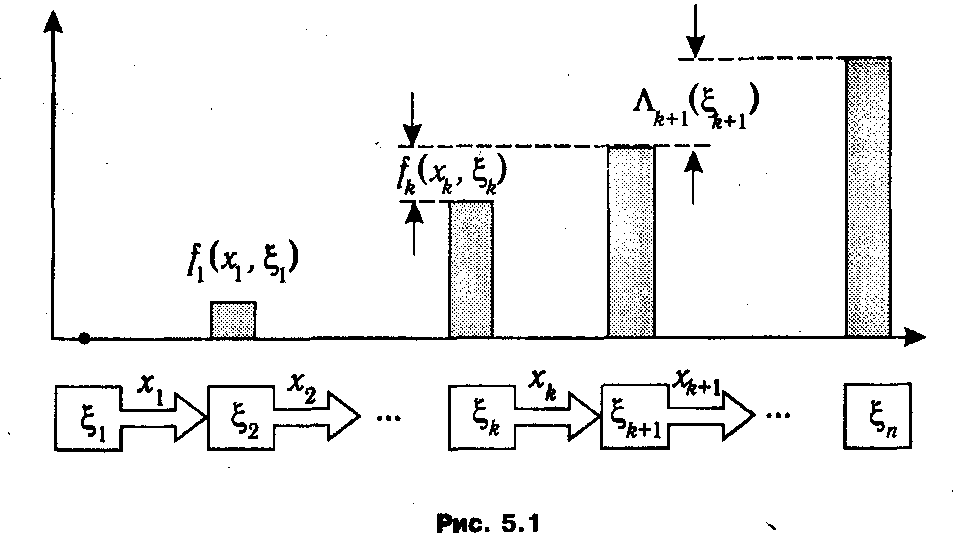
оптимальное управление хk* в предположении об оптимальности всех последующих шагов. Формально указанный принцип реализуется путем отыскания на каждом шаге k условных оптимальных управлений k (ξ), ξ∊Ξ, обеспечивающих наибольшую суммарную эффективность начиная с этого шага, в предположении, что текущим является состояние ξ.
Обозначим Λ k (ξ) максимальное значение суммы функций fk на протяжении шагов от k до п (получаемое при оптимальном управлении на данном отрезке процесса), при условии, что объект в начале шага k находится в состоянии ξ. Тогда функции Λ k (ξ) должны удовлетворять рекуррентному соотношению:
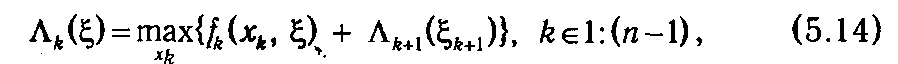
где ξ k +1 = φ k (xk, ξ)
Соотношение (5.14) называют основным рекуррентным соотношением динамического программирования. Оно реализует базовый принцип динамического программирования, известный также как принцип оптимальности Беллмана:
F Оптимальная стратегия управления должна удовлетворять следующему условию: каково бы ни было
начальное состояние ξ k на k-м шаге и выбранное на этом шаге управление хk,, последующие управления (управленческие решения) должны быть оптимальными по отношению к состоянию ξ k +1 = φ k (xk, ξ k), получающемуся в результате решения, принятого на шаге k.
Основное соотношение (5.14) позволяет найти функции Λ k (ξ) только в сочетании с начальным условием, каковым в нашем случае является равенство
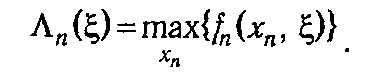
Сравнение рекуррентной формулы (5.14) с аналогичными соотношениями в рассмотренных выше примерах указывает на их внешнее различие. Это различие обусловлено тем, что в задаче распределения ресурсов фиксированным является конечное состояние управляемого процесса. Поэтому принцип Беллмана применяется не к последующим, а к начальным этапам управления, и начальное соотношение имеет вид
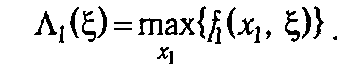
Важно еще раз подчеркнуть, что сформулированный выше принцип оптимальности применим только для управления объектами, у которых выбор оптимального управления не зависит от предыстории управляемого процесса, т. е. от того, каким путем система пришла в текущее состояние. Именно это обстоятельство позволяет осуществить декомпозицию задачи и сделать возможным ее практическое решение.
В то же время, говоря о динамическом программировании как о методе решения оптимизационных задач, необходимо отметить и его слабые стороны. Так, в предложенной схеме решения задачи (5.3)-(5.4) существенным образом используется тот факт, что система ограничений содержит только одно неравенство, и, как следствие, ее состояние задается одним числом — нераспределенным ресурсом ξ. При наличии нескольких ограничений состояние управляемого объекта на каждом шаге характеризуется уже набором параметров ξ1, ξ2,..., ξ m, и табулировать значения функций Λ k (ξ1, ξ2,..., ξ m) необходимо для многократно большего количества точек. Последнее обстоятельство делает применение метода динамического программирования явно нерациональным или даже просто невозможным. Данную проблему его основоположник Р. Беллман эффектно назвал «проклятием многомерности». В настоящее время разработаны определенные пути преодоления указанных трудностей. Подробную информацию о них можно найти в специальной литературе [4, 5].

