 2017-11-01
2017-11-01 9105
9105Компьютер может выполнять программу только в том случае, если содержащиеся в ней команды представлены в двоичном машинном коде, т.е. выражены на языке, алфавит которого состоит из логических единиц и нулей. Для первых компьютеров программы составлялись непосредственно в машинных кодах, что требовало высокой квалификации программистов и больших затрат труда, поэтому уже в 40-х годах началась разработка языков программирования, которые по своей лексике были бы максимально приближены к естественному языку человека. Такие языки программирования называются алгоритмическими.
Промежуточным шагом к разработке алгоритмических языков стал язык Ассемблер. В Ассемблере команды представляются не двоичными числами, а в виде сочетаний символов (мнемоническими кодами), по которым можно воспроизвести смысл команды, что значительно устраняет трудности и недостатки программирования на машинном языке. Однако Ассемблеру присущи и недостатки - это машинноориентированный язык, и для каждого компьютера создается свой язык Ассемблера. Программирование на Ассемблере требует от программиста хорошего знания архитектуры (устройства) компьютера и сопряжено со значительными трудозатратами, в то же время именно с помощью Ассемблера можно наилучшим образом использовать в программе ресурсы компьютера (память, быстродействие), поэтому Ассемблер по-прежнему широко распространен среди профессиональных программистов.
Первым алгоритмическим языком стал Fortran, созданный в 1957г. специалистами фирмы IBM под руководством Джона Бекуса. Сейчас существует большое множество алгоритмических языков: Pascal, C, Algol, PL1, Basic, Lisp, Prolog и многие другие.
Алгоритмические языки и ассемблеры относятся к языками символьного кодирования, т.е. к языкам, которые оперируют не машинными кодами, а условными символьными обозначениями, поэтому программы, составленные на этих языках, не могут быть непосредственно выполнены на компьютере. Чтобы такая программа заработала, ее текст нужно преобразовать в машинные коды. Для этого существуют специальные программы-переводчики (трансляторы). Различают 2 вида трансляторов- компилятор и интерпретатор. Компилятор транслирует программу сразу целиком, и лишь после этого возможно ее выполнение. Интерпретатор - это более простой транслятор, он последовательно транслирует операторы программы и так же по частям ее выполняет.
21) Структура программы на языке С/C++.
Программа на языке С++ состоит из функций, описаний и директив препроцессора. Одна из функций должна иметь имя main. Выполнение программы начинается с первого оператора этой функции. Простейшее определение функции имеет следующий формат:
| 1 2 3 | тип возвращаемого значения имя ([ параметры ]){ операторы, составляющие тело функции } |
Как правило, функция используется для вычисления какого-либо значения, поэтому перед именем функции указывается его тип. Ниже приведены самые необходимые сведения о функциях:
- если функция не должна возвращать значение, указывается тип void:
- тело функции является блоком и, следовательно, заключается в фигурные скобки;
- функции не могут быть вложенными;
- каждый оператор заканчивается точкой с запятой (кроме составного оператора).
Пример структуры программы, содержащей функции main, fl и f2:
| 1 2 3 4 5 6 7 8 9 10 11 | директивы препроцессора описания int main(){ операторы главной функции } int fl(){ операторы функции fl } int f2(){ операторы функции f2 } |
Программа может состоять из нескольких модулей (исходных файлов).
Несколько замечаний о вводе/выводе в C++
В языке С++ нет встроенных средств ввода/вывода — он осуществляется с помощью функций, типов и объектов, содержащихся в стандартных библиотеках. Используется два способа: функции, унаследованные из языка С, и объекты С++.
Основные функции ввода/вывода в стиле С:
int scanf (const char* format,...) // ввод
int printf(const char* format,...) // вывод
Они выполняют форматированный ввод и вывод произвольного количества величин в соответствии со строкой формата format. Строка формата содержит символы, которые при выводе копируются в поток (на экран) или запрашиваются из потока (с клавиатуры) при вводе, и спецификации преобразования, начинающиеся со знака %, которые при вводе и выводе заменяются конкретными величинами.
Пример программы, использующей функции ввода/вывода в стиле С:
#include
int main() {
int i;
printf("Введите целое число\п");
scanf("%d", &i);
printf("Вы ввели число %d, спасибо!", i);
return 0;
}
Первая строка этой программы — директива препроцессора, по которой в текст программы вставляется заголовочный файл, содержащий описание использованных в программе функций ввода/вывода (в данном случае угловые скобки являются элементом языка). Все директивы препроцессора начинаются со знака #.
Третья строка — описание переменной целого типа с именем i.
Функция printf в четвертой строке выводит приглашение «Введите целое число» и переходит на новую строку в соответствии с управляющей последовательностью \n. Функция scanf заносит введенное с клавиатуры целое число в переменную i (знак & означает операцию получения адреса), а следующий оператор выводит на экран указанную в нем строку, заменив спецификацию преобразова-
ния на значение этого числа.
А вот как выглядит та же программа с использованием библиотеки классов С++:
#include
int main() {
int i;
cout << "Введите целое число \n "; cin >> i;
cout << "Вы ввели число " << i << ", спасибо!";
return 0;
}
Заголовочный файлсодержит описание набора классов для управления вводом/выводом. В нем определены стандартные объекты-потоки cin для ввода с клавиатуры и cout для вывода на экран, а также операции помещения в поток < < и чтения из потока >>.
22) Алфавит и идентификаторы в языке С/C++.
АЛФАВИТ
• прописные и строчные латинские буквы и знак подчеркивания;
• арабские цифры от 0 до 9;
• пробельные символы: пробел, символы табуляции, символы перехода на но вую строку.
• специальные знаки:
Из символов алфавита формируются лексемы языка:
• идентификаторы;
• ключевые (зарезервированные) слова;
• знаки операций;
• константы;
• разделители (скобки, точка, запятая, пробельные символы).
ИДЕНТИФИКАТОРЫ
• В идентификаторе могут использоваться латинские буквы, цифры и знак подчеркивания;
• Прописные и строчные буквы различаются;
• Первым символом идентификатора может быть буква или знак подчеркивания, но не цифра;
• Пробелы внутри имен не допускаются;
• Длина идентификатора по стандарту не ограничена, но некоторые компиляторы и компоновщики налагают на нее ограничения;
• Идентификатор не должен совпадать с ключевыми словами;
• Не рекомендуется начинать идентификаторы с символа подчеркивания (могут совпасть с именами системных функций или переменных);
• На идентификаторы, используемые для определения внешних переменных;
• Есть ограничения компоновщика (использование различных компоновщиков или версий компоновщика накладывает разные требования на имена внешних переменных).

Ключевые слова С++
23) Целые типы данных в языке С/C++.
Целый тип данных предназначен для представления в памяти компьютера обычных целых чисел. Основным и наиболее употребительным целым типом является тип int. Гораздо реже используют его разновидности: short (короткое целое) и long (длинное целое). Также к целым типам относится тип char (символьный). Кроме того, при необходимости можно использовать и тип long long (длинное-предлинное!), который хотя и не определён стандартом, но поддерживается многими компиляторами C++. По-умолчанию все целые типы являются знаковыми, т.е. старший бит в таких числах определяет знак числа: 0 — число положительное, 1 — число отрицательное. Кроме знаковых чисел на C++ можно использовать беззнаковые. В этом случае все разряды участвуют в формировании целого числа. При описании беззнаковыхцелыхпеременных добавляется слово unsigned (без знака).
Сводная таблица знаковых целых типов данных:
| Тип данных | Размер, байт | Диапазон значений |
| char | -128... 127 | |
| short | -32768... 32767 | |
| int | -2147483648... 2147483647 | |
| long | -2147483648... 2147483647 | |
| long long | -9223372036854775808... 9223372036854775807 |
Сводная таблица беззнаковых целых типов данных:
| Тип данных | Размер, байт | Диапазон значений |
| unsigned char | 0... 255 | |
| unsigned short | 0... 65535 | |
| unsigned int (можно просто unsigned) | 0... 4294967295 | |
| unsigned long | 0... 4294967295 | |
| unsigned long long | 0... 18446744073709551615 |
Запоминать предельные значения, особенно для 4-х или 8-ми байтовых целых, вряд ли стоит, достаточно знать хотя бы какого порядка могут быть эти значения, например, тип int — приблизительно 2·109.
На практике рекомендуется везде использовать основной целый тип, т.е. int. Дело в том, что данные основного целого типа практически всегда обрабатываются быстрее, чем данные других целых типов. Короткие типы (char, short) подойдут для хранения больших массивов чисел с целью экономии памяти при условии, что значения элементов не выходят за предельные для этих типов. Длинные типы необходимы в ситуации, когда не достаточно типа int.
24) Вещественные типы данных в языке С/C++.
Особенностью вещественных (действительных) чисел является то, что в памяти компьютера они практически всегда хранятся приближенно, а при выполнении арифметических операций над такими данными накапливается вычислительная погрешность.
Имеется три вещественных типа данных: float, double и long double. Основным считается тип double. Так, все математические функции по-умолчанию работают именно с типом double. В таблице ниже приведены основные характеристики вещественных типов:
| Тип данных | Размер, байт | Диапазон абсолютных величин | Точность, количество десятичных цифр |
| float | от 3.4Е—38 до 3.4Е+38 | ||
| double | от 1.7Е—308 до 1.7Е+308 |
Тип long double в настоящее время, как правило, совпадает с типом double и на практике обычно не применяется. При использовании старых 16-ти разрядных компиляторов данные типа long double имеют размер 10 байт и обеспечивают точность до 19 десятичных цифр.
Рекомендуется везде использовать только тип double. Работа с ним всегда ведётся быстрее, меньше вероятность заметной потери точности при большом количестве вычислений. Тип float может пригодиться только для хранения больших массивов при условии, что для решения поставленной задачи будет достаточно этого типа.
25) Символьный тип данных в языке С/C++.
В стандарте C++ нет типа данных, который можно было бы считать действительно символьным. Для представления символьной информации есть два типа данных, пригодных для этой цели, — это типы char и wchar_t, хотя оба эти типа по сути своей вообще-то являются целыми типами. Например, можно взять символ 'A' и поделить его на число 2. Кстати, а что получится? Подсказка: символ пробела. Для «нормальных» символьных типов, например, в Паскале или C#, арифметические операции для символов запрещены.
Тип char используется для представления символов в соответствии с системой кодировки ASCII (American Standard Code for Information Interchange — Американский стандартный код обмена информации). Это семибитный код, его достаточно для кодировки 128 различных символов с кодами от 0 до 127. Символы с кодами от 128 до 255 используются для кодирования национальных шрифтов, символов псевдографики и др.
Тип wchar_t предназначен для работы с набором символов, для кодировки которых недостаточно 1 байта, например, Unicode. Размер типа wchar_t обычно равен 2 байтам. Если в программе необходимо использовать строковые константы типа wchar_t, то их записывают с префиксом L, например, L"Слово".
26) Оператор присваивания и пустой оператор в языке С/C++
Оператор присваивания — это самый употребительный оператор. Его назначение — присвоить новое значение какой-либо переменной. В C++ имеется три формы этого оператора.
1) Простой оператор присваивания записывается так:
переменная = выражение;
Данный оператор работает следующим образом: вначале вычисляется выражение, записанное справа от символа операции = (равно), затем полученный результат присваивается переменной, стоящей слева от знака =. Тип результата должен совпадать с типом переменной, записанной слева, или быть к нему приводимым.
Слева от знака = может быть только переменная, справа же можно записать и константу, и переменную и вообще выражение любой сложности.
Пример операторов
x=3;
r=x;
y=x+3*r;
s=sin(x);
2) Множественное присваивание — в таком операторе последовательно справа налево нескольким переменным присваивается одно и то же значение, например:
a=b=c=1;
Так можно сразу определить, к примеру, что в равностороннем треугольнике все стороны равны одному и тому же числу 1. Приведенный выше оператор эквивалентен последовательному выполнению трёх операторов:
a=1;
b=a;
c=b;
Естественно, нам проще записать один оператор, а не три. Программа получается короче, более естественно смотрится текст, и работает такая конструкция немного быстрее.
3) Присваивание с одновременным выполнением какой-либо операции в общем виде записывается так:
переменная знак_операции = выражение;
и равносильно записи
переменная = переменная знак_операции выражение;
Например, оператор:
s += 5; // 1-й вариант
делает то же самое, что и оператор
s = s + 5; // 2-й вариант
а именно: взять старое значение из переменной s, прибавить к нему число 5 и полученное значение снова записать в переменную s.
Как видим, запись 1-го варианта короче записи 2-го варианта, да и выполняется быстрее, так как в 1-м варианте адрес переменной s вычисляется 1 раз, а во 2-м варианте — дважды.
Пустой оператор
Пустой оператор — это оператор, который ничего не выполняет. Зачем нужен «бесполезный» оператор?
Пустой оператор используется в тех случаях, когда по синтаксису языка требуется записать какой-либо оператор, а по логике программы мы не собираемся что-либо делать. Так, пустой оператор может потребоваться в операторе ветвления, когда по какой-либо ветви ничего не требуется выполнять, так же для того, чтобы определить метку для перехода в тексте программы, а иногда — для пустого тела цикла.
Пустой оператор — это одиночный символ; (точка с запятой), например:
c=a+b;;
Здесь первый символ; (точка с запятой) завершает оператор присваивания, а второй символ как раз и даёт нам пустой оператор. В данной ситуации пустой оператор совсем не нужен (но и не является синтаксической ошибкой!), приведен только для пояснения. Более «разумные» примеры использования пустого оператора будут приведены позже в соответствующих темах.
27) Арифметические операции в языке С/C++.
Это наиболее часто используемые операции. Их смысл близок к тому, каким он известен из курса математики. Итак, перечислим их:
| Знак операции | Назначение | Пример использования | Результат |
| + | сложение | 2+5 | |
| - | вычитание | 4-1 | |
| * | умножение | 3*5 | |
| / | деление (обычное) | 2.4/2 | 1.2 |
| / | целочисленное деление | 5/2 | |
| % | вычисление остатка при целочисленном делении | 5%2 |
Приоритет операций сложения и вычитания ниже, чем умножения, деления и вычисления остатка. Для изменения порядка вычисления используют круглые скобки, например для умножения на 2 суммы двух чисел A и B можно написать:
2*(A+B)
Далее. Как видно из полученных результатов, в C++ один знак / означает две разные операции. Если один или оба операнда — вещественные, то выполняется обычное деление, если оба операнда — целые, то выполняется деление нацело и результат будет целого типа. Использование этой операции требует повышенной внимательности, например, если запрограммировать вычисление математического выражения
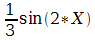
буквально, т.е. так:
1/3*sin(2*X)
то результат вне зависимости от значения X всегда будет равен нулю, так как выражение 1/3 означает деление нацело. Для решения проблемы достаточно один из операндов сделать вещественным
1.0/3*sin(2*X)
Операция вычисления остатка (%) применима только для целочисленных операндов.
Смена знака. Унарная операция «-» означает смену знака. Как видно из общей таблицы всех операций, она имеет очень высокий приоритет — выше, чем, к примеру, у операции умножение. Поэтому в выражении
-A*B
вначале выполняется смена знака для A, а затем умножение -A на B.
Для парности имеется и операция унарный плюс, т.е. можно написать
+A
Для каких целей это использовать? Сложно сказать. Но такая возможность есть.
Более интересны, и главное, очень употребительны операции автоувеличения и автоуменьшения.








