2018-02-14
2018-02-14 1592
1592Рассматривая статистическую задачу оптимизации, мы считали входной сигнал случайным процессом и минимизировали средний квадрат ошибки воспроизведения образцового сигнала. Однако возможен и иной подход, не использующий статистические методы.
Пусть, как и раньше, обработке подвергается последовательность, состоящая из К отсчетов x(k), коэффициенты нерекурсивного фильтра образуют вектор-столбец w, a отсчеты образцового сигнала равны d(k). Выходной сигнал фильтра определяется формулой (5.1), а ошибка воспроизведения образцового сигнала – формулой (5.2).
Теперь оптимизационная задача формулируется так: необходимо найти такие коэффициенты фильтра w, чтобы норма ошибки воспроизведения образцового сигнала была минимальной:
 . (5.10)
. (5.10)
Для решения задачи в выражениях (5.1) и (5.2) перейдем к матричной записи, получая формулы для векторов-столбцов выходного сигнала у и для ошибки воспроизведения входного сигнала е:
y = UTw, e=d - UTw. (5.11)
Здесь d – вектор-столбец отсчетов образцового сигнала, a U – матрица, столбцы которой представляют собой содержимое линии задержки фильтра на разных тактах
U=[u(0), u(1),…, u(K-1)].
Выражение (5.10) для нормы ошибки можно переписать в матричном виде следующим образом:
J(w)=e  . (5.12)
. (5.12)
Подставляя (5.11) в (5.12), получаем
J(w) = (d - UTw)T (d - UT w) = dTd - wTUd - 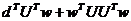 .
.
Для нахождения минимума необходимо вычислить градиент данного функционала и приравнять его нулю:
grad J(w) = -2Ud + 2UUT w = 0.
Отсюда легко получается искомое оптимальное решение:
w = (UU 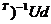 . (5.13)
. (5.13)
В формуле (5.13) прослеживается близкое родство с формулой (5.5), описывающей оптимальный в статистическом смысле фильтр Винера. Действительно, если учесть, что (UU  дает оценку корреляционной матрицы сигнала, полученную по одной реализации сигнала путем временного усреднения, a Ud / К является аналогичной оценкой взаимных корреляций между образцовым сигналом и содержимым линии задержки фильтра, то формулы (5.5) и (5.13) совпадут.
дает оценку корреляционной матрицы сигнала, полученную по одной реализации сигнала путем временного усреднения, a Ud / К является аналогичной оценкой взаимных корреляций между образцовым сигналом и содержимым линии задержки фильтра, то формулы (5.5) и (5.13) совпадут.
Алгоритм RLS
В принципе, в процессе приема сигнала можно на каждом очередном шаге пересчитывать коэффициенты фильтра непосредственно по формуле (5.13), однако это связано с неоправданно большими вычислительными затратами. Действительно, размер матрицы U постоянно увеличивается и, кроме того, необходимо каждый раз заново вычислять обратную матрицу (UUT)  . Сократить вычислительные затраты можно, если заметить, что на каждом шаге к матрице U добавляется лишь один новый столбец, а к вектору d – один новый элемент. Это дает возможность организовать вычисления рекурсивно. Соответствующий алгоритм называется рекурсивным методом наименьших квадратов (Recursive Least Square, RLS).
. Сократить вычислительные затраты можно, если заметить, что на каждом шаге к матрице U добавляется лишь один новый столбец, а к вектору d – один новый элемент. Это дает возможность организовать вычисления рекурсивно. Соответствующий алгоритм называется рекурсивным методом наименьших квадратов (Recursive Least Square, RLS).
Подробный вывод формул, описывающих алгоритм RLS, можно найти, например, в [2, 3], здесь, cледуя [4], приведем лишь основные идеи. При использовании алгоритма RLS производится рекурсивное обновление оценки обратной корреляционной матрицы P= (UUT) , а вывод формул основывается на следующем матричном тождестве:
(A + BCD) = 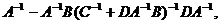
где А и С – квадратные невырожденные матрицы (необязательно одинаковых размеров), а В и D – матрицы совместимых размеров. Применение этой формулы для рекурсивного обновления обратной корреляционной матрицы Р в сочетании с исходной формулой (5.13) для коэффициентов оптимального фильтра дает следующую последовательность шагов адаптивного алгоритма RLS.
1. При поступлении новых входных данных u(k) производится фильтрация сигнала с использованием текущих коэффициентов фильтра w(k-1) и вычисление величины ошибки воспроизведения образцового сигнала:
y(k)=u  (k)w(k-1); (5.14)
(k)w(k-1); (5.14)
e(k) = d(k)-y(k).
2. Рассчитывается вектор-столбец коэффициентов усиления (следует отметить, что знаменатель дроби в следующих двух формулах является скаляром, а не матрицей):
K(k) = 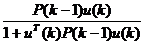 . (5.15)
. (5.15)
3. Производится обновление оценки обратной корреляционной матрицы сигнала:
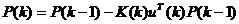 . (5.16)
. (5.16)
4. Наконец, производится обновление коэффициентов фильтра
 . (5.17)
. (5.17)
Начальное значение вектора w обычно принимается нулевым, а в качестве исходной оценки матрицы Р используется диагональная матрица вида CE  , где скаляр С >>1 (в [2] рекомендуется С >=100).
, где скаляр С >>1 (в [2] рекомендуется С >=100).
В критериях ошибок (5.10) и (5.12) значениям ошибки на всех временных тактах придается одинаковый вес. В результате, если статистические свойства входного сигнала со временем изменяются, это приводит к ухудшению качества фильтрации. Чтобы дать фильтру возможность отслеживать нестационарный входной сигнал, можно применить в (5.10) экспоненциальное забывание, при котором вес прошлых значений сигнала ошибки экспоненциально уменьшается
 .
.
В этом случае формулы (15), (16) принимают следующий вид
 ;
;

 .
.
Главным достоинством алгоритма RLS является быстрая сходимость. Однако достигается это за счет значительно более высокой (по сравнению с алгоритмом LMS) вычислительной сложности. Согласно [2] при оптимальной организации вычислений для обновления коэффициентов фильтра на каждом такте требуется (2.5N2+4N) пар операций «умножение–сложение».
Алгоритм Кальмана
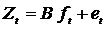 (3.1)
(3.1)
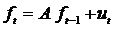
Прежде чем рассматривать применение алгоритма Кальмана для решения задачи адаптивной фильтрации, напомним формулировку задачи фильтрации случайного процесса с известными динамическими свойствами, для решения которой фильтр Кальмана изначально предназначен. Цель фильтра Кальмана – минимизировать дисперсию оценки векторного дискретного случайного процесса х(k), изменяющегося во времени следующим образом:
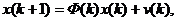
где Ф(k) – матрица перехода, v(k) –случайный вектор (шум процесса), имеющий нормальное распределение с корреляционной матрицей 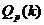 .
.
Для наблюдения доступен линейно преобразованный процесс у(k), к которому добавляется шум наблюдения
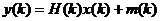 ,
,
где Н(k) – матрица наблюдения, m(k) – шум наблюдения, представляющий собой случайный вектор, имеющий нормальное распределение с корреляционной матрицей Qm(k).
Поиск алгоритма для рекурсивного обновления оценки процесса 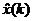 дает следующую последовательность формул:
дает следующую последовательность формул:
 – прогнозируемое значение наблюдаемого сигнала;
– прогнозируемое значение наблюдаемого сигнала;
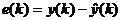 – невязка между прогнозируемым и реально наблюдаемым значениями;
– невязка между прогнозируемым и реально наблюдаемым значениями;
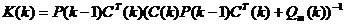 – кальмановский коэффициент усиления;
– кальмановский коэффициент усиления;
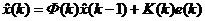 – обновление оценки процесса
– обновление оценки процесса  ;
;
 – обновление оценки корреляционной матрицы ошибок фильтрации.
– обновление оценки корреляционной матрицы ошибок фильтрации.
При использовании фильтра Кальмана для решения задачи адаптивной фильтрации отслеживаемым процессом является вектор коэффициентов оптимального фильтра w.
Предположим, что детерминированных изменений коэффициентов не происходит, поэтому матрица перехода Ф является единичной: Ф(k) = E. В качестве матрицы наблюдения выступает вектор содержимого линии задержки фильтра u(k). Таким образом, выходной сигнал фильтра представляет собой прогнозируемое значение наблюдаемого сигнала, а в качестве самого наблюдаемого сигнала выступает образцовый сигнал адаптивного фильтра d(k). Шум наблюдения в данном случае является ошибкой воспроизведения образцового сигнала, а матрица Q 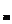 превращается в скалярный параметр – средний квадрат сигнала ошибки. Как отмечается в [3], величина этого параметра слабо влияет на поведение алгоритма. Рекомендуемые значения – (0.001...0.01)
превращается в скалярный параметр – средний квадрат сигнала ошибки. Как отмечается в [3], величина этого параметра слабо влияет на поведение алгоритма. Рекомендуемые значения – (0.001...0.01)  .
.
Если фильтруется стационарный случайный процесс, коэффициенты оптимального фильтра являются постоянными и можно принять Q = 0. Чтобы дать фильтру возможность отслеживать медленные изменения статистики входного сигнала, в качестве Q может использоваться диагональная матрица.
В результате приведенные выше формулы принимают следующий вид
y(k)=u (k) 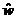 (k - 1) – выходной сигнал фильтра (прогнозируемое значение образцового сигнала);
(k - 1) – выходной сигнал фильтра (прогнозируемое значение образцового сигнала);
e(k) = d(k)-y(k) – ошибка фильтрации;
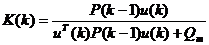 – кальмановский коэффициент усиления;
– кальмановский коэффициент усиления;
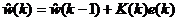 – обновление оценки коэффициентов фильтра w(k);
– обновление оценки коэффициентов фильтра w(k);
 – обновление оценки корреляционной матрицы ошибок оценивания.
– обновление оценки корреляционной матрицы ошибок оценивания.
Начальное значение вектора w обычно принимается нулевым, а в качестве исходной оценки матрицы Р используется диагональная матрица вида CЕ, где Е – единичная матрица.
Сравнивая формулы, описывающие алгоритмы RLS и Кальмана, легко заметить их сходство [7]. Вычислительная сложность и качественные параметры двух алгоритмов также оказываются весьма близкими. Разница заключается лишь в исходных посылках, использовавшихся при выводе формул, и в трактовке параметров алгоритмов. В некоторых источниках алгоритмы RLS и Кальмана применительно к адаптивной фильтрации отождествляются.