2018-02-14
2018-02-14 625
625В исследовательской и практической работе приходится сталкиваться с ситуацией, когда общее число признаков х1, х2, х3 … хр регистрируемых на каждом из множестве объектов (стран, регионов, семей) очень велико.
Тем не менее имеющиеся многомерные наблюдения следует подвергать статистической выборке (осмыслить, ввести в БВ, для того, чтобы иметь возможность использовать их в нужный момент).
Желание статистика представить любое из наблюдений хi в виде вектора z вспомогательных показателей.
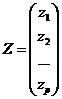 с существенно меньшим, чем число р компонент р` бывает обусловлен следующим причинам:
с существенно меньшим, чем число р компонент р` бывает обусловлен следующим причинам:
необходимостью наглядного представления исходных данных, что достигается их проецированием на специально подобранное трехмерное пространство (p`=3) или двухмерное (р`=2) или одномерное (р`=1);
стремлением к локализму исследуемых моделей для упрощения счета и интерпретации полученных выводов;
Ограниченными возможностями человека в одновременном охвате большого числа частных критериев;
Например: в анализе ряда разноспекторных характеристик качества жизни человека. А отсюда, стремление к сверстке информации и этих частных критериев и переходу к интегральному индикатору.
Необходимостью сжатия объемов хранимой информации (стат) в специальной БД. При этом вспомогательные признаки z1 z2 …zр могут вбираться из числа иходных признаков, либо явл их линейными комбинациями.
При формировании новой системы признаков k последним предъявляются разного рода требования, такие как: Наибольшая информативность (в определенном смысле) взаимная некоррелированность
Наименьшее искажение структуры их данных; В зависимости от варианта формальной конкретизации этих требований приходим к тому или иному алгоритму снижения размерности.
Имеется по крайней мер 3 основных тип принципиальных предпосылок, обуславливающих возможность перехода от большего числа р- исходных показателей, состояний исследуемой системы k существенно меньшему р` наиболее информативных переменных: дублирование информации (наличие взаимосвязанных признаков); не информативность (малая вариательность признака при переходе от одного объекта к др); возможность агригорования (т.е. простого суммирования или взаимного по некоторым группам).
Формально задача перехода с наименьшими потерями от р признаков к новому набору р` м.б. описана следующим образом: Пусть Z=Z(x)=Z(Z1 Z2 … Zp`) Некоторая р` -мерная функция от исходных переменных.
И пусть Ур(Z(x)) – определенным образом заданная мера информативности р`-мерной системы признаков: Z= Z(Z1(х) Z2(х) … Zp(х))Т
Конкретный выбор функционально зависит от специфики реально решаемых задач и оперяется на один из возможных критериев.
Критерия автноинформативности нацеленных на мах-ие сохранение информации, содержащейся в исходном массиве xi, относительно самих исходных признаков.
Критерий внешней информативности, нацеленной на мах-ию «выжимания» из хi информации относительно некоторых внешних показателей.
Тот или иной вариант конкретизации этой постановке приводит к конкретному методу снижения размерности, а именно: -методу гл. компонентов; -методу факторного анализа; -метод экстремальной группировке параметров.
Метод гл. компонент.
Во многих задачах обработки многомерных наблюдений и в частности в задачах классификации исследователя интересуют лишь те признаки, γ обнаруживают наибольшую изменчивость при переходе от одного объекта к др. С др стороны не обязательно для описания состояния объекта использовать какие-то из исходных замеренных на нем признаки (например, портной делает М изделий но для покупки достаточно 2 значения: рост и объем груди). Следуя общей оптимальности постановок задачи снижения размерности выражения:
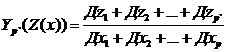 ,
,
можно принять в качестве меры информативности p`-мерной системы показателей. Тогда при любом фиксированном р` вектор Z искомых показателей вспомогательных переменных (новых) определяется как линейная комбинация Z= 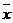 исходных данных, где - вектор центрированных исходных данных.
исходных данных, где - вектор центрированных исходных данных.
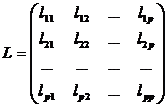 - принцип строки, γ удовлетворяет условию ортагональностьи.
- принцип строки, γ удовлетворяет условию ортагональностьи.
Полученных т.о. переменные и называют гл. компонентами.
1-ой гл. компонентой явл та, γ обладает наибольшей дисперсией. Далее компоненты располагаются по мере убывания дисперсей. Вычисление гл. компонент. По исходным статистическим данным получить вектор ср. значений и квалификационную матрицу ∙Σ.
Для определения коэффициентов линейного преобразования, с помощью γ осуществляется переход к главным компонентам необходимо решить харак-ческое уравнение.
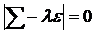
где ε – единичная матрица соответствующего порядка, λ=(λ1, λ2, … λр) – собств-ые значения (числа), Σ- сигма.
найти относительные доли суммарной дисперсии, обусловленные этим компонентом
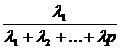 ;
; 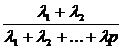 ; …
; …
К сожалению гл. компонента бывает сложно интерпретировать.
Х1- носит самую большую нагрузку.
Располагая исходными данными и используя уравнение для z1 (меняя значения х) можно посчитать значения 1-ой гл. компоненты для люб измеряемых пр-ий.
Интерпретируем z1 как объясняющую переменную и записываем уравнения хi=f(z1) (уравнение парной регрессии) для люб исходного показателя.