2018-02-14
2018-02-14 6294
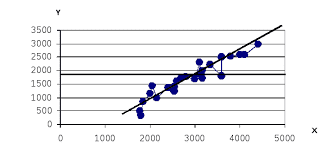
6294По 20 предприятиям региона изучается зависимость выработки продукции на одного работника y (тыс. руб.) от ввода в действие новых основных фондов x1 (% от стоимости фондов на конец года) и от удельного веса рабочих высокой квалификации в общей численности рабочих x2 (%).
| Номер предприятия | y | x1 | x2 | Номер предприятия | у | х1 | х2 |
| 1 | 7,0 | 3,9 | 10,0 | 11 | 9,0 | 6,0 | 21,0 |
| 2 | 7,0 | 3,9 | 14,0 | 12 | 11,0 | 6,4 | 22,0 |
| 3 | 7,0 | 3,7 | 15,0 | 13 | 9,0 | 6,8 | 22,0 |
| 4 | 7,0 | 4,0 | 16,0 | 14 | 11,0 | 7,2 | 25,0 |
| 5 | 7,0 | 3,8 | 17,0 | 15 | 12,0 | 8,0 | 28,0 |
| 6 | 7,0 | 4,8 | 19,0 | 16 | 12,0 | 8,2 | 29,0 |
| 7 | 8,0 | 5,4 | 19,0 | 17 | 12,0 | 8,1 | 30,0 |
| 8 | 8,0 | 4,4 | 20,0 | 18 | 12,0 | 8,5 | 31,0 |
| 9 | 8,0 | 5,3 | 20,0 | 19 | 14,0 | 9,6 | 32,0 |
| 10 | 10,0 | 6,8 | 20,0 | 20 | 14,0 | 9,0 | 36,0 |
Требуется:
1. Построить линейную модель множественной регрессии. Записать стандартизованное уравнение множественной регрессии. На основе стандартизованных коэффициентов регрессии и средних коэффициентов эластичности ранжировать факторы по степени их влияния на результат.
2. Найти коэффициенты парной, частной и множественной корреляции. Проанализировать их.
3. Найти скорректированный коэффициент множественной детерминации. Сравнить его с нескорректированным (общим) коэффициентом детерминации.
4. С помощью F -критерия Фишера оценить статистическую надежность уравнения регрессии и коэффициента детерминации 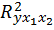
5. С помощью t -критерия оценить статистическую значимость коэффициентов чистой регрессии.
6. С помощью частных F -критериев Фишера оценить целесообразность включения в уравнение множественной регрессии фактора x1 после x2 и фактора x2 после x1.
7. Составить уравнение линейной парной регрессии, оставив лишь один значащий фактор.
Решение
Для удобства проведения расчетов поместим результаты промежуточных расчетов в таблицу:
| Номер предприятия | y | x1 | x2 | ух1 | ух2 |
|
|
| ||
| 1 | 7,0 | 3,9 | 10,0 | 27,3 | 70 | 39 | 15,21 | 100,0 | 49,0 | |
| 2 | 7,0 | 3,9 | 14,0 | 27,3 | 98 | 54,6 | 15,21 | 196 | 49 | |
| 3 | 7,0 | 3,7 | 15,0 | 25,9 | 105 | 55,5 | 13,69 | 225 | 49 | |
| 4 | 7,0 | 4,0 | 16,0 | 28 | 112 | 64 | 16,00 | 256 | 49 | |
| 5 | 7,0 | 3,8 | 17,0 | 26,6 | 119 | 64,6 | 14,44 | 289 | 49 | |
| 6 | 7,0 | 4,8 | 19,0 | 33,6 | 133 | 91,2 | 23,04 | 361 | 49 | |
| 7 | 8,0 | 5,4 | 19,0 | 43,2 | 152 | 102,6 | 29,16 | 361 | 64 | |
| 8 | 8,0 | 4,4 | 20,0 | 35,2 | 160 | 88 | 19,36 | 400 | 64 | |
| 9 | 8,0 | 5,3 | 20,0 | 42,4 | 160 | 106 | 28,09 | 400 | 64 | |
| 10 | 10,0 | 6,8 | 20,0 | 68 | 200 | 136 | 46,24 | 400 | 100 | |
| 11 | 9,0 | 6,0 | 21,0 | 54 | 189 | 126 | 36,00 | 441 | 81 | |
| 12 | 11,0 | 6,4 | 22,0 | 70,4 | 242 | 140,8 | 40,96 | 484 | 121 | |
| 13 | 9,0 | 6,8 | 22,0 | 61,2 | 198 | 149,6 | 46,24 | 484 | 81 | |
| 14 | 11,0 | 7,2 | 25,0 | 79,2 | 275 | 180 | 51,84 | 625 | 121 | |
| 15 | 12,0 | 8,0 | 28,0 | 96 | 336 | 224 | 64,00 | 784 | 144 | |
| 16 | 12,0 | 8,2 | 29,0 | 98,4 | 348 | 237,8 | 67,24 | 841 | 144 | |
| 17 | 12,0 | 8,1 | 30,0 | 97,2 | 360 | 243 | 65,61 | 900 | 144 | |
| 18 | 12,0 | 8,5 | 31,0 | 102 | 372 | 263,5 | 72,25 | 961 | 144 | |
| 19 | 14,0 | 9,6 | 32,0 | 134,4 | 448 | 307,2 | 92,16 | 1024 | 196 | |
| 20 | 14,0 | 9,0 | 36,0 | 126 | 504 | 324 | 81,00 | 1296 | 196 | |
| Сумма | 192,0 | 123,8 | 446,0 | 1276,3 | 4581,0 | 2997,4 | 837,7 | 10828,0 | 1958,0 | |
| Ср. значение | 9,6 | 6,19 | 22,3 | 63,82 | 229,1 | 149,9 | 41,887 | 541,4 | 97,9 |
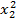


Найдем средние квадратические отклонения признаков:
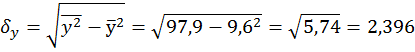


1. Для нахождения параметров линейного уравнения множественной регрессии

необходимо решить систему линейных уравнений относительно неизвестных параметров a, b1, b2 (2.2) либо воспользоваться готовыми формулами (2.3)
Рассчитаем сначала парные коэффициенты корреляции:



Находим по формулам (2.3) коэффициенты чистой регрессии и параметр а


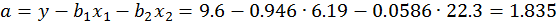
Таким образом, получили следующее уравнение множественной регрессии:

Уравнение регрессии показывает, что при увеличении ввода в действие основных фондов на 1% (при неизменном уровне удельного веса рабочих высокой квалификации) выработка продукции на одного рабочего увеличивается в среднем на 0,946 тыс. руб., а при увеличении удельного веса рабочих высокой квалификации в общей численности рабочих на 1% (при неизменном уровне ввода в действие новых основных фондов) выработка продукции на одного рабочего увеличивается в среднем на 0,086 тыс. руб.
После нахождения уравнения регрессии составим новую расчетную таблицу для определения теоретических значений результативного признака, остаточной дисперсии и средней ошибки аппроксимации
| Номер предприятия | y | x1 | X2 |  |
|
| Ai, % |
| 1 | 7,0 | 3,9 | 10,0 | 6,380 | 0,620 | 0,384 | 8,851 |
| 2 | 7,0 | 3,9 | 14,0 | 6,723 | 0,277 | 0,077 | 3,960 |
| 3 | 7,0 | 3,7 | 15,0 | 6,619 | 0,381 | 0,145 | 5,440 |
| 4 | 7,0 | 4,0 | 16,0 | 6,989 | 0,011 | 0,000 | 0,163 |
| 5 | 7,0 | 3,8 | 17,0 | 6,885 | 0,115 | 0,013 | 1,643 |
| 6 | 7,0 | 4,8 | 19,0 | 8,002 | -1,002 | 1,004 | 14,317 |
| 7 | 8,0 | 5,4 | 19,0 | 8,570 | -0,570 | 0,325 | 7,123 |
| 8 | 8,0 | 4,4 | 20,0 | 7,709 | 0,291 | 0,084 | 3,633 |
| 9 | 8,0 | 5,3 | 20,0 | 8,561 | -0,561 | 0,314 | 7,010 |
| 10 | 10,0 | 6,8 | 20,0 | 9,980 | 0,020 | 0,000 | 0,202 |
| 11 | 9,0 | 6,0 | 21,0 | 9,309 | -0,309 | 0,095 | 3,429 |
| 12 | 11,0 | 6,4 | 22,0 | 9,773 | 1,227 | 1,507 | 11,158 |
| 13 | 9,0 | 6,8 | 22,0 | 10,151 | -1,151 | 1,325 | 12,789 |
| 14 | 11,0 | 7,2 | 25,0 | 10,786 | 0,214 | 0,046 | 1,944 |
| 15 | 12,0 | 8,0 | 28,0 | 11,800 | 0,200 | 0,040 | 1,668 |
| 16 | 12,0 | 8,2 | 29,0 | 12,075 | -0,075 | 0,006 | 0,622 |
| 17 | 12,0 | 8,1 | 30,0 | 12,066 | -0,066 | 0,004 | 0,547 |
| 18 | 12,0 | 8,5 | 31,0 | 12,530 | -0,530 | 0,280 | 4,413 |
| 19 | 14,0 | 9,6 | 32,0 | 13,656 | 0,344 | 0,118 | 2,459 |
| 20 | 14,0 | 9,0 | 36,0 | 13,431 | 0,569 | 0,324 | 4,067 |
| Сумма | 192,000 | 123,800 | 446,000 | 191,992 | 0,008 | 6,093 | 95,437 |
| Среднее значение | 9,600 | 6,190 | 22,300 | 9,600 | - | 0,305 | 4,772 |
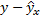

Остаточная дисперсия

Средняя ошибка аппроксимации:
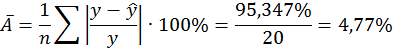
Качество модели, исходя из относительных отклонений по каждому наблюдению, признается хорошим, т.к. средняя ошибка аппроксимации не превышает 10%.
Коэффициенты β1 и β2 стандартизированного уравнения регрессии  , находятся по формуле 2.6.
, находятся по формуле 2.6.

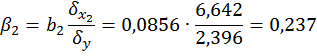
Т.е. уравнение будет выглядеть следующим образом:
ar w:top="1134" w:right="850" w:bottom="1134" w:left="1701" w:header="720" w:footer="720" w:gutter="0"/><w:cols w:space="720"/></w:sectPr></w:body></w:wordDocument>"> 
Так как стандартизованные коэффициенты регрессии можно сравнивать между собой, то можно сказать, что ввод в действие новых основных фондов оказывает большее влияние на выработку продукции, чем удельный вес рабочих высокой квалификации.
Сравнивать влияние факторов на результат можно также при помощи средних коэффициентов эластичности

Вычисляем:

Т.е. увеличение только основных фондов (от своего среднего значения) или только удельного веса рабочих высокой квалификации на 1% увеличивает в среднем выработку продукции на 0,61% или 0,20% соответственно. Таким образом, подтверждается большее влияние на результат y фактора x1, чем фактора x2.
2. Коэффициент парной корреляции мы уже нашли:

Они указывают на весьма сильную связь каждого фактора с результатом, а также высокую межфакторную зависимость (факторы x1 и x2 явно коллинеарны, т.к. r=0,943>0,7) При такой сильной межфакторной зависимости рекомендуется один из факторов исключить из рассмотрения.
Частные коэффициенты корреляции характеризуют тесноту связи между результатом и соответствующим фактором при элиминировании (устранении влияния) других факторов, включенных в уравнение регрессии.
При двух факторах частные коэффициенты корреляции рассчитываются следующим образом:


Если сравнить коэффициенты парной и частной корреляции, то можно увидеть, что из-за высокой межфакторной зависимости коэффициенты парной корреляции дают завышенные оценки тесноты связи. Именно по этой причине рекомендуется при наличии сильной коллинеарности (взаимосвязи) факторов исключать из исследования тот фактор, у которого теснота парной зависимости меньше, чем теснота межфакторной связи.
Коэффициент множественной корреляции определить через матрицы парных коэффициентов корреляции

где
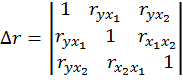
- Определитель матрицы парных коэффициентов корреляции;
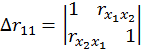
- Определитель матрицы межфакторной корреляции.
Находим:
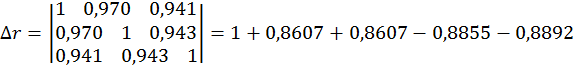


Коэффициент множественной корреляции:

Аналогичный результат получим при использовании формул (2,7) и (2,9)

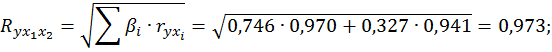
Коэффициент множественной корреляции указывает на весьма сильную связь всего набора факторов с результатом.
3. Нескорректированный коэффициент множественной детерминации  оценивает долю дисперсии результата за счет представленных в уравнении факторов в общей вариации результата. Здесь эта доля составляет 94,7% и указывает на весьма высокую степень обусловленности вариации результата вариацией факторов, иными словами – на весьма тесную связь факторов с результатом.
оценивает долю дисперсии результата за счет представленных в уравнении факторов в общей вариации результата. Здесь эта доля составляет 94,7% и указывает на весьма высокую степень обусловленности вариации результата вариацией факторов, иными словами – на весьма тесную связь факторов с результатом.
Скорректированный коэффициент множественной детерминации

определяет тесноту связи с учетом степеней свободы общей и остаточной дисперсий. Он дает такую оценку тесноты связи, которая не зависит от числа факторов и поэтому может сравниваться по разным моделям с разным числом факторов. Оба коэффициента указывают на весьма высокую (более 94%) детерминированность результата y в модели факторами x1 и х2
4. Оценку надежности уравнения регрессии в целом и показателя тесноты связи  дает F-критерий Фишера:
дает F-критерий Фишера:
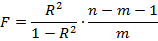
В нашем случае фактическое значение F -критерия Фишера:

Получили, что  (при n=20), т.е. вероятность случайно получить такое значение F -критерия не превышает допустимый уровень значимости 5%. Следовательно, полученное значение не случайно, оно сформировалось под влиянием существенных факторов, т.е. подтверждается статистическая значимость всего уравнения и показателя тесноты связи
(при n=20), т.е. вероятность случайно получить такое значение F -критерия не превышает допустимый уровень значимости 5%. Следовательно, полученное значение не случайно, оно сформировалось под влиянием существенных факторов, т.е. подтверждается статистическая значимость всего уравнения и показателя тесноты связи
5. Оценим статистическую значимость параметров чистой регрессии с помощью t-критерия Стьюдента. Рассчитаем стандартные ошибки коэффициентов регрессии по формулам (2.18) и (2.19).
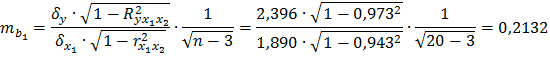

Фактические значения t -критерия Стьюдента:

Табличное значение критерия при уровне значимости α = 0,05 и числе степеней свободы k =17 составит tтабл (а =0,05; k= 17)=2,11. Таким образом, признается статистическая значимость параметра b1 , т.к.  , и случайная природа формирования параметра b2, т.к.
, и случайная природа формирования параметра b2, т.к. 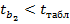
Доверительные интервалы для параметров чистой регрессии:

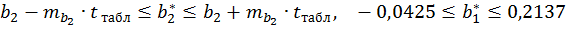
6. С помощью частных F-критериев Фишера оценим целесообразность включения в уравнение множественной регрессии фактора х1 после х2 и фактора х2 после х1 при помощи формул (2.15).

Найдем 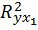 и
и 


Имеем:

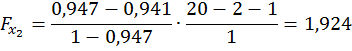
Получили, что 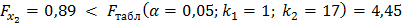 Следовательно, включение в модели фактора х2 после того, как в модель включен фактор х1 статистически нецелесообразно: прирост факторной дисперсии за счет дополнительного признака х2 оказывается незначительным, несущественным; фактор х2 включать в уравнение после фактора х1 не следует.
Следовательно, включение в модели фактора х2 после того, как в модель включен фактор х1 статистически нецелесообразно: прирост факторной дисперсии за счет дополнительного признака х2 оказывается незначительным, несущественным; фактор х2 включать в уравнение после фактора х1 не следует.
Если поменять первоначальный порядок включения факторов в модель и рассмотреть вариант включения x1 после x2, то результат расчета частного F -критерия для x1 будет иным. 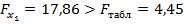 , т.е. вероятность его случайного формирования меньше принятого стандарта a = 0,05 (5%). Следовательно, значение частного F -критерия для дополнительно включенного фактора x1 не случайно, является статистически значимым, надежным, достоверным: прирост факторной дисперсии за счет дополнительного фактора x1 является существенным. Фактор x1 должен присутствовать в уравнении, в том числе в варианте, когда он дополнительно включается после фактора x2.
, т.е. вероятность его случайного формирования меньше принятого стандарта a = 0,05 (5%). Следовательно, значение частного F -критерия для дополнительно включенного фактора x1 не случайно, является статистически значимым, надежным, достоверным: прирост факторной дисперсии за счет дополнительного фактора x1 является существенным. Фактор x1 должен присутствовать в уравнении, в том числе в варианте, когда он дополнительно включается после фактора x2.
7. Общий вывод состоит в том, что множественная модель с факторами х1 и х2 с 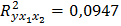 содержит неинформативный фактор х2. Если исключить фактор х2, то можно ограничиться уравнением парной регрессии:
содержит неинформативный фактор х2. Если исключить фактор х2, то можно ограничиться уравнением парной регрессии:

Найдем его параметры:


Таким образом,