 2018-02-14
2018-02-14 2492
2492Оглавление
Лабораторный практикум по парной регрессии и корреляции.. 1
РЕШЕНИЕ ЗАДАЧИ.. 5
ТЕМА 2 Отбор факторов при построении множественной регрессии.. 13
Вопрос 3: «Мультиколлинеарность». 19
РЕШЕНИЕ ТИПОВОЙ ЗАДАЧИ.. 21
Решение задач с помощью MS Excel. 28
ТЕМА 3 Регрессионные модели с переменной структурой.. 33
Вопрос 1. «Фиктивные переменные во множественной регрессии». 33
Вопрос 2. Предпосылки метода наименьших квадратов. 38
Вопрос 3. «Гетероскедатистичность». 41
РАЗДЕЛ 3. 42
Лекция 6: «ХАРАКТЕРИСТИКИ ВРЕМЕННЫХ РЯДОВ». 42
Вопрос 1: «ОСНОВНЫЕ ЭЛЕМЕНТЫ ВРЕМЕННОГО РЯДА». 42
Вопрос 2: «АВТОКОРРЕЛЯЦИЯ УРОВНЕЙ ВРЕМЕННОГО РЯДА И ВЫЯВЛЕНИЕ ЕГО СТРУКТУРЫ». 43
Вопрос 3: «Моделирование тенденции временного ряда». 49
Вопрос 4: «Моделирование сезонных и циклических колебаний». 49
Вопрос 5: «Моделирование тенденции временного ряда при наличии структурных изменений». 53
Лабораторный практикум по парной регрессии и корреляции
Парная (простая) линейная регрессия представляет собой модель, где среднее значение зависимой (объясняемой) переменной рассматривается как функция одной независимой (объясняющей) переменной x, т.е. это модель вида:
 ,
,
где: y – зависимая переменная (результативный признак);
х – независимая, объясняющая переменная (признак-фактор)
Так же y называют результативным признаком, а x признаком-фактором. Знак «^» означает, что между переменными x и y нет строгой функциональной зависимости.
Практически в каждом отдельном случае величина y складывается из двух слагаемых:
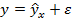
где y – фактическое значение результативного признака;  – теоретическое значение результативного признака, найденное исходя из уравнения регрессии;
– теоретическое значение результативного признака, найденное исходя из уравнения регрессии;  – случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии. Случайная величина e называется также возмущением. Она включает влияние не учтенных в модели факторов, случайных ошибок и особенностей измерения. Ее присутствие в модели порождено тремя источниками: спецификацией модели, выборочным характером исходных данных, особенностями измерения переменных.
– случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии. Случайная величина e называется также возмущением. Она включает влияние не учтенных в модели факторов, случайных ошибок и особенностей измерения. Ее присутствие в модели порождено тремя источниками: спецификацией модели, выборочным характером исходных данных, особенностями измерения переменных.
Различают линейные и нелинейные регрессии.
Линейная регрессия: y=a+b*x+ε.
Нелинейные регрессии делятся на два класса: регрессия, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, и регрессия, нелинейные по оцениваемым параметрам.
Регрессии, нелинейные по объясняющим переменным:
Ø Полиномы разных степеней y=a+b1*x+b2*x2+b3*x3+ε
Ø Равносторонняя гипербола 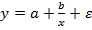
Регрессии, нелинейные по оцениваемым параметрам:
Степенная y=a*xb*ε
Показательная y=a*bx*ε
Экспоненциальная y=ea+b*x*ε
Построение уравнения регрессии сводится к оценке ее параметров. Для оценки параметров регрессий, линейных по параметрам, используют метод наименьших квардатов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических  минимальна, т.е.
минимальна, т.е.

Для линейных и нелинейных уравнений, приводимых к линейным, решается следующая система относительно a и b:

Можно воспользоваться готовыми формулами, которые вытекают из этой системы:
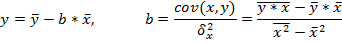
Ковариация – числовая характеристика совместного распределения двух случайных величин, равная математическому ожиданию произведения отклонений этих случайных величин от их математических ожиданий. Дисперсия – характеристика случайной величины, определяемая как математическое ожидание квадрата отклонения случайной величины от ее математического ожидания. Математическое ожидание – сумма произведений значений случайной величины на соответствующие вероятности
Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции rxy для линейной регрессии (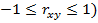

И индекс корреляции pxy - для нелинейной регрессии 

Оценку качества построенной модели даст коэффициент (индекс) детерминации, а также средняя ошибка аппроксимации.
Средняя ошибка аппроксимации – среднее отклонение расчетных значений от фактических:

Допустимый предел значений  - не более 8-10%.
- не более 8-10%.
Средний коэффициент эластичности  показывает, на сколько процентов в средней по совокупности изменится результат у от свой средней величины при изменении фактора х на 1% от своего среднего значения:
показывает, на сколько процентов в средней по совокупности изменится результат у от свой средней величины при изменении фактора х на 1% от своего среднего значения:

После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Оценка значимости уравнения регрессии в целом производится на основе F -критерия Фишера, которому предшествует дисперсионный анализ.
Согласно основной идее дисперсионного анализа, общая сумма квадратов отклонений переменной y от среднего значения  раскладывается на две части – «объясненную» и «необъясненную»
раскладывается на две части – «объясненную» и «необъясненную»

Где:



Схема дисперсионного анализа имеет вид, представленный в таблице (n – число наблюдений, m – число параметров при переменной x)
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Дисперсия на одну степень свободы |
| Общая |  | 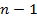 |  |
| Факторная |  | m |  |
| Остаточная | 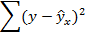 |  |  |
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду (степени свободы – это числа, показывающие количество элементов варьирования, которые могут принимать произвольные значения, не изменяющие заданных характеристик). Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F -критерия Фишера (коэффициент (индекс) детерминации R2)

Коэффициент детерминации – квадрат коэффициента или индекса корреляции.
F-тест(F-критерий Фишера – оценивание качества уравнения регрессии – состоит в проверке гипотезы Н0 о статистической значимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера Fфакт определяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:

где:
n – число единиц совокупности;
m – число параметров при переменных х.
Fтабл – это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости а. Уровень значимости а – вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно а принимается равной 0,05 или 0,01.
Если Fтабл < Fфакт, то Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если Fтабл > Fфакт, то гипотеза Н0 не отклоняется и признается статистическая значимость, ненадежность уравнения регрессии.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитывается t-критерий Стьюдента и доверительные интервалы каждой из показателей. Выдвигается гипотеза Н0 о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка знамчимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки:

Случайные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
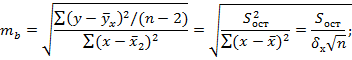


Домашнее задание
Сравнивая фактическое и критическое (табличное) значения t-статистики – tтабл и tфакт – принимаем или отвергаем гипотезу Н0.
Связь между F-критерием Фишера и t-статистикой Стьюдента выражается равенством

Если tтабл < tфакт, то Н0 отклоняется, т.е. a,b и  признается случайная природа формирования a,b, или
признается случайная природа формирования a,b, или
Для расчета доверительного интервала определяем предельную ошибку ∆ для каждого показателя:

Формулы для расчета доверительных интервалов имеют следующий вид:


Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, так как он не может одновременно принимать и положительное, и отрицательное значения.
Прогнозное значение yp определяется путем подстановки в уравнение регрессии  соответствующего (прогнозного) значения хр . Вычисляется средняя стандартная ошибка прогноза
соответствующего (прогнозного) значения хр . Вычисляется средняя стандартная ошибка прогноза 

где 
и строится доверительный интервал прогноза:

РЕШЕНИЕ ЗАДАЧИ
По территориям региона приводятся данные за определенный период.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Требуется:
1. Построить линейное уравнение парной регрессии y по x.
2. Рассчитать линейный коэффициент парной корреляции, коэффициент детерминации и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость уравнения регрессии в целом и отдельных параметров регрессии и корреляции с помощью F -критерия Фишера и t -критерия Стьюдента.
4. Выполнить прогноз заработной платы y при прогнозном значении среднедушевого прожиточного минимума x, составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
6. На одном графике отложить исходные данные и теоретическую прямую.
Решение
Для расчета параметров уравнения линейной регрессии строим расчетную таблицу
1.
| № | Х | У | У*Х | Х2 |
|  |  | Ai | ||
| 1 | 78 | 133 | 10374 | 6084 | 17689 | 148,78 | -15,78 | 249,008 | 11,86 | |
| 2 | 82 | 148 | 12136 | 6724 | 21904 | 152,46 | -4,46 | 19,8916 | 3,01 | |
| 3 | 87 | 134 | 11658 | 7569 | 17956 | 157,06 | -23,06 | 531,764 | 17,2 | |
| 4 | 79 | 154 | 12166 | 6241 | 23716 | 149,7 | 4,3 | 18,49 | 2,79 | |
| 5 | 89 | 162 | 14418 | 7921 | 26244 | 158,9 | 3,1 | 9,61 | 1,91 | |
| 6 | 106 | 195 | 20670 | 11236 | 38025 | 174,54 | 20,46 | 418,612 | 10,49 | |
| 7 | 67 | 139 | 9313 | 4489 | 19321 | 138,66 | 0,34 | 0,1156 | 0,24 | |
| 8 | 88 | 158 | 13904 | 7744 | 24964 | 157,98 | 0,02 | 0,0004 | 0,012 | |
| 9 | 73 | 152 | 11096 | 5329 | 23104 | 144,18 | 7,82 | 61,1524 | 5,144 | |
| 10 | 87 | 162 | 14094 | 7569 | 26244 | 157,06 | 4,94 | 24,4036 | 3,049 | |
| 11 | 76 | 159 | 12084 | 5776 | 25281 | 146,94 | 12,06 | 145,444 | 7,584 | |
| 12 | 115 | 173 | 19895 | 13225 | 29929 | 182,82 | -9,82 | 96,4324 | 5,676 | |
| Итого | 1027 | 1869 | 161808 | 89907 | 294377 | 1869,08 | -0,08 | 1574,92 | ||
| Среднее значение | 85,58 | 155,75 | 13484,00 | 7492,25 | 24531,42 | 155,76 | 131,24 | 0,00 | ||
| δ | 12,952 | 16,53 | ||||||||
| δ2 | 167,74 | 273,35 |
По формулам находим параметры регрессии


Получено уравнение регрессии:
у= 77,02+0,92* х
Параметр регрессии позволяет сделать вывод, что с увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб. (или 92 коп.). После нахождения уравнения регрессии заполняем столбцы 7–10
2. Тесноту линейной связи оценит коэффициент корреляции:
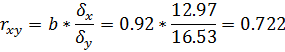
Т.к. значение коэффициента корреляции больше 0,7, то это говорит о наличии весьма тесной линейной связи между признаками.

Это означает, что 52% вариации заработной платы (y) объясняется вариацией фактора x – среднедушевого прожиточного минимума.
Качество модели определяет средняя ошибка аппроксимации

Качество построенной модели оценивается как хорошее, так как A не превышает 10%.
3. Оценку статистической значимости уравнения регрессии в целом проведем с помощью F -критерия Фишера. Фактическое значение F -критерия по формуле составит:

Табличное значение критерия при пятипроцентном уровне значимости и степенях свободы k1=1 и k2=12 - 2 =10 составляет F табл. = 4,96. Так как Fфакт =10,41> Fтабл = 4,96, то уравнение регрессии признается статистически значимым.
Оценку статистической значимости параметров регрессии и корреляции проведем с помощью t -статистики Стьюдента и путем расчета доверительного интервала каждого из параметров.
Табличное значение t -критерия для числа степеней свободы df=n-2=12-2=10 и уровня значимости α=0,05 составит tтабл = 2,23. Определим стандартные ошибки mа, mb,  (остаточная дисперсия на одну степень свободы
(остаточная дисперсия на одну степень свободы  )
)
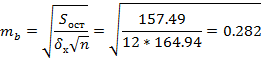


Тогда



Фактические значения t-статистики превосходят табличное значение:
ta=3.26>tтабл;  =3.16 > tтабл=2.3;
=3.16 > tтабл=2.3; 
Поэтому параметры a, b и rxy не случайно отличаются от нуля, а статистически значимы.
Рассчитаем доверительные интервалы для параметров регрессии a и b. Для этого определим предельную ошибку для каждого показателя:




Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью p =1-a = 0,95 параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. являются статистически значимыми и существенно отличны от нуля.
4. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:  руб., тогда индивидуальное прогнозное значение заработной платы составит:
руб., тогда индивидуальное прогнозное значение заработной платы составит: 
Ошибка прогноза составит:

Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит

Доверительный интервал прогноза:

Выполненный прогноз среднемесячной заработной платы является надежным (р=1-α=1-0,05=0,95) и находится в пределах от 131,92 руб. до 190,66 руб.
В заключение решения задачи построим на одном графике исходные данные и теоретическую прямую

Решение задачи в MS Excel.
C помощью инструмента анализа данных Регрессия можно получить результаты регрессионной статистики, дисперсионного анализа, доверительных интервалов, остатки и графики подбора линии регрессии.
Если в меню сервис еще нет команды Анализ данных, то необходимо сделать следующее. В главном меню последовательно выбираем Сервис→Надстройки и устанавливаем «флажок» в строке Пакет анализа

Далее следуем по следующему плану.
1. Если исходные данные уже внесены, то выбираем Сервис→Анализ данных→Регрессия.
3. Заполняем диалоговое окно ввода данных и параметров вывода

Заполнение необходимых значений.
Здесь:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные признака- фактора;
Метки – «флажок», который указывает, содержи ли первая строка названия столбцов;
Константа – ноль – «флажок», указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
Новый рабочий лист – можно указать произвольное имя нового листа (или не указывать, тогда результаты выводятся на вновь созданный лист).
Получаем следующие результаты для рассмотренного выше примера:

Откуда выписываем, округляя до 4 знаков после запятой и переходя к нашим обозначениям:

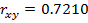
Коэффициент дерерминации:

Фактическое значение F-критерия Фишера:
F=10.8280
Остаточная дисперсия на одну степень свободы:

Корень квадратный из остаточной дисперсии (стандартная ошибка):

Стандартные ошибки для параметров регрессии:

Фактические значения t-критерия Стьюдента:



Как видим, найдены все рассмотренные выше параметры и характеристики уравнения регрессии, за исключением средней ошибки аппроксимации (значение t-критерия Стьюдента для коэффициента корреляции совпадает с tb). Результаты «ручного учета» от машинного отличаются незначительно (отличия связаны с ошибками округления).

