 2018-02-14
2018-02-14 1140
1140Простейшим видом измеряющих (регрессионных) моделей являются модели, характеризующие зависимость между двумя признаками (факторами), т.е. модели вида:
y = ƒ (x), где
y - зависимая переменная, т.е. результативный признак;
x - независимая или объясняющая переменная величина, т.е. признак фактора.
Например, бизнесменов, предпринимателей, экономистов, менеджеров интересует как изменится спрос на конкретный вид товара, если цены увеличатся на 12,3%, причем, при насыщенности рынка на данный товар на уровне 84,5%. Или в какой степени является целесообразным увеличение выпуска продукции на 15,5%, если цены на товары увеличиваются на 8,4%, а насыщенность рынка составляет не более 92%. Или еще, их интересует: какие товары надо производить, какого качества, в каком количестве, на какой рынок следует ориентироваться и т.д.
На все эти вопросы отвечают измеряющие эконометрические модели, если они подобраны, обоснованы адекватно, повторяю, если они выявлены с учетом объективной, достоверной информацией, а также учета комплекса внутренних и внешних факторов. В связи с этим хотелось бы, чтобы слушатели внимательно относились к эконометрическим моделям, исследованиям.
При количественной оценке связей между двумя переменными возможны использования следующих формул:
1. у = а + bx; 6. y = a · bx;
2. y = а +  ; 7. y =
; 7. y =  ;
;
3. y = a · xb; 8. ℓg y = a + bx + cx2;
4. y =  ; 9. y =
; 9. y =  ;
;
5. y = a + bx + cx2; 10. y = a + bx + cx2 + dx3 и другие.
Пример 1. Предположим имеются данные, характеризующие динамику спроса в зависимости от цены
у - спрос х - цена
35,4 18,1
36,2 17,4
36,8 17,1
37,1 16,8
37,7 16,3
37,9 16,1
Требуется исследовать, измерить дальнейшее поведение спроса, если тенденция снижения цен сохранится.
Решение аналогичных задач в основном состоит из четырех последовательных и в то же время взаимосвязанных этапов: анализ исходной информации, следовательно, определение тенденции поведения системы; выбор математической формы связи; решение системы; анализ результатов решения системы, следовательно, обоснование конкретных выводов и рекомендации.
Этап 1. Анализ данных. Анализ данных дает основание утверждать, что спрос увеличивается, а цена снижается. Уровень роста спроса составляет около 7,1%, а уровень снижения цен - 11,0%.
Итак, со снижением цен, спрос увеличивается, причем уровень снижения цен выше, чем уровень увеличения спроса.
Этап 2. Выбор функции связи. Есть основание утверждать, данная зависимость имеет обратнопропорциональный характер, типа y = a + , где
у - спрос;
х - цена;
a и b - параметры системы;
Этап 3. Решение системы. Составляем систему стандартных уравнений:
 (1)
(1)
Для решения системы (1) желательно составлять вспомогательную таблицу.
Таблица 1
Для решения параметров а и b
| № пп | у | х |  | у | х2 |  | х · у | у2 |
| 1 | 35,4 | 18,1 | 0,055 | 1,96 | 327,61 | 0,003 | 640,74 | 1253,16 |
| 2 | 36,2 | 17,4 | 0,057 | 2,08 | 302,76 | 0,003 | 629,88 | 1310,44 |
| 3 | 36,8 | 17,1 | 0,058 | 2,15 | 292,41 | 0,003 | 629,28 | 1354,24 |
| 4 | 37,1 | 16,8 | 0,060 | 2,21 | 282,24 | 0,004 | 623,28 | 1376,41 |
| 5 | 37,7 | 16,3 | 0,061 | 2,31 | 265,69 | 0,004 | 614,51 | 1421,29 |
| 6 | 37,9 | 16,1 | 0,062 | 2,35 | 259,21 | 0,004 | 610,19 | 1436,41 |
| ∑ | 221,1 | 101,8 | 0,353 | 13,06 | 1729,9 | 0,021 | 3747,9 | 8151,95 |
 На основе данных таблицы составляем систему стандартных уравнений в количественном отношении:
На основе данных таблицы составляем систему стандартных уравнений в количественном отношении:
221,1 = 6а + 0,353b
13,06 = 0,353а + 0,021b, (2)
Путем решения системы (2) имеем:
у = 18,61 +  .
.
Чтобы предвидеть возможные изменения спроса, вычисляем количественные характеристики спроса на основе полученной функции.
Итак,


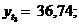


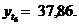
Таким образом, спрос увеличивается. Уровень роста составляет 6,0%, т.е. по выявленной функции уровень роста на 1,0% ниже по сравнению с заданной функцией спроса.
Для выяснения адекватности выводов, как правило, вычисляются коэффициенты корреляции и детерминации. Расчеты ведутся по формулам:
 ,
,
где r - коэффициент корреляции;
 - средняя величина фактора;
- средняя величина фактора;
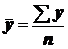 - средняя величина результативного признака;
- средняя величина результативного признака;
 - средняя величина из попарных произведений изучаемых признаков x и y;
- средняя величина из попарных произведений изучаемых признаков x и y;
 - среднее квадратическое отклонение факторного признака;
- среднее квадратическое отклонение факторного признака;
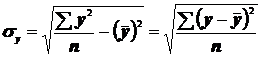 - среднее квадратическое отклонение результативного признака.
- среднее квадратическое отклонение результативного признака.
Коэффициент корреляции представляет собой величину, которая колеблется в пределах от 0 до ±1.
В тех случаях, когда коэффициент корреляции равен нулю, связь отсутствует. Если же он равен ±1, то связь между изучаемыми признаками функциональная, т.е. полная. Знак ± коэффициента корреляции указывает на направление связи (плюс - прямая связь, минус - обратная).
Если же r £ 0,5, связь между факторами можно считать слабой; если 0,51£ r £ 0,8, связь можно рассматривать как среднюю, а если r > 0,81 - связь можно отнести к более устойчивой категории.
Для выяснения доли связи между факторами вычисляется коэффициент детерминации:
r2 = D.
Измеряется этот коэффициент в процентах.
В случае многофакторной зависимости вычисляется коэффициент множественной корреляции:
 .
.
2.2. Базовая регрессионная модель
Итак, на основе регрессионных моделей определяется влияние отдельных (или комплекса) факторов на результативный признак.
Базовую модель регрессионного анализа можно представить следующим образом:
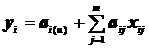 , где
, где
yi - результативный признак i-го вида;
xij - факторы j-го вида, которые влияют на i-ый результативный признак;
aij - влияние отдельных факторов j-го вида на i-ый результативный признак;
ai(u) - исходный уровень i-го результативного признака.
2.3. Основные виды и типы регрессионных моделей
Различают линейные и нелинейные виды регрессионных моделей. Линейный аналог регрессионных моделей имеет следующий вид:
y = a0 + a1x1 + a2x2 +... + akxk,
где x1, x2,..., xk - факторы, влияющие на результативный признак;
a1, a2,..., ak - уровень влияния каждого фактора на результативный признак;
a0 - начало отсчета, т.е. исходный уровень результативного признака.
Нелинейная регрессионная модель имеет следующий вид:
 .
.
Как правило, в линейных регрессионных моделях поведение результативного признака носит прямо пропорциональный характер в зависимости от переменных величин, а в нелинейных наоборот - колебания результативного показателя являются неадекватными, т.е. носят непропорциональный характер.
В зависимости от решаемых экономических задач следует различать три типа регрессионных моделей: простые, сложные, суперсложные.
В простых регрессионных моделях, как правило, исследуются два, в отдельных случаях три фактора.
В сложных моделях исследование осуществляется под влиянием более трех факторов на основе различных функций.
В суперсложных моделях исследование осуществляется на основе комплекса внутренних и внешних факторов.
2.4. Оценка уравнения регрессии и корреляции
Для оценки существенности параметров регрессии и корреляции необходимо вспомнить математическую статистику. Как правило, сначала формируется нулевая гипотеза (Н0), т.е. осуществляется F-тест. Для этого необходимо сравнить (Fфакт) и (Fтабл.). Значений F-критерия Фишера (Fтабл) определяется на основе следующей зависимости:
Fфакт. =  , где
, где
n - число единиц совокупности;
m - число параметров при переменных.
Fтабл. - это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы.
Если Fтабл. < Fфакт., то (Н0) - гипотеза о случайной природе оцениваемых характеристик отклоняется.
Если Fтабл. > Fфакт., то гипотеза (Н0) не отклоняется.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t- критерий Стьюдента и доверительные интервалы каждого из показателей. Оценка коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента производится путем сопоставления их значений с величиной случайной ошибки:
 ; ; .
; ; .
Случайные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
 ;
;
 ;
;
 .
.
Сравнивая фактическое и критическое (табличное) значения t-статистика - tтабл., tфакт. принимаем или отвергаем гипотезу (Н0).
Если Fтабл. < Fфакт., то (Н0) отклоняется, т.е. а, b и rху сформировались под влиянием систематически действующего фактора х.
Если Fтабл. > Fфакт., то гипотеза (Н0) не отклоняется и признается случайная природа формирования а, b, rху.
Для расчета доверительного интервала определяется предельная ошибка Δ для каждого показателя:
Δа = tтабл. ma, Δb = tтабл. mb.
Формулы для расчета доверительных интервалов имеют вид:
γа = а ± Δа; γа min = а - Δа; γа mах = а + Δа;
γb = b ± Δb; γаb min = b - Δb; γb mах = b + Δb.
Связь между F критерием Фишера и t-статистикой Стьюдента выражается равенством:
 .
.
Вопросы для самоконтроля
1. В чем сущность эконометрических моделей регрессии, в частности спроса, предложения?
2. Приведите основные типы эконометрических моделей спроса, выпуска продукции, ценообразования.
3. Приведите правила составления системы стандартных уравнений.
4. В чем эконометрический смысл коэффициента множественной корреляции?
5. Приведите суждения относительно выбора функции связи?
6. Как рассчитывается Fфакт.?
7. Когда отвергается (Н0) - гипотеза?
8. Сформулируйте F-тест.
9. Сформулируйте t-критерий Стьюдента.
10. Обоснуйте связь между F-критерием Фишера и t-статистикой Стьюдента.

