 2020-01-15
2020-01-15 552
552Аннотация
Цель данной работы - разработка и реализация алгоритмов блока "Эксперт для мультипроцессора" в проекте "Экспериментальная система автоматизации распараллеливания". На основании результатов анализа последовательной программы и характеристик конкретного мультипроцессора "Эксперт" генерирует и оценивает различные варианты распределения вычислений и локализаций данных. После выбора наилучшего варианта он вставляет в последовательную программу директивы OpenMP, посредством которых она превращается в параллельную программу для мультипроцессора. Кроме того, эксперт выдает информацию о прогнозируемой эффективности распараллеливания.
1. Введение
1.1 Распараллеливание программ
1.2 Стандарт OpenMP
1.3 Распараллеливание для OpenMP
1.4 Cуть и актуальность проблемы
2. Цели дипломной работы
2.1 Цели проекта "Система автоматизации распараллеливания"
2.2 Цели "Эксперта для мультипроцессора"
2.3 Входные данные
2.4 Выходные и сохраняемые данные
3. Предыдущие решения "систем автоматизации распараллеливания"
4. Построение решения задачи
4.1 Формат входных данных
4.2 Основные аспекты работы эксперта
4.3 Оценочные функции
5. Пошаговая реализация "Эксперта"
5.1 Шаг 1. Предварительный анализ
5.2 Шаг 2. Выбор варианта распараллеливания
5.3 Шаг 3. Выбор варианта локализации
5.4 Шаг 4. Внесение конечных комментариев в Базу Данных и подсчет ускорения
5.5 Примеры работы алгоритма
5.5.1 Программа "Якоби"
5.5.2 Программа "Sor"
5.5.3 Программа "Модифицированный SOR"
5.5.4 Программа "Модифицированный Якоби"
6. Заключение
Перечень принятых терминов
Литература
Введение
Распараллеливание программ
Последние годы во всем мире происходит бурное внедрение вычислительных кластеров. Это вызвано тем, что кластеры стали общедоступными и дешевыми аппаратными платформами для высокопроизводительных вычислений. Одновременно резко возрос интерес к проблематике вычислительных сетей (GRID) и широко распространяется понимание того, что внедрение таких сетей будет иметь громадное влияние на развитие человеческого общества, сравнимое с влиянием на него появления в начале века единых электрических сетей. Поэтому, рассматривая проблемы освоения кластеров необходимо принимать во внимание и то, что они являются первой ступенькой в создании таких вычислительных сетей.
Вычислительный кластер – это мультикомпьютер, состоящий из множества отдельных компьютеров (узлов), связанных между собой единой коммуникационной системой. Каждый узел имеет свою локальную оперативную память. При этом общей физической оперативной памяти для узлов не существует. Если в качестве узлов используются мультипроцессоры (мультипроцессорные компьютеры с общей памятью), то такой кластер называется SMP-кластером. Коммуникационная система обычно позволяет узлам взаимодействовать между собой только посредством передачи сообщений, но некоторые системы могут обеспечивать и односторонние коммуникации - позволять любому узлу выполнять массовый обмен информацией между своей памятью и локальной памятью любого другого узла. Кластеры дешевле мультипроцессорных ЭВМ с распределенной памятью, в которых используются специальные коммуникационные системы и специализированные узлы.
Если все входящие в состав вычислительного кластера узлы имеют одну и ту же архитектуру и производительность, то мы имеем дело с однородным вычислительным кластером. Иначе – с неоднородным.
В настоящее время, когда говорят о кластерах, то часто подразумевают однородность. Однако, для того, чтобы сохранить высокий уровень соотношения производительность/стоимость приходится при наращивании кластера использовать наиболее подходящие в данный момент процессоры, которые могут отличаться не только по производительности, но и по архитектуре. Поэтому постепенно большинство кластеров могут стать неоднородными кластерами.
Неоднородность же вносит следующие серьезные проблемы. Различие в производительности процессоров требует соответствующего учета при распределении работы между процессами, выполняющимися на разных процессорах. Различие в архитектуре процессоров требует подготовки разных выполняемых файлов для разных узлов, а в случае различий в представлении данных может потребоваться и преобразование информации при передаче сообщений между узлами (не говоря уже о трудностях использования двоичных файлов).
Тем не менее, любой кластер можно рассматривать как единую аппаратно-программную систему, имеющую единую коммуникационную систему, единый центр управления и планирования загрузки. Вычислительные сети (GRID) объединяют ресурсы множества кластеров, многопроцессорных и однопроцессорных ЭВМ, принадлежащих разным организациям и подчиняющихся разным дисциплинам использования. Разработка параллельных программ для них усложняется из-за следующих проблем.
Конфигурация выделяемых ресурсов (количество узлов, их архитектура и производительность) определяется только в момент обработки заказа на выполнение вычислений. Поэтому программист не имеет возможностей для ручной настройки программы на эту конфигурацию. Желательно осуществлять настройку программы на выделенную конфигурацию ресурсов динамически, без перекомпиляции. К изначальной неоднородности коммуникационной среды добавляется изменчивость ее характеристик, вызываемая изменениями загрузки сети. Учет такой неоднородности коммуникаций является очень сложной задачей.
Все это требует гораздо более высокого уровня автоматизации разработки параллельных программ, чем тот, который доступен в настоящее время прикладным программистам.
С 1992 года, когда мультикомпьютеры стали самыми производительными вычислительными системами, резко возрос интерес к проблеме разработки для них параллельных прикладных программ. К этому моменту уже было ясно, что трудоемкость разработки прикладных программ для многопроцессорных систем с распределенной памятью является главным препятствием для их широкого внедрения. За прошедший с тех пор период предложено много различных подходов к разработке параллельных программ, созданы десятки различных языков параллельного программирования и множество различных инструментальных средств.
На Рис. 1 описаны основные особенности симметричных мультипроцессорных систем (SMP). Для данных систем, как модель программирования для мультипроцессоров, возникла модель параллелизма по управлению (в западной литературе используется и другое название – модель разделения работы, work-sharing model). На мультипроцессорах в качестве модели выполнения используется модель общей памяти. В этой модели параллельная программа представляет собой систему нитей, взаимодействующих посредством общих переменных и примитивов синхронизации. Нить (по-английски "thread") – это легковесный процесс, имеющий с другими нитями общие ресурсы, включая общую оперативную память.
| Архитектура | Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью общей шины (базовые 2-4 процессорные SMP-сервера), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей. |
| Примеры | HP 9000 V-class, N-class; SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.). |
| Масштабируемость | Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число - не более 32 в реальных системах. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры. |
| Операционная система | Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам (scheduling), но иногда возможна и явная привязка. |
| Модель программирования | Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания. |
Рис. 1. Симметричные мультипроцессорные системы.
Основная идея модели параллелизма по управлению заключалась в следующем. Вместо программирования в терминах нитей предлагалось расширить языки специальными управляющими конструкциями – параллельными циклами и параллельными секциями. Создание и уничтожение нитей, распределение между ними витков параллельных циклов или параллельных секций (например, вызовов процедур) – все это брал на себя компилятор.
Первая попытка стандартизовать такую модель привела к появлению в 1990 году проекта языка PCF Fortran (проект стандарта X3H5). Однако, этот проект тогда не привлек широкого внимания и, фактически, остался только на бумаге. Возможно, что причиной этого было снижение интереса к мультипроцессорам и всеобщее увлечение мультикомпьютерами и HPF.
Однако, спустя несколько лет ситуация сильно изменилась. Во-первых, успехи в развитии элементной базы сделали очень перспективным и экономически выгодным создавать мультипроцессоры. Во-вторых, широкое развитие получили мультикомпьютеры с DSM (distributed shared memory - распределенная общая память), позволяющие программам на разных узлах взаимодействовать через общие переменные также, как и на мультипроцессорах (Convex Exemplar, HP 9000 V-class, SGI Origin 2000). В-третьих, не оправдались надежды на то, что HPF станет фактическим стандартом для разработки вычислительных программ.
Крупнейшие производители компьютеров и программного обеспечения объединили свои усилия и в октябре 1997 года выпустили описание языка OpenMP Fortran – расширение языка Фортран 77. Позже вышли аналогичные расширения языков Си и Фортран 90/95.
Параллельно развивалась модель передачи сообщений. Обобщение и стандартизация различных библиотек передачи сообщений привели в 1993 году к разработке стандарта MPI (Message Passing Interface). В модели передачи сообщений параллельная программа представляет собой множество процессов, каждый из которых имеет собственное локальное адресное пространство. Взаимодействие процессов - обмен данными и синхронизация - осуществляется посредством передачи сообщений. Однако разработчики MPI подвергаются и суровой критике за то, что интерфейс получился слишком громоздким и сложным для прикладного программиста.
Успешное внедрение OpenMP на мультипроцессорах и DSM-мультикомпьютерах резко активизировало исследования, направленные на поиски путей распространения OpenMP на мультикомпьютеры, кластеры и сети ЭВМ. Эти исследования сосредоточились, в основном, на двух направлениях:
· расширение языка средствами описания распределения данных;
· программная реализация системы DSM, использующей дополнительные указания компилятора, вставляемые им в выполняемую программу.
Первое направление представляется гораздо более перспективным для кластеров и сетей ЭВМ, однако трудно ожидать появления в ближайшие годы время стандарта нового языка (расширенного OpenMP). Поэтому все шире начинает использоваться гибридный подход, когда программа представляет собой систему взаимодействующих MPI-процессов, а каждый процесс программируется на OpenMP.
Такой подход имеет преимущества с точки зрения упрощения программирования в том случае, когда в программе есть два уровня параллелизма – параллелизм между подзадачами и параллелизм внутри подзадачи. Такая ситуация возникает, например, при использовании многообластных (многоблочных) методов решения вычислительных задач. Программировать на MPI сами подзадачи гораздо сложнее, чем их взаимодействие, поскольку распараллеливание подзадачи связано с распределением элементов массивов и витков циклов между процессами. Организация же взаимодействия подзадач таких сложностей не вызывает, поскольку сводится к обмену между ними граничными значениями. Нечто подобное программисты делали раньше на однопроцессорных ЭВМ, когда для экономии памяти на каждом временном шаге выполняли подзадачи последовательно друг за другом.
Широкое распространение SMP-кластеров также подталкивает к использованию гибридного подхода, поскольку использование OpenMP на мультипроцессоре может для некоторых задач (например, вычислений на неструктурных сетках) дать заметный выигрыш в эффективности.
Основной недостаток этого подхода также очевиден - программисту надо знать и уметь использовать две разные модели параллелизма и разные инструментальные средства [1].
Стандарт OpenMP
Интерфейс OpenMP [4] задуман как стандарт для программирования на масштабируемых SMP-системах в модели общей памяти (shared memory model). В стандарт OpenMP входят спецификации набора директив компилятора, процедур и переменных среды. Разработкой стандарта занимается организация OpenMP ARB (ARchitecture Board), в которую вошли представители крупнейших компаний - разработчиков SMP-архитектур и программного обеспечения. Спецификации для языков Fortran и C/C++ появились соответственно в октябре 1997 года и октябре 1998 года.

В OpenMP реализована "золотая середина" между двумя крайностями - полностью автоматическим распараллеливанием и кодированием с явным вызовом нитей; это подход, который основывается на распараллеливании обычных последовательных программ компилятором, но "с подсказками" пользователя, помещающего в исходный текст программы директивы в виде комментариев. Эти директивы указывают компилятору на параллелизм на уровне циклов и отдельных фрагментов программы. За счет этого OpenMP идеально подходит для разработчиков, желающих быстро распараллелить свои вычислительные программы с большими параллельными циклами.
Разработчик не создает новую параллельную программу, а просто последовательно добавляет в текст последовательной программы OpenMP-директивы. На Рис. 2 показано удобство OpenMP: необходимо вставить всего 2 строчки в программу, вычисляющую число пи, чтобы она стала параллельна.
Автоматическое распараллеливание весьма затруднено тем обстоятельством, что компилятору трудно (если вообще возможно) распознать взаимозависимости по данным, возможности возникновения тупиков, ситуаций типа "гонки" (race condition) и другие подобные ситуации, которые зачастую определяются поведением программы уже на этапе выполнения. Поэтому возможность получить "подсказку" от пользователя может быть очень ценна.
Однако стандарт OpenMP не ограничивается только набором директив, а специфицирует API [10], который, кроме директив компилятору, включает набор функций системы поддержки выполнения OpenMP-программ, а также переменные окружения. Далее мы рассмотрим основные особенности OpenMP применительно к языку Fortran [9]. Существуют аналогичные средства для языков Си/C++. В рамках OpenMP стандартная последовательная модель языка Fortran расширяется параллельными конструкциями SPMD (Single Program, Multiple Data), которые наиболее близки к традиционной "последовательной" идеологии.
В OpenMP используется модель параллельного выполнения fork/join. Программа начинает выполняться как один процесс, который в ОpenMP называется главной нитью (master thread). Этот процесс выполняется последовательно до тех пор, пока он не дойдет до первой параллельной конструкции (в простейшем случае - области, заключенной между директивами PARALLEL и END PARALLEL). В этот момент создается "бригада" (team) нитей, а "бригадиром" для нее является главная нить. Внутри бригады главная нить имеет номер 0, а число нитей в бригаде задается переменной окружения или может изменяться динамически перед началом выполнения параллельной области путем вызова соответствующей функции системы поддержки выполнения OpenMP-программ. Однако внутри параллельной области число нитей фиксировано.
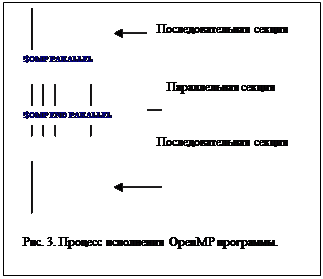
Кусок программы, заключенный между директивами PARALLEL и END PARALLEL, выполняется параллельно всеми нитями бригады (см. Рис. 3). Операторы программы, логически заключенные между этой парой директив, образуют, в терминологии OpenMP, лексическую (статическую) область действия соответствующей параллельной конструкции. Поскольку указанный блок программы может содержать вызовы подпрограмм, которые тоже могут выполняться параллельно, вводится понятие динамической области действия, который включает и подпрограммы, вызываемые из данного блока [3].
После завершения выполнения параллельной конструкции нити бригады синхронизируются, а выполнение продолжает только главная нить. Естественно, в программе может быть много параллельных конструкций; соответственно бригады нитей могут образовываться не один раз. OpenMP предусматривает возможность вложения параллельных конструкций (пар PARALLEL/END PARALLEL). Многие "ключи" (clauses) в директивах OpenMP позволяют указать атрибуты данных, действующие в период выполнения соответствующей параллельной конструкции.
По умолчанию, в параллельном регионе частными (приватными) являются индексы параллельных циклов DO, все остальные переменные, по умолчанию, общие. Однако это правило умолчания можно изменить, указав ключ DEFAULT(PRIVATE) или вовсе отменить, если задать DEFAULT(NONE). Счетчики фортрановских DO-циклов следует делать приватными (PRIVATE) для каждой нити бригады. Такие приватные объекты (простые переменные, массивы и т.д.) с точки зрения их обработки эквивалентны тому, как если бы для каждой нити имелась бы декларация нового объекта того же типа. Все ссылки на исходный объект в лексической области действия параллельной конструкции заменяются на ссылки на этот новый приватный объект.
Переменные, определенные как PRIVATE, при входе в параллельную конструкцию являются неопределенными для любой нити бригады. При использовании описателя FIRSTPRIVATE приватные копии переменных инициализируются данными из исходного объекта, существующего до входа в параллельную конструкцию. LASTPRIVATE отличается от параметра PRIVATE тем, что после выхода из цикла или из последней секции конечные значения, перечисленные в списке переменных, будут доступны для использования.
Директива THREADPRIVATE(список переменных) объявляет приватными в нитях параллельного региона переменные, описанные в программе. Директива указывается сразу после описания соответствующих переменных и не влияет на работу с ними вне параллельного региона. С ней связана директива COPYIN(список переменных)- для каждой нити параллельного региона создаются копии переменных, описанных в директиве threadprivate, копиям присваиваются текущие значения оригиналов. Имена, указанные в списках директивы threadprivate и параметра copyin, должны совпадать. COPING применяется с директивой parallel.
Существует возможность использования условного оператора: IF(cкалярное_логическое_выражение).
Если этот ключ указан, то соответствующая параллельная область кодов будет выполняться несколькими нитями только при условии, что "скалярное_логическое_выражение" истинно. Например, указав IF(N.GT.1000), можно заставить компилятор породить такую программу, что во время выполнения проверяется размерность (N) и программа выполнялась бы параллельно, только если эта размерность достаточно велика - больше 1000. Это позволяет избегать распараллеливания при маленьких размерностях, когда оно может оказаться невыгодным из-за большой доли накладных расходов.
Важным компонентом стандарта OpenMP является набор подпрограмм времени выполнения и переменных окружения, задающих среду OpenMP:
· subroutine OMP_SET_NUM_THREADS(N) - устанавливает число нитей, равное N.· integer function OMP_GET_NUM_THREADS() - возвращает число нитей в бригаде.· integer function OMP_GET_THREAD_NUM() -возвращает номер "текущей" нити (из которой произошел вызов функции) в бригаде.Кроме указаний на распределение работ между нитями, OpenMP имеет директиву SINGLE/END SINGLE, которая разрешает выполнять заключенный в нее блок Fortran-программы только одной нити.

Для распараллеливания циклов существует директива DO (см. Рис. 4). В качестве "ключей" можно указать описатели PRIVATE(список), FIRSTPRIVATE(список), SHARED(список), ключ REDUCTION, а также ключи ORDERED и SCHEDULE.
Ключ SCHEDULE используется для указания дисциплины планирования выполнения цикла нитями и имеет вид: SCHEDULE(тип[,M])
Он указывает, каким образом итерации цикла будут распределены для выполнения между нитями бригады. В качестве параметра "тип" можно указать следующие:
· STATIC [,m] - блочно-циклическое распределение итераций: первый блок из m итераций выполняет первая нить, второй блок - вторая и т.д. до последней нити, затем распределение снова начинается с первой нити; по умолчанию значение m равно 1;
· DYNAMIC [,m] - динамическое распределение итераций с фиксированным размером блока: сначала все нити получают порции из m итераций, а затем каждая нить, заканчивающая свою работу, получает следующую порцию опять-таки из m итераций;

· GUIDED [,m] - динамическое распределение итераций блоками уменьшающегося размера; аналогично распределению DYNAMIC, но размер выделяемых блоков все время уменьшается, что в ряде случаев позволяет аккуратнее сбалансировать загрузку нитей;
· RUNTIME - способ распределения итераций цикла выбирается во время работы программы в зависимости от значения переменной OMP_SCHEDULE.
·

Если в OpenMP-директиве END DO задано NOWAIT, в конце цикла нити не синхронизируются. Ключ REDUCTION директивы!$OMP PARALLEL DO обозначает редукционную переменную (см. Рис. 5).
В OpenMP имеется также возможность использовать сокращения, позволяющие объединять инструкции PARALLEL/END PARALLEL и DO/ENDDO в пару PARALLEL DO/END PARALLEL DO.
Директива SECTIONS (см. Рис. 6) используется для распределения работы между нитями в "неитерационном" случае. Ключи, как и ранее, могут указывать на тип переменных (PRIVATE, FIRSTPRIVATE и т.д.), а также содержать ключ REDUCTION. OpenMP-конструкция SECTIONS позволяет нескольким нитям выполнять параллельно обычный линейный участок программы на Фортране, разбитый на "секции" - блоки операторов языка. Эти секции могут содержать в себе, в частности, вызовы фортрановских подпрограмм.

Богатые возможности предоставляют средства OpenMP и для синхронизации. Соответствующие директивы позволяют, в частности, установить барьер (!$OMP BARRIER) или обеспечить синхронизацию (!$OMP ATOMIC), предохраняющую от одновременной записи несколькими нитями в одно и то же поле оперативной памяти. Это позволяет предотвратить ситуацию гонки. Другая полезная директива, о которой стоит упомянуть - это!$OMP FLUSH. Она заставляет в соответствующей точке программы получить "согласованное" между нитями состояние оперативной памяти (при этом переменные из регистров будут записаны в память, сбросятся буферы записи и т.д.). Пара директив MASTER: END MASTER выделяет участок кода, который будет выполнен только нитью-мастером. Остальные нити пропускают данный участок и продолжают работу с выполнения оператора, расположенного следом за директивой END MASTER. С помощью директивы CRITICAL оформляется критическая секция программы. В каждый момент времени в критической секции может находиться не более одной нити (см. Рис. 7). Если критическая секция уже выполняется какой-либо нитью P0, то все другие нити, выполнившие директиву для секции с данным именем, будут заблокированы, пока нить P0 не закончит выполнение данной критической секции. Как только P0 выполнит директиву END CRITICAL, одна из заблокированных на входе нитей войдет в секцию. Если на входе в критическую секцию стояло несколько нитей, то случайным образом выбирается одна из них, а остальные заблокированные нити продолжают ожидание. Все неименованные критические секции условно ассоциируются с одним и тем же именем.
Директива ORDERED заставляет коды Fortran, заключенные внутри пары ORDERED/END ORDERED, выполняться в "естественном" порядке (в той, в которой итерации цикла выполняются при нормальном последовательном выполнении). Эта пара директив может присутствовать только в динамической области действия директивы DO (или PARALLEL DO), в которой указан ключ ORDERED. Такие директивы могут использоваться для организации печати в нормальной - скажем, по возрастанию счетчика цикла- последовательности [2].








