 2020-01-14
2020-01-14 1756
1756
Самоорганизующиеся карты могут использоваться для решения задач моделирования, прогнозирования, кластеризации, поиска закономерностей в больших массивах данных, выявления наборов независимых признаков и сжатии информации.
Наиболее распространенное применение сетей Кохонена - решение задачи классификации без учителя, т.е. кластеризации.
Напомним, что при такой постановке задачи нам дан набор объектов, каждому из которых сопоставлена строка таблицы (вектор значений признаков). Требуется разбить исходное множество на классы, т.е. для каждого объекта найти класс, к которому он принадлежит.
В результате получения новой информации о классах возможна коррекция существующих правил классификации объектов.
Самым распространенным применением карт Кохонена является:
· разведочный анализ данных
· обнаружение новых явлений
В первом случае сеть Кохонена способна распознавать кластеры в данных, а также устанавливать близость классов. Таким образом, пользователь может улучшить свое понимание структуры данных, чтобы затем уточнить нейросетевую модель. Если в данных распознаны классы, то их можно обозначить, после чего сеть сможет решать задачи классификации. Сети Кохонена можно использовать и в тех задачах классификации, где классы уже заданы, - тогда преимущество будет в том, что сеть сможет выявить сходство между различными классами.
Во втором случае сеть Кохонена распознает кластеры в обучающих данных и относит все данные к тем или иным кластерам. Если после этого сеть встретится с набором данных, непохожим ни на один из известных образцов, то она не сможет классифицировать такой набор и тем самым выявит его новизну.
кластеризация нейронный сеть кохонен
3. МОДЕЛИРОВАНИЕ СЕТИ КЛАСТЕРИЗАЦИИ ДАННЫХ В MATLAB NEURAL NETWORK TOOLBOX
Программное обеспечение, позволяющее работать с картами Кохонена, сейчас представлено множеством инструментов. Это могут быть как инструменты, включающие только реализацию метода самоорганизующихся карт, так и нейропакеты с целым набором структур нейронных сетей, среди которых - и карты Кохонена; также данный метод реализован в некоторых универсальных инструментах анализа данных.
К инструментарию, включающему реализацию метода карт Кохонена, относятся MATLAB Neural Network Toolbox, SoMine, Statistica, NeuroShell, NeuroScalp, Deductor и множество других.
3.1 Самоорганизующиеся нейронные сети в MATLAB NNT
Для создания самоорганизующихся нейронных сетей, являющихся слоем или картой Кохонена, предназначены М-функции newc и newsom cooтветственно.
По команде help selforg можно получить следующую информацию об М-функциях, входящих в состав ППП Neural Network Toolbox и относящихся к построению сетей Кохонена (таблица 3.1):
Таблица 3.1
М-функции, входящие в состав ППП Neural Network Toolbox
| Self-organizing networks | Самоорганизующиеся сети |
| New networks | Формирование сети |
| newc newsom | Создание слоя Кохонена Создание карты Кохонена |
| Using networks | Работа с сетью |
| sim init adapt train | Моделирование Инициализация Адаптация Обучение |
| Weight functions | Функции расстояния и взвешивания |
| negdist | Отрицательное евклидово расстояние |
| Net input functons | Функции накопления |
| netsum | Сумма взвешенных входов |
| Transfer functions | Функции активации |
| compet | Конкурирующая функция активации |
| Topology functions | Функции описания топологии сети |
| gridtop hextop randtop | Прямоугольная сетка Гексагональная сетка Сетка со случайно распределенными узлами |
| Distance functions | Функции расстояния |
| dist boxdist mandist linkdist | Евклидово расстояние Расстояние максимального координатного смещения Расстояние суммарного координатного смешения Расстояние связи |
| Initialization functions | Функции инициализации сети |
| initlay initwb initcon midpoint | Послойная инициализация Инициализация весов и смещений Инициализация смещений с учетом чувствительности нейронов Инициализация весов по правилу средней точки |
| Learning functions | функции настройки параметров |
| learnk learncon learnsom | Правило настройки весов для слоя Кохонена Правило настройки смещений для слоя Кохонена Правило настройки весов карты Кохонена |
| Adapt functions | Функции адаптации |
| adaptwb | Адаптация весов и смещений |
| Training functions | Функции обучения |
| trainwb1 | Повекторное обучение весов и смещений |
| Demonstrations | Демонстрационные примеры |
| democ1 demosm1 demosm2 | Настройка слоя Кохонена Одномерная карта Кохонена Двумерная карта Кохонена |
3.1.1 Архитектура сети
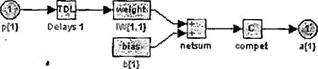
Промоделированная архитектура слоя Кохонена в MATLAB NNT показана на рисунке 3.1.

Рисунок 3.1 – Архитектура слоя Кохонена
Нетрудно убедиться, что это слой конкурирующего типа, поскольку в нем применена конкурирующая функция активации. Кроме того, архитектура этого слоя очень напоминает архитектуру скрытого слоя радиальной базисной сети. Здесь использован блок ndist для вычисления отрицательного евклидова расстояния между вектором входа 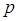 и строками матрицы весов
и строками матрицы весов  . Вход функции активации
. Вход функции активации  - это результат суммирования вычисленного расстояния с вектором смещения
- это результат суммирования вычисленного расстояния с вектором смещения  . Если все смещения нулевые, максимальное значение
. Если все смещения нулевые, максимальное значение 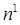 не может превышать 0. Нулевое значение возможно только, когда вектор входа
не может превышать 0. Нулевое значение возможно только, когда вектор входа  оказывается равным вектору веса одного из нейронов. Если смещения отличны от 0, то возможны и положительные значения для элементов вектора .
оказывается равным вектору веса одного из нейронов. Если смещения отличны от 0, то возможны и положительные значения для элементов вектора .
Конкурирующая функция активации анализирует значения элементов вектора и формирует выходы нейронов, равные 0 для всех нейронов, кроме одного нейрона-победителя, имеющего на входе максимальное значение. Таким образом, вектор выхода слоя  имеет единственный элемент, равный 1, который соответствует нейрону-победителю, а остальные равны 0. Такая активационная характеристика может быть описана следующим образом;
имеет единственный элемент, равный 1, который соответствует нейрону-победителю, а остальные равны 0. Такая активационная характеристика может быть описана следующим образом;
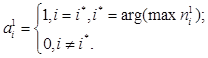 (3.1)
(3.1)
Заметим, что эта активационная характеристика устанавливается не на отдельный нейрон, а на слой. Поэтому такая активационная характеристика и получила название конкурирующей. Номер активного нейрона  определяет ту группу (кластер), к которой наиболее близок входной вектор.
определяет ту группу (кластер), к которой наиболее близок входной вектор.
3.1.2 Создание сети
Для формирования слоя Кохонена предназначена М-функция newc. Покажем, как она работает, на простом примере. Предположим, что задан массив из четырех двухэлементных векторов, которые надо разделить на 2 класса:
р = [.1.8.1.9;.2.9.1.8]
р =
0.1000 0.8000 0.1000 0.9000
0.2000 0.9000 0.1000 0.8000.
В этом примере нетрудно видеть, что 2 вектора расположены вблизи точки (0,0) и 2 вектора - вблизи точки (1,1). Сформируем слой Кохонена с двумя нейронами для анализа двухэлементных векторов входа с диапазоном значений от 0 до 1:
net = newc([0 1; 0 1],2).
Первый аргумент указывает диапазон входных значений, второй определяет количество нейронов в слое. Начальные значения элементов матрицы весов задаются как среднее максимального и минимального значений, т. е. в центре интервала входных значений; это реализуется по умолчанию с помощью М-функции midpoint при создании сети. Убедимся, что это действительно так:
wts = net.IW{l,l}
wts =
0.5000 0.5000
0.5000 0.5000.
Определим характеристики слоя Кохонена:
net.layers{1}
ans =
dimensions: 2
distanсeFcn: 'dist'
distances:[2x2 double]
initFcn:' initwb '
netinputFcn:'netsum'
positions:[0 1]
size:2
topologyFcn:'hextop'
transferFcn:'compet'
userdata:[1x1 struct].
Из этого описания следует, что сеть использует функцию евклидова расстояния dist, функцию инициализации initwb, функцию обработки входов netsum, функцию активации compet и функцию описания топологии hextop.
Характеристики смещений следующие:
net.biases{1}
ans =
initFcn:'initcon'
learn:1
learnFcn:'learncon'
learnParam:[1x1 struct]
size:2
userdata:[1x1 struct].
Смещения задаются функцией initcon и для инициализированной сети равны
net.b{l}
ans =
5.4366
5.4366.
Функцией настройки смещений является функция lеаrcon, обеспечивающая настройку с учетом параметра активности нейронов.
Элементы структурной схемы слоя Кохонена показаны на рисунке 3.2, а-б и могут быть получены с помощью оператора:
gensim(net)
Они наглядно поясняют архитектуру и функции, используемые при построении слоя Кохонена.
Теперь, когда сформирована самоорганизующаяся нейронная сеть, требуется обучить сеть решению задачи кластеризации данных. Напомним, что каждый нейрон блока compet конкурирует за право ответить на вектор входа  . Если все смещения равны 0, то нейрон с вектором веса, самым близким к вектору входа
. Если все смещения равны 0, то нейрон с вектором веса, самым близким к вектору входа  , выигрывает конкуренцию и возвращает на выходе значение 1; все другие нейроны возвращают значение 0.
, выигрывает конкуренцию и возвращает на выходе значение 1; все другие нейроны возвращают значение 0.

а б
Рисунок 3.2 – Элементы структурной схемы слоя Кохонена
3.1.3 Правило обучения слоя Кохонена
Правило обучения слоя Кохонена, называемое также правилом Кохонена, заключается в том, чтобы настроить нужным образом элементы матрицы весов. Предположим, что нейрон 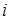 победил при подаче входа
победил при подаче входа  на шаге самообучения
на шаге самообучения  , тогда строка
, тогда строка  матрицы весов корректируется в соответствии с правилом Кохонена следующим образом:
матрицы весов корректируется в соответствии с правилом Кохонена следующим образом:
 . (3.2)
. (3.2)
Правило Кохонена представляет собой рекуррентное соотношение, которое обеспечивает коррекцию строки матрицы весов добавлением взвешенной разности вектора входа и значения строки на предыдущем шаге. Таким образом, вектор веса, наиболее близкий к вектору входа, модифицируется так, чтобы расстояние между ними стало еще меньше. Результат такого обучения будет заключаться в том, что победивший нейрон, вероятно, выиграет конкуренцию и в том случае, когда будет представлен новый входной вектор, близкий к предыдущему, и его победа менее вероятна, когда будет представлен вектор, существенно отличающийся от предыдущего. Когда на вход сети поступает все большее и большее число векторов, нейрон, являющийся ближайшим, снова корректирует свой весовой вектор. В конечном счете, если в слое имеется достаточное количество нейронов, то каждая группа близких векторов окажется связанной с одним из нейронов слоем. В этом и заключается свойство самоорганизации слоя Кохонена.
Настройка параметров сети по правилу Кохонена реализована в виде М-функции learnk.
3.1.4 Правило настройки смещений
Одно из ограничений всякого конкурирующего слоя состоит в том, что некоторые нейроны оказываются незадействованными. Это проявляется в том, что нейроны, имеющие начальные весовые векторы, значительно удаленные от векторов входа, никогда не выигрывают конкуренции, независимо от того как долго продолжается обучение. В результате оказывается, что такие векторы не используются при обучении и соответствующие нейроны никогда не оказываются победителями. Такие нейроны-неудачники называются "мертвыми" нейронами, поскольку они не выполняют никакой полезной функции. Чтобы исключить такую ситуацию и сделать нейроны чувствительными к поступающим на вход векторам, используются смещения, которые позволяют нейрону стать конкурентным с нейронами-победителями. Этому способствует положительное смещение, которое добавляется к отрицательному расстоянию удаленного нейрона.
Соответствующее правило настройки, учитывающее нечувствительность мертвых нейронов, реализовано в виде М-функции learncon и заключается в следующем - в начале процедуры настройки всем нейронам конкурирующего слоя присваивается одинаковый параметр активности:
 , (3.3)
, (3.3)
где  - количество нейронов конкурирующего слоя, равное числу кластеров. В процессе настройки М-функция learncon корректирует этот параметр таким образом, чтобы его значения для активных нейронов становились больше, а для неактивных нейронов меньше. Соответствующая формула для вектора приращений параметров активности выглядит следующим образом:
- количество нейронов конкурирующего слоя, равное числу кластеров. В процессе настройки М-функция learncon корректирует этот параметр таким образом, чтобы его значения для активных нейронов становились больше, а для неактивных нейронов меньше. Соответствующая формула для вектора приращений параметров активности выглядит следующим образом:
 , (3.4)
, (3.4)
где  - параметр скорости настройки;
- параметр скорости настройки;  -вектор, элемент
-вектор, элемент  которого равен 1, а остальные - 0.
которого равен 1, а остальные - 0.
Нетрудно убедиться, что для всех нейронов, кроме нейрона-победителя, приращения отрицательны. Поскольку параметры активности связаны со смещениями соотношением (в обозначениях системы MATLAB):
 , (3.5)
, (3.5)
то из этого следует, что смещение для нейрона-победителя уменьшится, а смещения для остальных нейронов немного увеличатся.
М-функция learnсon использует следующую формулу для расчета приращений вектора смещений:
 . (3.6)
. (3.6)
Параметр скорости настройки по умолчанию равен 0.001, и его величина обычно на порядок меньше соответствующего значения для М-функции learnk. Увеличение смещений для неактивных нейронов позволяет расширить диапазон покрытия входных значений, и неактивный нейрон начинает формировать кластер. В конечном счете он может начать притягивать новые входные векторы - это дает два преимущества. Первое преимущество, если нейрон не выигрывает конкуренции, потому что его вектор весов существенно отличается от векторов, поступающих на вход сети, то его смещение по мере обучения становится достаточно большим и он становится конкурентоспособным. Когда это происходит, его вектор весов начинает приближаться к некоторой группе векторов входа. Как только нейрон начинает побеждать, его смещение начинает уменьшаться. Таким образом, задача активизации "мертвых" нейронов оказывается решенной. Второе преимущество, связанное с настройкой смещений, состоит в том, что они позволяют выровнять значения параметра активности и обеспечить притяжение приблизительно одинакового количества векторов входа. Таким образом, если один из кластеров притягивает большее число векторов входа, чем другой, то более заполненная область притянет дополнительное количество нейронов и будет поделена на меньшие по размерам кластеры.
3.1.5 Обучение сети
Реализуем 10 циклов обучения. Для этого можно использовать функции train или adapt:
net.trainParam.epochs = 10
net = train(net,p)
net.adaptParam.passes = 10
[net,y,e] = adapt(net,mat2cell(p)).
Заметим, что для сетей с конкурирующим слоем по умолчанию используется обучающая функция trainwbl, которая на каждом цикле обучения случайно выбирает входной вектор и предъявляет его сети; после этого производится коррекция весов и смещений.
Выполним моделирование сети после обучения:
а = sim(net,p)
ас = vec2ind(a)
ас = 2 1 2 1.
Видим, что сеть обучена классификации векторов входа на 2 кластера: первый расположен в окрестности вектора (0,0), второй - в окрестности вектора (1,1). Результирующие веса и смещения равны:
wtsl = net.IW{l,l}
b1 = net.b{l}
wts1 =
0.58383 0.58307
0.41712 0.42789
b1=
5.4152
5.4581.
Заметим, что первая строка весовой матрицы действительно близка к вектору (1,1), в то время как вторая строка близка к началу координат. Таким образом, сформированная сеть обучена классификации входов. В процессе обучения каждый нейрон в слое, весовой вектор которого близок к группе векторов входа, становится определяющим для этой группы векторов. В конечном счете, если имеется достаточное число нейронов, каждая группа векторов входа будет иметь нейрон, который выводит 1, когда представлен вектор этой группы, и 0 в противном случае, или, иными словами, формируется кластер. Таким образом, слой Кохонена действительно решает задачу кластеризации векторов входа.
3.1.6 Моделирование кластеризации данных
Функционирование слоя Кохонена можно пояснить более наглядно, используя графику системы MATLAB. Рассмотрим 48 случайных векторов на плоскости, формирующих 8 кластеров, группирующихся около своих центров. На графике, приведенном на рисунке 3.3, показано 48 двухэлементных векторов входа.
Сформируем координаты случайных точек и построим план их расположения на плоскости:
с = 8
n = 6 % Число кластеров, векторов в кластере
d = 0.5 % Среднеквадратичное отклонение от центра кластера
х = [-10 10;-5 5] % Диапазон входных значений
[r,q] = size(x); minv = min(x1)1; maxv = mах(х1)1
v = rand(r, e).С{maxv - minv) *ones(l,c) + xninv*ones (l,c))t = c*n % Число точек
v= [v v v v v]; v=v+randn{r,t)*d % Координаты точек
Р = v
plot(P(l,:), P(2,:),'+k') % (рисунок 3.3)
title('Векторы входа'), xlabel('Р(1,:)'), ylabel('P(2,:)').
Векторы входа, показанные на рисунке 3.3, относятся к различным классам.

Рисунок 3.3 – Двухэлементные векторы входа
Применим конкурирующую сеть из восьми нейронов для того, чтобы распределить их по классам:
net = newc([-2 12;-1 6], 8,0.1)
w0 =net.IW{l}
b0 = net.b{l}
c0 = exp(l)./b0.
Начальные значения весов, смещений и параметров активности нейронов представлены ниже:
w0 =b0 =с0 =
0.50.2521.7460.125
0.50.2521,7460.125
0.50.2521.7460.125
0-50.2521.7460.125
0.50.2521.7460.125
0.50.2521.7460.125
0.50.2521.7460.125
0.50.2521.7460.125.
После обучения в течение 500 циклов получим:
net.trainParam.epochs = 500
net = train(net,P)
w = net.IW{l} bn = net.b{l}
cn = exp(1)./bn
wn=bn=cn=
6.2184 2.423922.1370,123
1.3277 0.9470121.7180.125
0.31139 0.4093521.1920.128
3.543 4.584521.4720.127
3.4617 2.8S9621.9570.124
4 3171 1.427821.1850.128
6.7065 0.4369623.0060.118
0.97S17 0.1724221.420.127.
Как следует из приведенных таблиц, центры кластеризации распределились по восьми областям, показанным на рисунке 3.4, а; смещения отклонились в обе стороны от исходного значения 21.746 также, как и параметры активности нейронов, показанные на рисунке 3.4, б.
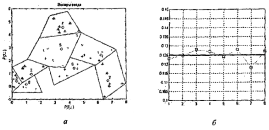
Рисунок 3.4 – Полученные центры кластеризации
Рассмотренная самонастраивающаяся сеть Кохонена является типичным примером сети, которая реализует процедуру обучения без учителя.
3.2 Карта Кохонена в MATLAB NNT
Самоорганизующаяся сеть в виде карты Кохонена предназначена для решения задач кластеризации входных векторов. В отличие от слоя Коконена карта Кохонена поддерживает такое топологическое свойство, когда близким кластерам входных векторов соответствуют близко расположенные нейроны.
Первоначальная топология размещения нейронов в слое Кохонена задается М-функциями gridtop, hextop или randtop, что соответствует размещению нейронов в узлах либо прямоугольной, либо гексагональной сетки, либо в узлах сетки со случайной топологией. Расстояния между нейронами вычисляются с помощью специальных функций вычисления расстояний dist, boxdist, linkdist и mandist.
Карта Кохонена для определения нейрона-победителя использует ту же процедуру, какая применяется и в слое Кохонена. Однако на карте Кохонена одновременно изменяются весовые коэффициенты соседних нейронов в соответствии со следующим соотношением:
 . (3.7)
. (3.7)
В этом случае окрестность нейрона-победителя включает все нейроны, которые находятся в пределах некоторого радиуса  :
:
 . (3.8)
. (3.8)
Чтобы пояснить понятие окрестности нейрона, обратимся к рисунку 3.5.

Рисунок 3.5 – Окрестности нейрона
Левая часть рисунка соответствует окрестности радиуса 1 для нейрона-победителя с номером 13; правая часть - окрестности радиуса 2 для того же нейрона. Описания этих окрестностей выглядят следующим образом:

Заметим, что топология карты расположения нейронов не обязательно должна быть двумерной. Это могут быть и одномерные и трехмерные карты, и даже карты больших размерностей. В случае одномерной карты Кохонена, когда нейроны расположены вдоль линии, каждый нейрон будет иметь только двух соседей в пределах радиуса 1 или единственного соседа, если нейрон расположен на конце линии. Расстояния между нейронами можно определять различными способами, используя прямоугольные или гексагональные сетки, однако это никак не влияет на характеристики сети, связанные с классификацией входных векторов.
3.2.1 Топология карты
Как уже отмечалось выше, можно задать различные топологии для карты расположения нейронов, используя М-функции gridtop, hextop, randtop.
Рассмотрим простейшую прямоугольную сетку размера 2x3 для размещения шести нейронов, которая может быть сформирована с помощью функции gridtop:
pos = gridtop(2,3)
pos =
0 1 0 1 0 1
0 0 1 1 2 2
plotsom(pos) % (рисунок 3.6).
Соответствующая сетка показана на рисунке 3.6. Метки position(1, i) и position(2,i) вдоль координатных осей генерируются функцией plotsom и задают позиции расположения нейронов по первой, второй и т. д. размерностям карты.

Рисунок 3.6 – Прямоугольная сетка
Здесь нейрон 1 расположен в точке с координатами (0,0), нейрон 2 - в точке (1,0), нейрон 3 - в точке (0,1) и т. д. Заметим, что, если применить команду gridtop, переставив аргументы местами, получим иное размещение нейронов;
pos=gridtop(3,2)pos =
0 1 2 0 1 2
0 0 0 1 1 1.
Гексагональную сетку можно сформировать с помощью функции hextop:
pos = hextop(2,3)
pos =
0 1.0000 0.5000 1.5000 0 1.0000
0 0 0.8660 0.8660 1.7321 1.7321.
plotsom (pos) % (рисунок 3.7).

Рисунок 3.7 – Гексагональная сетка
Заметим, что М-функция hextop используется по умолчанию при создании карт Кохонена при применении функции newsom.
Сетка со случайным расположением узлов может быть создана с помощью функции randtop:
pos = randtop(2,3)
pos =
0.061787 0.64701 0.40855 0.94383 0 0.65113
0 0.12233 0.90438 0.54745 1.4015 1.5682
plotsom(pos) % (рисунок 3.8).
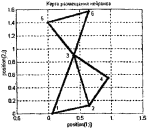
Рисунок 3.8 – Сетка со случайным расположением узлов
3.2.2 Функции для расчета расстояний
В ППП NNT используется 4 функции для расчета расстояний между узлами сетки.
Функция dist вычисляет евклидово расстояние между нейронами, размещенными в узлах сетки, в соответствии с формулой:
 , (3.9)
, (3.9)
где  ,
,  - векторы положения нейронов с номерами i и j.
- векторы положения нейронов с номерами i и j.
Обратимся к прямоугольной сетке из шести нейронов (рисунок 3.6) и вычислим соответствующий массив расстояний:
pos = gridtop(2,3)
d = disе(pos)
d =
0 1 1 1.4142 2 2.2361
1 0 1.4142 1 2.2361 2
1 1.4142 0 1 1 1.4142
1.4142 1 1 0 1.4142 1
2 2.2361 1 1.4142 0 1
2.2361 2 1.4142 1 1 0.
Этот массив размера 6х6 описывает расстояния между нейронами и содержит на диагонали нули, поскольку они определяют расстояние нейрона до самого себя, а затем, двигаясь вдоль строки, до второго, третьего и т. д.
На рисунке 3.9 показано расположение нейронов в узлах прямоугольной сетки. Введем понятие окрестности для прямоугольной сетки. В этом случае окрестность размера 1, или просто окрестность 1, включает базовый нейрон и его непосредственных соседей; окрестность 2 включает нейроны из окрестности 1 и их соседей.

Рисунок 3.9 – Расположение нейронов в узлах прямоугольной сетки
Размер, а соответственно и номер окрестности, определяется максимальным значением координаты смещения нейрона от базового. Вводимое таким способом расстояние между нейронами называется расстоянием максимального координатного смещения и может быть вычислено по формуле:
 , (3.10)
, (3.10)
где  , - векторы положения нейронов с номерами i и j.
, - векторы положения нейронов с номерами i и j.
Для вычисления этого расстояния в ППП NNT предназначена М-функция boxdist. Для конфигурации нейронов, показанной на рисунке 3.6, эти расстояния равны:
роs = gridtop(2,3)
d = boxdist(pos)
d=
0 1 1 1 2 2
1 0 1 1 2 2
1 1 0 1 1 1
1 1 1 0 1 1
2 2 1 1 0 1
2 2 1 1 1 0.
Расстояние максимального координатного смещения между базовым нейроном 1 и нейронами 2, 3 и 4 равно 1, поскольку они находятся в окрестности 1, а расстояние между базовым нейроном и нейронами 5 и 6 равно 2, и они находятся в окрестности 2. Расстояние максимального координатного смещения от нейронов 3 и 4 до всех других нейронов равно 1.
Определим другое расстояние между нейронами, которое учитывает то количество связей, которое необходимо установить, чтобы задать путь движения от базового нейрона. Если задано  нейронов, положение которых определяется векторами
нейронов, положение которых определяется векторами  , i = 1,..., S, то расстояние связи между ними определяется соотношением:
, i = 1,..., S, то расстояние связи между ними определяется соотношением:
 (3.11)
(3.11)
Если евклидово расстояние между нейронами меньше или равно 1, то расстояние связи принимается равным 1; если между нейронами с номерами i и j имеется единственный промежуточный нейрон с номером  , то расстояние связи равно 2, и т. д.
, то расстояние связи равно 2, и т. д.
Для вычисления расстояния связи в ППП NNT предназначена функции linkdist. Для конфигурации нейронов, доказанной на рисунке 3.6, эти расстояния равны:
pos = gridtop{2,3)
d = linkdist(pos)
d =
0 1 1 2 2 3
1 0 2 1 3 2
1 2 0 1 1 2
2 1 1 0 2 1
2 3 1 2 0 1
3 2 2 1 1 0.
Расстояние связи между базовым нейроном 1 и нейронами 2, 3 равно 1, между базовым нейроном и нейронами 4 и 5 равно 2, между базовым нейроном и нейроном 6 равно 3. Наконец, определим расстояние максимального координатного смещении по формуле:
 , (3.12)
, (3.12)
где ,  - векторы расположения нейронов с номерами i и j.
- векторы расположения нейронов с номерами i и j.
Для вычисления расстояния максимального координатного смещения в ППП NNT предназначена функции mandist.
Вновь обратимся к конфигурации нейронов на рисунке 3.6:
pos = gridtop(2,3)
d = mandist(pos)
d =
0 1 1 2 2 3
1 0 2 1 3 2
1 2 0 1 1 2
2 1 1 0 2 1
2 3 1 2 0 1
3 2 2 1 1 0.
В случае прямоугольной сетки оно совпадает с расстоянием связи.
3.2.3 Архитектура сети
Промоделированная архитектура самоорганизующейся карты Кохонена в MATLAB NNT показана на рисунке 3.10.

Рисунок 3.10 – Архитектура самоорганизующейся карты Кохонена
Эта архитектура аналогична структуре слоя Кохонена за исключением того, что здесь не используются смещения. Конкурирующая функция активации возвращает 1 для элемента выхода  , соответствующего победившему нейрону; все другие элементы вектора равны 0.
, соответствующего победившему нейрону; все другие элементы вектора равны 0.
Однако в сети Кохонена выполняется перераспределение нейронов, соседствующих с победившим нейроном. При этом можно выбирать различные топологии размещения нейронов и различные меры для вычисления расстояний между нейронами.
3.2.4 Создание сети
Для создания самоорганизующейся карты Кохонена в составе ППП MATLAB NNT предусмотрена М-функция newsom. Допустим, что требуется создать сеть для обработки двухэлементных векторов входа с диапазоном изменения элементов от 0 до 2 и от 0 до 1 соответственно. Предполагается использовать гексагональную сетку размера 2x3. Тогда для формирования такой нейронной сети достаточно воспользоваться оператором:
net = newsom([0 2; 0 1], [2 3])
net.layers{l}
ans =
dimensions:[2 3]
distanceFcn:'linkdist'
distances:[6x6 double]
initFcn:'initwb'
netInputFcn:'netsum'
positions:[2x6 double]
size:6
topologyFcn:'hextop'
transferFcn:'compet'
userdata:[1x1 struct].
Из анализа характеристик этой сети следует, что она использует по умолчанию гексагональную топологию hextop и функцию расстояния linkdist.
Для обучения сети зададим следующие 12 двухэлементных векторов входа:
Р = [0.1 0.3 1.2 1.1 1.8 1.7 0.1 0.3 1.2 1.1 1.8 1.7;...
0.2 0.1 0.3 0.1 0.3 0.2 1.8 1.8 1.9 1.9 1.7 1.8].
Построим на топографической карте начальное расположение нейронов карты Кохонена и вершины векторов входа (рисунок 3.11):
plotsom(net.iw{1,1}, net.layers{1}.distances)
hold on
plot(P(1,;),P(2,:), '*к','markersize',10)
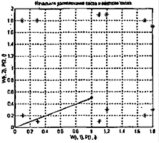
Рисунок 3.11 – Начальное расположение нейронов
Векторы входа помечены символом * и расположены по периметру рисунка, а начальное расположение нейронов соответствует точке с координатами (1, 0.5).
3.2.5 Обучение сети
Обучение самоорганизующейся карты Кохонена реализуется повекторно независимо от того, выполняется обучение сети с помощью функции trainwbl или адаптация с помощью функции adaptwb. В любом случае функция learnsom выполняет настройку элементов весовых векторов нейронов.
Прежде всего определяется нейрон-победитель и корректируются его вектор весов и векторы весов соседних нейронов согласно соотношению:
 , (3.13)
, (3.13)
где 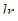 - параметр скорости обучения;
- параметр скорости обучения;  - массив параметров соседства для нейронов, расположенных в окрестности нейрона-победителя i, который вычисляется по соотношению:
- массив параметров соседства для нейронов, расположенных в окрестности нейрона-победителя i, который вычисляется по соотношению:
 (3.14)
(3.14)
где  - элемент выхода нейронной сети;
- элемент выхода нейронной сети;  - расстояние между нейронами i и j;
- расстояние между нейронами i и j;  - размер окрестности нейрона-победителя.
- размер окрестности нейрона-победителя.
Весовые векторы нейрона-победителя и соседних нейронов изменяются в зависимости от значения параметра соседства. Веса нейрона-победителя изменяются пропорционально параметру скорости обучения, а веса соседних нейронов - пропорционально половинному значению этого параметра.
Процесс обучения карты Кохонена включает 2 этапа: этап упорядочения векторов весовых коэффициентов в пространстве признаков и этап подстройки. При этом используются следующие параметры обучения сети (таблица 2.1):
Таблица 2.1
Параметры обучения сети
| Параметры обучения и настройки карты Кохонена | Значение по умолчанию | ||
| Количество циклов обучения | neе.trainParamepochs | N | >1000 |
| Количество циклов на этапе упорядочения | netinputWeights{1,1}.learnParam.order_steps | S | 1000 |
| Параметр скорости обучения на этапе упорядочения | net.inputWeights{1,1}.leamParam.order_lr | order_lr | 0.9 |
| Параметр скорости обучения на этапе подстройки | net.inputWeights{1,1}.learnParam.tune_lr | tune | 0.02 |
| Размер окрестности на этапе подстройки | net.inputWeights(1,1).learnParam.tune_nd | tune_nd | 1 |
В процессе построения карты Кохонена изменяются 2 параметра: размер окрестности и параметр скорости обучения.
Этап упорядочения. На этом этапе используется фиксированное количество шагов. Начальный размер окрестности назначается равным максимальному расстоянию между нейронами для выбранной топологии и затем уменьшается до величины, используемой на этапе подстройки в соответствии со следующим правилом:
 , (3.15)
, (3.15)
где  - максимальное расстояние между нейронами;
- максимальное расстояние между нейронами;  - номер текущего шага.
- номер текущего шага.
Параметр скорости обучения изменяется по правилу:
 . (3.16)
. (3.16)
Таким образом, он уменьшается от значения order_lr до значения tune_lr.
Этап подстройки. Этот этап продолжается в течение оставшейся части процедуры обучения. Размер окрестности на этом этапе остается постоянным и равным:
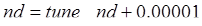 . (3.17)
. (3.17)
Параметр скорости обучения изменяется по следующему правилу:
 . (3.18)
. (3.18)
Параметр скорости обучения продолжает уменьшаться, но очень медленно, и именно поэтому этот этап именуется подстройкой. Малое значение окрестности и медленное уменьшение параметра скорости обучения хорошо настраивают сеть при сохранении размещения, найденного на предыдущем этапе. Число шагов на этапе подстройки должно значительно превышать число шагов на этапе размещения. На этом этапе происходит тонкая настройка весов нейронов по отношению к набору векторов входа.
Как и в случае слоя Кохонена, нейроны карты Кохонена будут упорядочиваться так, чтобы при равномерной плотности векторов входа нейроны карты Кохонена также были распределены равномерно. Если векторы входа распределены неравномерно, то и нейроны на карте Кохонена будут иметь тенденцию распределяться в соответствии с плотностью размещения векторов входа.
Таким образом, при обучении карты Кохонена решается не только задача кластеризации входных векторов, но и выполняется частичная классификация.
Выполним обучение карты Кохонена размера 2x3 с гексагональной сеткой и с мерой, определяемой расстоянием связи:
net = newsom([0 2; 0 1], [2 3]).
Для обучения сети зададим 12 двухэлементных векторов входа
Р = [0.1 0.3 1.2 1.1 1.8 1.7 0.1 0.3 1.2 1.1 1.8 1.7;...
0.2 0.1 0.3 0.1 0.3 0,2 1,8 1.8 1.9 1.9 1.7 1.8].
Зададим количество циклов обучения равным 2000:
net.trainParam.epochs = 2000
net.trainParam.show = 100
net = train (net, P)
plot(p(l,:),P(2,:), '*', 'markersize',10)
hold on
plotsom(net.iw{1*1},net.layers{l).distances).
Результат обучения представлен на рисунке 3.12.

Рисунок 3.12 – Карты Кохонена с гексагональной сеткой
Положение нейронов и их нумерация определяются массивом весовых векторов, который для данного примера имеет вид:
net.IW{l}
ans =
1.2163 0.20902
0.73242 0.46577
1.0645 0.99103
0.4551 1.3893
1.5359 1.8079
1.0888 1.8433.
Если промоделировать карту Кохонена на массиве обучающих векторов входа, то будет получен следующий выход сети:
а = sim(net,P)
а =
(2,1)1
(2,2)1
(1,3) 1
(1,4) 1
(1,5) 1
(1,6) 1
(4,7) 1
(4,8) 1
(6,9) 1(6.10) 1
(5.11) 1
(5.12) 1.
Это означает, что векторы входов 1 и 2 отнесены к кластеру с номером 2, векторы 3-6 - к кластеру 1, векторы 7-8 - к кластеру 4, векторы 9-10 - к кластеру 6, а векторы 11-12 - к кластеру 5. Номер кластера на рисунке соответствует номеру соответствующего нейрона на карте Кохонена.
Если сформировать произвольный вектор входа, то карта Кохонена должна указать его принадлежность к тому или иному кластеру:
а = sim(net,[1.5; 1])
а = (3,1) 1.
В данном случае представленный вектор входа отнесен к кластеру с номером 3. Обратите внимание, что векторов такого сорта в обучающей последовательности не было. Рассмотрим еще 2 модели одномерной и двумерной карт Кохонена.
3.2.6 Моделирование одномерной карты Кохонена
Рассмотрим 100 двухэлементных входных векторов единичной длины, распределенных равномерно в пределах от 0 до 90°:
angles = 0:0.5*pi/99:0.5*pi
Р = [sin(angles);cos(angles)]
plot(P(1,1:10:end), P(2,l:10:end), 'b')
hold on.
График входных векторов приведен на рисунке 3.13, а, и на нем символом * отмечено положение каждого 10-го вектора.

Рисунок 3.13 – График входных векторов
Сформируем самоорганизующуюся карту Кохонена в виде одномерного слоя из 10 нейронов и выполним обучение в течение 2000 циклов:
net = newsom([0 1;0 1], [10])
net.trainParam.epochs = 2000; net.trainParam.show = 100
[net, tr] = train(net,P)
plotsom (net.IW{1,1}, net.layers{1}.distances) % (рисунок 3.13,a)
figure (2) a = sim(net,P); bar(sum(a1)) % (рисунок 3.13,б).
Весовые коэффициенты нейронов, определяющих центры кластеров, отмечены на рисунке 3.13, а цифрами. На рисунке 3.13, б показано распределение обучающих векторов по кластерам. Как и ожидалось, они распределены практически равномерно с разбросом от 8 до 12 векторов в кластере.
Таким образом, сеть подготовлена к кластеризации входных векторов. Определим, к какому кластеру будет отнесен вектор [1; 0]:
а = sim(net,[1;0])
а = (10,1)1.
Как и следовало ожидать, он отнесен к кластеру с номером 10.
3.2.7 Моделирование двумерной карты Кохонена
Этот пример демонстрирует обучение двумерной карты Кохонена. Сначала создадим обучающий набор случайных двумерных векторов, элементы которых распределены по равномерному закону в интервале [-1, 1]:
P = rands(2,1000)
plot(P(l,:),Р(2,:),'+') % (рисунок 3.14).

Рисунок 3.14 – Обучающий набор случайных двумерных векторов
Для кластеризации векторов входа создадим самоорганизующуюся карту Кохонена размера 5x6 с 30 нейронами, размещенными на гексагональной сетке:
net = newsom([-1 1; -1 1],[5,6])
net.trainParam.epochs = 1000
net.trainParam.show = 100
net = train(net,P); plotsom(net.IW{1,1},net.layers{l}.distances).
Результирующая карта после этапа размещения показана на рисунке 3.15, а. Продолжим обучение и зафиксируем карту после 1000 шагов этапа подстройки (рисунок 3.15, б), а затем после 4000 шагов (рисунок 3.15, в). Нетрудно убедиться, что нейроны карты весьма равномерно покрывают область векторов входа.

Рисунок 3.15 – Результирующая карта после этапа размещения
Определим принадлежность нового вектора к одному из кластеров карты Кохонена и построим соответствующую вершину вектора на рисунке 3.15, в:
а = sim(net,[0.5;0.3])
а = (19.1) 1
hold on, plot(0.5,0.3,'*k') %(риcунок 3.15, в).
Нетрудно убедиться, что вектор отнесен к 19-му кластеру.
Промоделируем обученную карту Кохонена, используя массив векторов входа:
а = sim(net,P)
bar(sum(a')) % (рисунок 3.16).
Из анализа рисунка 3.16 следует, что количество векторов входной последовательности отнесенных к определенному кластеру, колеблется от 13 до 50.

Рисунок 3.16 – Промоделированная карта Кохонена
Таким образом, в процессе обучения двумерная самоорганизующаяся карта Кохонена выполнила кластеризацию массива векторов входа. Следует отметить, что на этапе размещения было выполнено лишь 20% от общего числа шагов обучения, т, е. 80% общего времени обучения связано с тонкой подстройкой весовых векторов. Фактически на этом этапе выполняется в определенной степени классификация входных векторов.
Слой нейронов карты Кохонена можно представлять, в виде гибкой сетки, которая натянута на пространство входных векторов. В процессе обучения карты, в отличие от обучения слоя Кохонена, участвуют соседи нейрона-победителя, и, таким образом, топологическая карта выглядит более упорядоченной, чем области кластеризации слоя Кохонена.
ВЫВОДЫ
Современный мир переполнен различными данными и информацией - прогнозами погод, процентами продаж, финансовыми показателями и массой других. Часто возникают задачи анализа данных, которые с трудом можно представить в математической числовой форме. Например, когда нужно извлечь данные, принципы отбора которых заданы неопределенно: выделить надежных партнеров, определить перспективный товар, проверить кредитоспособность клиентов или надежность банков и т.п. И для того, чтобы получить максимально точные результаты решения этих задач необходимо использовать различные методы анализа данных.
Одним из ведущих методов анализа данных является кластеризация. Задачей кластеризации является разбиения совокупности объектов на однородные группы (кластеры или классы), а целью - поиск существующих структур. Решается данная задача при помощи различных методов, выбор метода должен базироваться на исследовании исходного набора данных. Сложностью кластеризации является необходимость ее экспертной оценки.
На данный момент существует большое количество методов кластеризации. Так, например, наиболее очевидным является применение методов математической статистики. Но тут возникает проблема с количеством данных, ибо статистические методы хорошо работают при большом объеме априорных данных, а у нас может быть ограниченное их количество. Поэтому статистические методы не могут гарантировать успешный результат, что делает их малоэффективными в решении многих практических задач.
Другим путем решения этой задачи может быть применение нейронных сетей, что является наиболее перспективным подходом. Можно выделить ряд преимуществ использования нейронных сетей:
· возможно построение удовлетворительной модели на нейронных сетях даже в условиях неполноты данных;
· искусственные нейронные сети легко работают в распределенных системах с большой параллелизацией в силу своей природы;
· поскольку искусственные нейронные сети подстраивают свои весовые коэффициенты, основываясь на исходных данных, это помогает сделать выбор значимых характеристик менее субъективным.
Кластеризация является задачей, относящейся к стратегии "обучение без учителя", т.е. не требует наличия значения целевых переменных в обучающей выборке. Для нейросетевой кластеризации данных могут использоваться различные модели сетей, но наиболее эффективным является использование сетей Кохонена или самоорганизующихся карт.
В данной магистерской работе подробно на примерах рассмотрена такая парадигма нейронных сетей как карты Кохонена. Основное отличие этих сетей от других моделей состоит в наглядности и удобстве использования. Эти сети позволяют упростить многомерную структуру, их можно считать одним из методов проецирования многомерного пространства в пространство с более низкой размерностью. Интенсивность цвета в определенной точке карты определяется данными, которые туда попали: ячейки с минимальными значениями изображаются темно-синим цветом, ячейки с максимальными значениями - красным.
Другое принципиальное отличие карт Кохонена от других моделей нейронных сетей - иной подход к обучению, а именно - неуправляемое или неконтролируемое обучение. Этот тип обучения позволяет данным обучающей выборки содержать значения только входных переменных. Сеть Кохонена учится понимать саму структуру данных и решает задачу кластеризации.
ПЕРЕЧЕНЬ ССЫЛОК
1. Руденко О.Г., Бодянский Е.В. Искусственные нейронные сети – Харьков, 2005. – 407с.
2. Котов А., Красильников Н. Кластеризация данных
3. Jain A.K., Murty M.N., Flynn P.J. Data Clustering: A Review "(http://www/csee/umbc/edu/nicolas/clustering/p264-jain.pdf)
4. Kogan J., Nicholas C., Teboulle M. Clustering Large and High Dimensional Data (http://www/csee/umbc/edu/nicolas/clustering/tutorial.pdf)
5. Медведев В.С., Потемкин В.Г. Нейронные сети. MATLAB 6 – М.: ДИАЛОГ-МИФИ, 2002. – 496с.
6. Круглов В. В., Борисов В. В. Искусственные нейронные сети. Теория и практика – М.: Горячая линия - Телеком, 2001. – 382с.
7. Каллан Р. Основные концепции нейронных сетей – «Вильямс», 2001. –288с.








