 2020-01-14
2020-01-14 1164
1164
Существует много различных систем и единиц измерения данных. Каждая научная дисциплина и каждая область человеческой деятельности может, использовав свои, наиболее удобные или традиционно устоявшиеся единицы. В информатике для измерения данных используют тот факт, что разные типы данных имеют двоичное представление и потому вводят свои единицы данных, основанные на нем.
Наименьшей единицей измерения является байт. Поскольку одним байтом, правило, кодируется один символ текстовой информации, то для текстовых документов размер в байтах соответствует лексическому объему в символах.
Более крупная единица измерения – килобайт (Кбайт). Условно можно считать, что 1 Кбайт примерно равен 1000 байт. Условность связана с тем, что для вычислите ной техники, работающей с двоичными числами, более удобно представление чисел в виде степени двойки и потому на самом деле 1 Кбайт равен 210 байт (1024 байт). Однако всюду, где это не принципиально не включают 24 байта. В килобайтах измеряют сравнительно небольшие объемы данных. Условно можно считать, что одна страница неформатированного машинописного текста составляет около 2 Кбайт.
Более крупные единицы измерения данных образуются добавлением префиксов мега -, гига -, тера – в более крупных единицах пока нет практической надобности.
1 байт = 8 (23) бит
1 Кбайт =1024 байт =210 байт
1 Мбайт = 1024 Кбайт = 220 байт
1 Гбайт = 1024 Мбайт = 230 байт
1 Тбайт = 1024 Гбайт = 240байт
При переходе к более крупным единицам «инженерная» погрешность, связанная с округлением, накапливается и становится недопустимой, поэтому на старших единицах измерения округление производится реже.
При хранении данных решаются две проблемы: как сохранить данные в наиболее компактном виде и как обеспечить к ним удобный и быстрый доступ. Для обеспечения доступа необходимо, чтобы данные имели упорядоченную структуру, а при этом образуется высокая нагрузка в виде адресных данных. Без них нельзя получить доступ к нужным элементам данных, входящих в структуру.
Поскольку адресные данные тоже имеют размер и тоже подлежат хранению, хранить данные в виде мелких единиц, таких как байты, неудобно. Их неудобно хранить и в более крупных единицах (килобайтах, мегабайтах и тому подобному), поскольку неполное заполнение одной единицы хранения приводит к неэффективности хранения. В качестве единицы хранения данных принят объект переменной длины, называемый файлом. Файл – это последовательность произвольного числа байтов, обладающая уникальным собственным именем. Обычно в отдельном файле хранят данные, относящиеся к одному типу. В этом случае тип данных определяет тип файла.
Поскольку в определении файла нет ограничений на размер, можно представить себе файл, имеющий 0 байтов (пустой файл),и файл, имеющий любое число байтов. Имя файла фактически несет в себе адресные данные, без которых данные, хранящиеся в файле, не станут информацией из-за отсутствия метода доступа к ним. Кроме функций, связанных с адресацией, имя файла может хранить и сведения о типе данных, заключенных в нем. Для автоматических средств работы с данными это важно, поскольку по имени файла они могут автоматически определить адекватный метод извлечения информации из файла.
Практическая часть
Вариант 16
В течение текущего дня в салоне сотовой связи проданы мобильные телефоны, код, модель и цена которых указаны в таблице на рис. 16.1. В таблице на рис. 16.2 указан код и количество проданных телефонов различных моделей.
1. В итоговой таблице (рис. 16.3) обеспечит автоматическое заполнение данными столбцов «Модель мобильного телефона», «Цена, руб.», «Продано, шт.», используя исходные данные таблиц на рис. 16.1 и 16.2, а также функции ЕСЛИ(), ПРОСМОТР. Рассчитать сумму, полученную от продаж каждой моделей, итоговую сумму продаж.
2. Сформировать ведомость продаж мобильных телефонов на текущую дату.
3. Представить графически данные о продаже мобильных телефонов за текущий день.
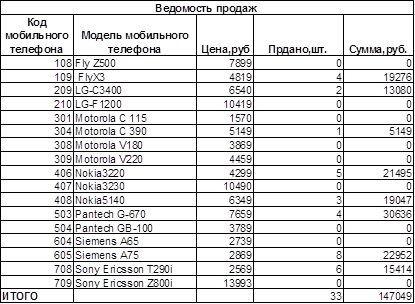
Рис. 16.3. Табличные данные ведомости продаж
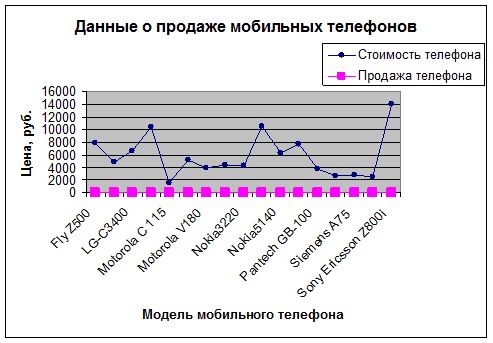
Диаграмма 1. Данные о продаже мобильных телефонов за текущий день
Заключение
В современном мире компьютер считают универсальным преобразователем информации. Тексты на естественных языках и числа, математические и специальные символы – одним словом все, что в быту или в профессиональной деятельности может быть необходимо человеку, должно иметь возможность быть введенным в компьютер.
В силу безусловного приоритета двоичной системы счисления при внутреннем представлении информации в компьютере кодирование «внешних» символов основывается на сопоставлении каждому из них определенной группы двоичных знаков. При этом из технических соображений и из соображений удобства кодирования-декодирования следует пользоваться двоичными группами равной длины.
Проанализировав информационные структуры и технологии, можно сделать вывод о том, что данные – это отдельные факты, характеризующие объекты, процессы и явления в предметной области, а также их свойства.
При обработке на ЭВМ данные трансформируются, условно проходя следующие этапы:
• данные как результат измерений и наблюдений;
• данные на материальных носителях информации (таблицы, протоколы, справочники);
• модели (структуры) данных в виде диаграмм, графиков, функций;
• данные в компьютере на языке описания данных;
• базы данных на машинных носителях.
Для хранения данных используются базы данных, для них характерны большой объем и относительно небольшая удельная стоимость информации.
Процесс кодирования любого вида информации фактически представляет собой его преобразование тем или иным способом в числовую форму.
В памяти машины не существует принципиального различия между закодированной информацией различных типов. Над всеми видами данных, включая дополнительно и саму программу, процессор способен производить арифметические, логические и прочие операции, которые содержатся в системе его команд.
Список литературы
1. «Информатика» под ред. Профессора Н.В. Макаровой. Москва, «Финансы и статистика», 2001 г.
2. «Информатик» Базовый курс под ред. С.В. Симоновича. «Питер», 2004 г.
3. Касаткин В.Н. Информация, алгоритмы, ЭВМ. М.: Просвещение, 1991, 192 с.
4. Математический энциклопедический словарь. / Гл. ред. Ю.В. Прохоров. М.: Сов. энциклопедия, 1988, 847 с.
5. Компьютерные технологии обработки информации. / Под. ред. С.В. Назарова. – М.: Финансы и статистика, 1995.
6. Леонтьев В.П. Новейшая энциклопедия персонального компьютера 2003. – М.: Олма-пресс, 2003.
7. Миньков С.Л. Информатика: учебное пособие. – Томск, 2000.
8. Фигурнов В.Э. IBM PC для пользователей. 7-е изд., прераб. И доп. – М.: ИНФА – М, 2002.
9. Пекелис В. Кибернетика от А до Я.М., 1990.
10. Дмитриев В. Прикладная теория информации. М., 1989.

