 2020-01-14
2020-01-14 168
168Предположим вначале, что нам требуется смоделировать простейшую дискретную случайную величину, принимающую два значения с равными вероятностями. Эта случайная величина моделирует выбрасывание жребия или монеты. Если мы имеем в своем распоряжении генератор псевдослучайных последовательностей, описанный в предыдущем параграфе, то задача может быть решена следующим, достаточно очевидным, способом. Поскольку псевдослучайное число, получаемое с помощью функции rand(), распределено равномерно в интервале (0,1), то одинаково вероятно, будет ли очередное полученное значение принадлежать левой половине этого интервала [0,0.5) или правой [0.5, 1]. По этой причине мы можем одно из двух значений нашей случайная величина поставить в соответствие первому из этих двух подинтервалов, а в другое – второму, и далее выдавать значения в зависимости от того к какому из этих двух подинтервалов будет принадлежать очередное выпавшее значение генератора rand(). Эта схема, очевидно, легко обобщается на дискретную случайная величина, принимающую более двух значений. За каждым значением мы должны в этом случае «закрепить» некоторый подинтервал значений функции rand() с длиной, равной вероятности этого значения моделируемой дискретной случайная величина, - причем так, чтобы интервалы, закрепленные за различными значениями случайные величины не пересекались бы между собой. Поскольку сумма вероятностей всех значений случайная величина равна 1, и таков же диапазон значений, принимаемых псевдослучайной величиной, генерируемой функцией rand(), то эти подинтервалы полностью покроют диапазон возможных значений, принимаемых случайная величина, генерируемой функцией rand().
Теперь мы должны лишь всякий раз определять, к какому из множеству выбранных указанным выше образом подинтервалов принадлежит очередное выданное функцией rand() значение, и выдавать соответствующее ему значение моделируемой дискретной случайная величина.
Формально этот метод может быть представлен в следующем виде. Пусть  – случайная величина, равномерно распределенная на отрезке [0,1] (в нашем случае – это результат очередного выполнения функции rand()) и
– случайная величина, равномерно распределенная на отрезке [0,1] (в нашем случае – это результат очередного выполнения функции rand()) и  – моделируемая дискретная случайная величина с распределением
– моделируемая дискретная случайная величина с распределением  . Тогда мы выдаем по получении очередного значения g случайной величины такое значение
. Тогда мы выдаем по получении очередного значения g случайной величины такое значение  дискретной случайной величины , для которого верно двойное неравенство
дискретной случайной величины , для которого верно двойное неравенство 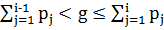 . Этим исчерпывается решение задачи моделирования дискретной случайной величины с заданным распределением. Вышеприведенный алгоритм легко реализуется программно, - например так, как в нижеприведенной функции int discrete (float p[]):
. Этим исчерпывается решение задачи моделирования дискретной случайной величины с заданным распределением. Вышеприведенный алгоритм легко реализуется программно, - например так, как в нижеприведенной функции int discrete (float p[]):
unsigned int discrete (float p[])
{
float s, r;
int k=0;
s=p[0]; r=rand();
while (s < r)
{
k++;
s=s+p[k];
}
return k;
}
Функция принимает массив вероятностей моделируемой дискретной случайной величины и выдает индекс очередного ее сгенерированного значения. Следует учесть, что поскольку индексация массивов в языке С начинается с нуля, также с нуля индексируются значения разыгрываемой случайной величины. То есть функция выдает значения в диапазоне от 0 до к-1 для дискретной случайной величины, принимающей к значений. Ниже для иллюстрации приведен ряд из 100 значений выданных программой, использующей вызов данной функции для массива вероятностей p={0.5, 0.5}:
0 1 1 1 0 0 0 1 1 1 1 1 1 0 1 0 0 1 1 0 1 1 0 0 0 0 0 1 0 1 0 0 0
1 0 1 0 0 1 0 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0
1 0 1 0 1 1 1 0 0 1 1 0 1 0 1 0 0 1 1 1 1 0 0 0 0 1 0 1 0 0 0 0 1








