 2020-04-07
2020-04-07 822
822Методы, используемые на этапе диагностики проблем, обеспечивают ее достоверное и наиболее полное описание. В их составе выделяют методы сравнения, факторного анализа, моделирования и прогнозирования. Все эти методы осуществляют сбор, хранение, обработку и анализ информации, фиксацию важнейших событий. Набор методов зависит от характера и содержания проблемы, сроков и средств, которые выделяются на этапе постановки.
Методы сравнений и факторный анализ являются широко известными и достаточно подробно излагаются в дисциплинах «Анализ хозяйственной деятельности», «Общая теория статистики» и др. Они основываются на сопоставлении фактических и нормативных (плановых, целевых) показателей и выявлении отклонений и основных причин этих отклонений.
Моделирование включает следующие модели: экономико-математические, теории массового обслуживания, теории запасов и экономического анализа.
Экономико-математическое моделирование основывается на использовании однофакторных и многофакторных моделей. Применяются однофакторные модели следующих видов: линейные модели, парабола и гипербола, многофакторные модели – линейная и логарифмическая. Наиболее часто применяются линейные модели – однофакторные:
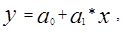 (4.1)
(4.1)
и многофакторные:
 (4.2)
(4.2)
где а0, а1, …, аn – параметры уравнений;
х, х1, …, хn – независимые переменные при принятии решений;
y – зависимая переменная, описывающая последствия принимаемых решений.
Задача состоит в определении параметров уравнения а0, а1, …, аn.
Теория массового обслуживания (теория очередей) применяется для решений, связанных с ситуациями ожидания. Она помогает принять решение, устанавливающее определенное равновесие между размерами упущенной выгоды (доходов) и величиной дополнительных затрат в сервисных организациях. Например, такие как банки, магазины, железнодорожные и авиационные кассы, поликлиники, автозаправочные станции, ремонтные фирмы, парикмахерские, телефонные станции и другие. Клиенты, не желающие стоять в очереди, представляют упущенную выгоду. Время ожидания можно сократить за счет увеличения количества операторов, обслуживающих систему, что ведет к увеличению затрат. В основе расчетов лежит известная формула Пуассона:
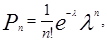 (4.3)
(4.3)
где Рn – вероятность появления n -го количества клиентов;
е – основание натурального логарифма, е=2,7183;
λ – среднее количество клиентов;
n – количество клиентов в единицу времени.
Основными характеристиками модели теории очередей являются количество каналов обслуживания, среднее время обслуживание одного клиента, количество клиентов, время ожидания обслуживания и др. На основе выполненных расчетов определяется необходимое количество каналов обслуживания при допустимом, с точки зрения клиента ожидании обслуживания.
Теория запасов была разработана в начале XX столетия, а широкое применение началось с 40-х годов. Наибольших успехов, как правило, достигали японские предприятия. Использование теории запасов позволяет установить равновесие между затратами на создание запасов и издержками, связанными с потерями в случае нарушения производственного процесса. Запасы называют «бездействующими ресурсами» (idle resource), они подвержены порче, хищениям, устареванию и прочее, кроме того, они увеличивают расходы на оборотные средства предприятия. Теория запасов позволяет определить экономически выгодный размер запаса (economic order quantity – EOQ) по формуле, разработанной Гаррисоном Ф. в 1915 году:
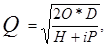 (4.4)
(4.4)
где Q – экономически выгодный размер запаса;
О – затраты на оформление заказа (order cost);
D – годовые запасы;
Н – издержки хранения (holding cost);
i – начисления к стоимости хранящихся запасов (определяется как отношение дохода, который можно было бы получить oт вложения капитала на другие цели к величине стоимости запасов);
Р – стоимость хранящихся запасов (price).
EOQ является таким количеством запаса, который позволяет свести к минимуму общие издержки, связанные с хранением запаса.
Экономический анализ оперирует такими известными понятиями, как постоянные и переменные издержки, выручка от реализации, цена за единицу продукции, минимальный объем реализации или точка безубыточности, порог рентабельности, запас финансовой прочности, сила операционного (производственного) рычага и др.
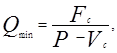 (4.5)
(4.5)
где Qmin – минимальный объем реализации (точка безубыточности);
Fc – постоянные издержки;
P – цена единицы продукции;
Vc – переменные издержки на единицу продукции.
Перечисленные понятия используются для моделирования ситуаций типа, что будет с прибылью, если изменятся объем продаж, издержки, цена и др.
Методы прогнозирования используются для предвидения изменений и последствий влияния внешней и внутренней среды на организацию и подразделяются на количественные и качественные.
К качественным методам прогнозирования относятся в основном методы предвидения спроса, такие как мнение потребителей, мнение покупателей, мнение опытных менеджеров, рыночные тесты. С помощью таких методов определяют, как изменится объем и структура продаж в зависимости от цены товара, местонахождения и уровня доходов клиентов и других факторов.
Основными методами прогнозирования являются известные методы количественных ассоциативных оценок (построение статистических прогнозов на основе временных рядов, корреляционного и регрессионного анализов и др.).
К количественным методам прогнозирования относят анализ временных рядов (АВР) и корреляционно-регрессионный анализ (КРА). AВР позволяет сделать выводы о текущем изменении показателей во времени. В прогнозных расчетах обычно используется следующая модель:

 (4.6)
(4.6)
где Y – прогнозируемый объект;
T – основной тренд (тенденция);
С – цикличность колебания вокруг тренда;
S – сезонные колебания;
R – необъясненные колебания (ошибки прогноза).
Прогнозирование на основе анализа временных рядов (АВР) использует методы экспоненциального сглаживания, экспоненциального сглаживания с учетом линейного тренда, экспоненциального сглаживания с учетом сезонной аддитивной компоненты.
Экспоненциальное сглаживание данных временного ряда основано на следующей зависимости:
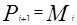
 , (4.7)
, (4.7)
где Pi+1 – прогноз:
Мi – экспоненциально сглаженное среднее в период i;
Xi – исходный временной ряд;
α – параметр сглаживания (0≤α≤1).
Экспоненциальное сглаживание с учетом линейного тренда использует следующие соотношения:
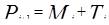 , (4.8)
, (4.8)
где 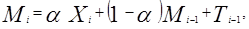

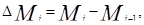
Ti – экспоненциально сглаженное значение тренда;
∆Mi – оценка величины тренда в i -ом периоде.
Экспоненциальное сглаживание с учетом сезонной аддитивной компоненты основано на расчете по следующей формуле:
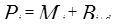 , (4.9)
, (4.9)
где 
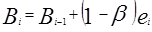 ,
,
d – сезонный лаг;
е – ошибка прогноза в текущий момент времени, которая определяется как разность, между фактом и прогнозом данных в период i;
Bi – величина сезонной компоненты.
Метод корреляционно-регрессионного анализа (КРА) построен на использовании моделей причинного прогнозирования, которые содержат ряд переменных, имеющих отношение к предсказываемой переменной.
В основе корреляционного анализа лежит расчет коэффициентов корреляции +1 ≥ r ≥. Эти коэффициенты показывают степень или силу линейной взаимосвязи.
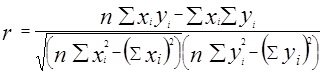 , (4.10)
, (4.10)
После определения связи между этими переменными строится статистическая модель, которая и используется для прогноза. Наиболее часто используемой количественной моделью является модель линейного регрессионного анализа:
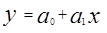 , (4.11)
, (4.11)
где y – значение независимой переменной;
а1 – коэффициент, определяющий угол наклона прямой;
а0 – отрезок, отсекаемый прямой на оси y;
Основным методом расчета зависимой переменной y является метод наименьших квадратов (МНК). Так, если анализ эмпирических данных показывает, что основная тенденция выражается прямолинейно, то можно воспользоваться уравнением прямой линии:
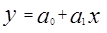 , (4.12)
, (4.12)
где y – является прогнозируемой величиной объема в зависимости от времени.
Задача состоит в определении коэффициентов a0+a1.
Для определения коэффициентов a0+a1, составляют систему нормальных уравнений:
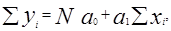
 (4.13)
(4.13)
Решив эту систему уравнений, получим значения коэзффипиентов:
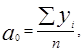

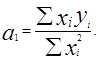 (4.14)
(4.14)
Для определения точности регрессионных оценок рассчитывают стандартную ошибку прогноза Sy,x. Ее называют стандартным отклонением уравнения регрессии:
 (4.15)
(4.15)
где Yi – значение функции в i -й точке;
Yc – расчетное значение зависимой переменной уравнения регрессии;
n – число точек данных.
Множественный регрессионный анализ использует расширенное представление линейной зависимости как функцию нескольких переменных:
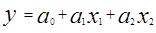 , (4.16)
, (4.16)
Для вычисления множественной регрессии чаще всего применяются компьютерные программы, реализующие формулы, которые подробно описаны в учебниках по статистике. Которые подробно изучаются в таких дисциплинах как «Теория вероятности и математическая статистика». «Общая теория статистики» и др.








