2020-04-12
2020-04-12 271
271Понятие об информации. В быту информацией называют любые данные или сведения, которые кого- либо интересуют. Например, сообщение о каких-либо событиях, о чьей-либо деятельности и т.п. "Информировать" в этом смысле означает "сообщить нечто, неизвестное раньше". Информация об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии, которые воспринимают инф. Системы (живые организмы,управляющие машины и др.) Одно и то же информационное сообщение может содержать разное количество информации для разных людей — в зависимости от их предшествующих знаний, от уровня понимания этого сообщения и интереса к нему. Свойства информации. Информация достоверна, если она отражает истинное положение дел. Недостоверная информация может привести к неправильному пониманию или принятию неправильных решений. Достоверная информация со временем может стать недостоверной, так как она обладает свойством устаревать, то есть перестаёт отражать истинное положение дел. Информация полна, если её достаточно для понимания и принятия решений. Как неполная, так и избыточная информация сдерживает принятие решений или может повлечь ошибки. Точность информации определяется степенью ее близости к реальному состоянию объекта, процесса, явления и т.п. Ценность информации зависит от того, насколько она важна для решения задачи, а также от того, насколько в дальнейшем она найдёт применение в каких-либо видах деятельности человека. Только своевременно полученная информация может принести ожидаемую пользу. Одинаково нежелательны как преждевременная подача информации (когда она ещё не может быть усвоена), так и её задержка. Если ценная и своевременная информация выражена непонятным образом, она может стать бесполезной. Информация становится понятной, если она выражена языком, на котором говорят те, кому предназначена эта информация. Информация должна преподноситься в доступной (по уровню восприятия) форме. Поэтому одни и те же вопросы по разному излагаются в школьных учебниках и научных изданиях. Информацию по одному и тому же вопросу можно изложить кратко (сжато, без несущественных деталей) или пространно (подробно, многословно). Краткость информации необходима в справочниках, энциклопедиях, учебниках, всевозможных инструкциях.
Измерение количества информации.В определенных, весьма широких условиях можно пренебречь качественными особенностями информации, выразить ее количество числом, а так же сравнить количество информации, содержащейся, в различных группах данных. В настоящее время получили распространение подходы к определению понятия "количество информации", основанные на том, что информацию, содержащуюся в сообщении, можно нестрого трактовать в смысле её новизны или, иначе, уменьшения неопределённости наших знаний об объекте. Процесс получения информации рассматривает как выбор одного сообщения из конечного наперёд заданного множества из N равновероятных сообщений, а количество информации I, содержащееся в выбранном сообщении, определяет как двоичный логарифм N. Равноценные сообщения: Формула Хартли: I = log2N. N=2 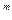 , где N- количество независимых кодируемых знаний, m – разрядность двоичного кодирования, принятого в данной системе. Допустим, нужно угадать одно число из набора чисел от единицы до ста. По формуле Хартли можно вычислить, какое количество информации для этого требуется: I = log2100» 6,644. То есть сообщение о верно угаданном числе содержит количество информации, приблизительно равное 6,644 единиц информации. Определим являются ли равновероятными сообщения "первой выйдет из дверей здания женщина" и "первым выйдет из дверей здания мужчина". Однозначно ответить на этот вопрос нельзя. Все зависит от того, о каком именно здании идет речь. Если это, например, станция метро, то вероятность выйти из дверей первым одинакова для мужчины и женщины, а если это военная казарма, то для мужчины эта вероятность значительно выше, чем для женщины.
, где N- количество независимых кодируемых знаний, m – разрядность двоичного кодирования, принятого в данной системе. Допустим, нужно угадать одно число из набора чисел от единицы до ста. По формуле Хартли можно вычислить, какое количество информации для этого требуется: I = log2100» 6,644. То есть сообщение о верно угаданном числе содержит количество информации, приблизительно равное 6,644 единиц информации. Определим являются ли равновероятными сообщения "первой выйдет из дверей здания женщина" и "первым выйдет из дверей здания мужчина". Однозначно ответить на этот вопрос нельзя. Все зависит от того, о каком именно здании идет речь. Если это, например, станция метро, то вероятность выйти из дверей первым одинакова для мужчины и женщины, а если это военная казарма, то для мужчины эта вероятность значительно выше, чем для женщины.
Для задач такого рода американский учёный Клод Шеннон предложил в 1948 г. другую формулу определения количества информации, учитывающую возможную неодинаковую вероятность сообщений в наборе.
Неравноценные сообщения: Формула Шеннона: I = – (p1 log2 p1 + p2 log2 p2 +... + pN log2 pN),
где pi — вероятность того, что именно i-е сообщение выделено в наборе из N сообщений. В качестве единицы информации условились принять один бит (англ. bit — bi nary, digi t — двоичная цифра). Бит в теории информации — количество информации, необходимое для различения двух равновероятных сообщений. А в вычислительной технике битом называют наименьшую "порцию" памяти, необходимую для хранения одного из двух знаков "0" и "1", используемых для внутримашинного представления данных и команд. 1 Килобайт (Кбайт) = 1024 байт = 210 байт, 1 Мегабайт (Мбайт) = 1024 Кбайт = 220 байт, 1 Гигабайт (Гбайт) = 1024 Мбайт = 230 байт. 1 бод=1бит.сек. 1Кбод=1024бод.
За единицу информации можно было бы выбрать количество информации, необходимое для различения, например, десяти равновероятных сообщений. Это будет не двоичная (бит), а десятичная (дит) единица информации.
Вопрос№4.Кодирование числовых данных. Кодирование целых и вещественных чисел. Прямой,обратный,дополнительный код. Кодирование вещественных чисел с фиксированной и плавающей точкой. Двоичная арифметика.
Возможность единообразного представления данных различных типов является важным условием их автоматизированной обработки. Для этого обычно используется прием кодирования, то есть выражения данных одного типа через данные другого типа. В вычислительной технике наиболее распространенной системой кодирования данных различного типа является двоичный код, основанный на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски – binary digit или сокращенно bit (бит). Одним битом могут быть закодированы два различных значения (0 или 1, да или нет, истина или ложь, черное или белое и т.д.). Легко понять, что, увеличивая на единицу количество бит, мы вдвое увеличиваем количество значений, которые могут быть закодированы двоичным кодом. Например, двумя битами можно закодировать четыре значения, тремя – восемь и т.д. Обозначив максимально возможное количество кодируемых значений за N, а число бит (разрядность двоичного кода) за n,получаем простую формулу: 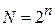 .(1)
.(1)
Заметим сразу, что эту формулу можно обобщить и на случай системы кодирования с произвольным числом знаков p:  .(2)
.(2)
Помимо двоичного кода в вычислительной технике широко применяются восьмеричный и шестнадцатеричный коды. В первом случае используются восемь различных цифр (от 0 до 7), а во втором – шестнадцать (набор из десяти цифр, применяемых в десятичной системе счисления, дополнен первыми шестью буквами латинского алфавита A, B, C, D, E и F; см. таблицу 1.1).
Некоторые системы счисления
| Система счисления | Основание | Цифры |
| 2чная | 2 | 0, 1 |
| 8чная | 8 | 0, 1, 2, 3, 4, 5, 6, 7 |
| 10чная | 10 | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 |
| 16чная | 16 | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F |
Кодирование целых и вещественных чисел. Целые числа могут представляться в компьютере со знаком или без знака. Целые числа кодируются двоичным кодом достаточно просто – достаточно взять целое число и делить его пополам до тех пор, пока в остатке не образуется 0 или 1. Целые числа без знака обычно занимают в памяти один или два байта и принимают в однобайтовом формате значения от 000000002 до 111111112, а в двубайтовом формате — от 00000000 000000002 до 11111111 111111112. Диапазоны значений целых чисел без знака
| Формат числа в байтах | Диапазон | |
| Запись с порядком | Обычная запись | |
| 1 | 0... 28–1 | 0... 255 |
| 2 | 0... 216–1 | 0... 65535 |
Примеры: а) число 7210 = 10010002 в однобайтовом формате:  б) это же число в двубайтовом формате:
б) это же число в двубайтовом формате:  в) число 65535 в двубайтовом формате:
в) число 65535 в двубайтовом формате:  Целые числа со знаком обычно занимают в памяти компьютера один, два или четыре байта, при этом самый левый (старший) разряд содержит информацию о знаке числа. Знак “плюс” кодируется нулем, а “минус” — единицей. Вещественные числа в (отличие от целых) в компьютерной технике называются числа, имеющие дробную часть. При их написании вместо запятой принято писать точку. Так, например, число 5 — целое, а числа 5.1 и 5.0 — вещественные. Для удобства отображения чисел, принимающих значения из достаточно широкого диапазона (то есть, как очень маленьких, так и очень больших), используется форма записи чисел с порядком основания системы счисления. Например, десятичное число 1.25 можно в этой форме представить так: 1.25*100 = 0.125*101 = 0.0125*102 =...,или так: 12.5*10–1 = 125.0*10–2 = 1250.0*10–3 =.... Любое число N в системе счисления с основанием q можно записать в виде N = M * qp, где M называется мантиссой числа, а p — порядком. Такой способ записи чисел называется представлением с плавающей точкой. Если “плавающая” точка расположена в мантиссе перед первой значащей цифрой, то при фиксированном количестве разрядов, отведённых под мантиссу, обеспечивается запись максимального количества значащих цифр числа, то есть максимальная точность представления числа в машине. Из этого следует: Мантисса должна быть правильной дробью, первая цифра которой отлична от нуля: M из [0.1, 1). Такое, наиболее выгодное для компьютера, представление вещественных чисел называется нормализованным. Мантиссу и порядок q-ичного числа принято записывать в системе с основанием q, а само основание — в десятичной системе. Примеры нормализованного представления:
Целые числа со знаком обычно занимают в памяти компьютера один, два или четыре байта, при этом самый левый (старший) разряд содержит информацию о знаке числа. Знак “плюс” кодируется нулем, а “минус” — единицей. Вещественные числа в (отличие от целых) в компьютерной технике называются числа, имеющие дробную часть. При их написании вместо запятой принято писать точку. Так, например, число 5 — целое, а числа 5.1 и 5.0 — вещественные. Для удобства отображения чисел, принимающих значения из достаточно широкого диапазона (то есть, как очень маленьких, так и очень больших), используется форма записи чисел с порядком основания системы счисления. Например, десятичное число 1.25 можно в этой форме представить так: 1.25*100 = 0.125*101 = 0.0125*102 =...,или так: 12.5*10–1 = 125.0*10–2 = 1250.0*10–3 =.... Любое число N в системе счисления с основанием q можно записать в виде N = M * qp, где M называется мантиссой числа, а p — порядком. Такой способ записи чисел называется представлением с плавающей точкой. Если “плавающая” точка расположена в мантиссе перед первой значащей цифрой, то при фиксированном количестве разрядов, отведённых под мантиссу, обеспечивается запись максимального количества значащих цифр числа, то есть максимальная точность представления числа в машине. Из этого следует: Мантисса должна быть правильной дробью, первая цифра которой отлична от нуля: M из [0.1, 1). Такое, наиболее выгодное для компьютера, представление вещественных чисел называется нормализованным. Мантиссу и порядок q-ичного числа принято записывать в системе с основанием q, а само основание — в десятичной системе. Примеры нормализованного представления:
Десятичная система: 753.15 = 0.75315*103; -101.01 = -0.10101*211 (порядок 112 = 310) Двоичная система: -0.000034 = -0.34*10-4; -0.000011 = 0.11*2-100 (порядок -1002 = -410) Вещественные числа в компьютерах различных типов записываются по-разному. При этом компьютер обычно предоставляет программисту возможность выбора из нескольких числовых форматов наиболее подходящего для конкретной задачи — с использованием четырех, шести, восьми или десяти байтов. В качестве примера приведем характеристики форматов вещественных чисел, используемых IBM-совместимыми персональными компьютерами:
| Форматы вещественных чисел | Размер в байтах | Примерный диапазон абсолютных значений | Количество значащих десятичных цифр |
| Одинарный | 4 | 10–45 … 1038 | 7 или 8 |
| Вещественный | 6 | 10–39 … 1038 | 11 или 12 |
| Двойной | 8 | 10–324 … 10308 | 15 или 16 |
| Расширенный | 10 | 10–4932 … 104932 | 19 или 20 |
Из этой таблицы видно, что форма представления чисел с плавающей точкой позволяет записывать числа с высокой точностью и из весьма широкого диапазона. При хранении числа с плавающей точкой отводятся разряды для мантиссы, порядка, знака числа и знака порядка:

· Чем больше разрядов отводится под запись мантиссы, тем выше точность представления числа.
· Чем больше разрядов занимает порядок, тем шире диапазон от наименьшего отличного от нуля числа до наибольшего числа, представимого в машине при заданном формате. В компьютерной технике применяются 3 формы записи (кодирования) целых чисел со знаком: прямой код, обратный код, дополнительный. Последние две формы применяются особенно широко, так как позволяют упростить конструкцию арифметико-логического устройства компьютера путем замены разнообразных арифметических операций операцией cложения. Положительные числа в прямом, обратном и дополнительном кодах изображаются одинаково — двоичными кодами с цифрой 0 в знаковом разряде. Например:

Отрицательные числа в прямом, обратном и дополнительном кодах имеют разное изображение. 1. Прямой код. В знаковый разряд помещается цифра 1, а в разряды цифровой части числа — двоичный код его абсолютной величины. Например:  2. Обратный код. Получается инвертированием всех цифр двоичного кода абсолютной величины числа, включая разряд знака: нули заменяются единицами, а единицы — нулями. Например:
2. Обратный код. Получается инвертированием всех цифр двоичного кода абсолютной величины числа, включая разряд знака: нули заменяются единицами, а единицы — нулями. Например:  3. Дополнительный код. Получается образованием обратного кода с последующим прибавлением единицы к его младшему разряду. Например:
3. Дополнительный код. Получается образованием обратного кода с последующим прибавлением единицы к его младшему разряду. Например: 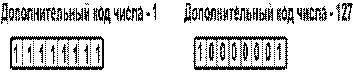
| Обычно отрицательные десятичные числа при вводе в машину автоматически преобразуются в обратный или дополнительный двоичный код и в таком виде хранятся, перемещаются и участвуют в операциях. При выводе таких чисел из машины происходит обратное преобразование в отрицательные десятичные числа. |
Сложение и вычитание
| В большинстве компьютеров операция вычитания не используется. Вместо нее производится сложение уменьшаемого с обратным или дополнительным кодом вычитаемого. Это позволяет существенно упростить конструкцию АЛУ. |
При сложении обратных кодов чисел А и В имеют место четыре основных и два особых случая: 1. А и В положительные. При суммировании складываются все разряды, включая разряд знака. Так как знаковые разряды положительных слагаемых равны нулю, разряд знака суммы тоже равен нулю. Например:  Получен правильный результат. 2. А положительное, B отрицательное и по абсолютной величине больше, чем А. Например:
Получен правильный результат. 2. А положительное, B отрицательное и по абсолютной величине больше, чем А. Например:  Получен правильный результат в обратном коде. При переводе в прямой код биты цифровой части результата инвертируются: 1 0000111 = –710. 3. А положительное, B отрицательное и по абсолютной величине меньше, чем А. Например:
Получен правильный результат в обратном коде. При переводе в прямой код биты цифровой части результата инвертируются: 1 0000111 = –710. 3. А положительное, B отрицательное и по абсолютной величине меньше, чем А. Например:  Компьютер исправляет полученный первоначально неправильный результат (6 вместо 7) переносом единицы из знакового разряда в младший разряд суммы. 4. А и В отрицательные. Например:
Компьютер исправляет полученный первоначально неправильный результат (6 вместо 7) переносом единицы из знакового разряда в младший разряд суммы. 4. А и В отрицательные. Например:  Полученный первоначально неправильный результат (обратный код числа –1110 вместо обратного кода числа –1010) компьютер исправляет переносом единицы из знакового разряда в младший разряд суммы. При переводе результата в прямой код биты цифровой части числа инвертируются: 1 0001010 = –1010. При сложении может возникнуть ситуация, когда старшие разряды результата операции не помещаются в отведенной для него области памяти. Такая ситуация называется переполнением разрядной сетки формата числа. Для обнаружения переполнения и оповещения о возникшей ошибке в компьютере используются специальные средства. Ниже приведены два возможных случая переполнения.
Полученный первоначально неправильный результат (обратный код числа –1110 вместо обратного кода числа –1010) компьютер исправляет переносом единицы из знакового разряда в младший разряд суммы. При переводе результата в прямой код биты цифровой части числа инвертируются: 1 0001010 = –1010. При сложении может возникнуть ситуация, когда старшие разряды результата операции не помещаются в отведенной для него области памяти. Такая ситуация называется переполнением разрядной сетки формата числа. Для обнаружения переполнения и оповещения о возникшей ошибке в компьютере используются специальные средства. Ниже приведены два возможных случая переполнения.
5. А и В положительные, сумма А+В больше, либо равна 2n–1, где n – количество разрядов формата чисел (для однобайтового формата n=8, 2n–1 = 27 = 128). Например: 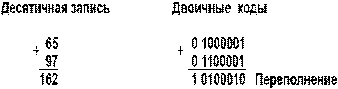 Семи разрядов цифровой части числового формата недостаточно для размещения восьмиразрядной суммы (16210 = 101000102), поэтому старший разряд суммы оказывается в знаковом разряде. Это вызывает несовпадение знака суммы и знаков слагаемых, что является свидетельством переполнения разрядной сетки.
Семи разрядов цифровой части числового формата недостаточно для размещения восьмиразрядной суммы (16210 = 101000102), поэтому старший разряд суммы оказывается в знаковом разряде. Это вызывает несовпадение знака суммы и знаков слагаемых, что является свидетельством переполнения разрядной сетки.
6. А и В отрицательные, сумма абсолютных величин А и В больше, либо равна 2n–1. Например: 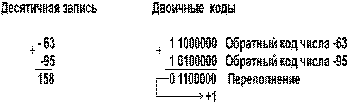 Здесь знак суммы тоже не совпадает со знаками слагаемых, что свидетельствует о переполнении разрядной сетки. Все эти случаи имеют место и при сложении дополнительных кодов чисел: 1. А и В положительные. Здесь нет отличий от случая 1, рассмотренного для обратного кода.
Здесь знак суммы тоже не совпадает со знаками слагаемых, что свидетельствует о переполнении разрядной сетки. Все эти случаи имеют место и при сложении дополнительных кодов чисел: 1. А и В положительные. Здесь нет отличий от случая 1, рассмотренного для обратного кода.
2. А положительное, B отрицательное и по абсолютной величине больше, чем А. Например:  Получен правильный результат в дополнительном коде. При переводе в прямой код биты цифровой части результата инвертируются и к младшему разряду прибавляется единица: 1 0000110 + 1 = 1 0000111 = –710.
Получен правильный результат в дополнительном коде. При переводе в прямой код биты цифровой части результата инвертируются и к младшему разряду прибавляется единица: 1 0000110 + 1 = 1 0000111 = –710.
3. А положительное, B отрицательное и по абсолютной величине меньше, чем А. Например:  Получен правильный результат. Единицу переноса из знакового разряда компьютер отбрасывает.
Получен правильный результат. Единицу переноса из знакового разряда компьютер отбрасывает.
4. А и В отрицательные. Например:  Получен правильный результат в дополнительном коде. Единицу переноса из знакового разряда компьютер отбрасывает. Случаи переполнения для дополнительных кодов рассматриваются по аналогии со случаями 5 и 6 для обратных кодов. Сравнение рассмотренных форм кодирования целых чисел со знаком показывает: на преобразование отрицательного числа в обратный код компьютер затрачивает меньше времени, чем на преобразование в дополнительный код, так как последнее состоит из двух шагов — образования обратного кода и прибавления единицы к его младшему разряду; время выполнения сложения для дополнительных кодов чисел меньше, чем для их обратных кодов, потому что в таком сложении нет переноса единицы из знакового разряда в младший разряд результата.
Получен правильный результат в дополнительном коде. Единицу переноса из знакового разряда компьютер отбрасывает. Случаи переполнения для дополнительных кодов рассматриваются по аналогии со случаями 5 и 6 для обратных кодов. Сравнение рассмотренных форм кодирования целых чисел со знаком показывает: на преобразование отрицательного числа в обратный код компьютер затрачивает меньше времени, чем на преобразование в дополнительный код, так как последнее состоит из двух шагов — образования обратного кода и прибавления единицы к его младшему разряду; время выполнения сложения для дополнительных кодов чисел меньше, чем для их обратных кодов, потому что в таком сложении нет переноса единицы из знакового разряда в младший разряд результата.
Умножение и деление
Во многих компьютерах умножение производится как последовательность сложений и сдвигов. Для этого в АЛУ имеется регистр, называемый накапливающим сумматором, который до начала выполнения операции содержит число ноль. В процессе выполнения операции в нем поочередно размещаются множимое и результаты промежуточных сложений, а по завершении операции — окончательный результат. Другой регистр АЛУ, участвующий в выполнении этой операции, вначале содержит множитель. Затем по мере выполнения сложений содержащееся в нем число уменьшается, пока не достигнет нулевого значения. Для иллюстрации умножим 1100112 на 1011012. 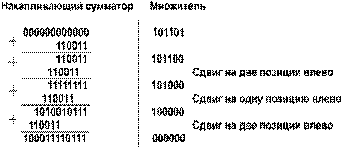 Деление для компьютера является трудной операцией. Обычно оно реализуется путем многократного прибавления к делимому дополнительного кода делителя.
Деление для компьютера является трудной операцией. Обычно оно реализуется путем многократного прибавления к делимому дополнительного кода делителя.
Вопрос №5. Кодирование текстовых данных. Кодовые таблицы. ASCII-код. Кодирование символов национальных алфавитов. Unicode. Если каждому символу алфавита поставить в соответствие определенное целое число (например, просто порядковый номер), то с помощью числового кода можно записывать и текстовые данные. Восьми двоичных разрядов хватает для кодирования 28=256 различных символов. Такого количества вполне достаточно, чтобы вместить все прописные и строчные буквы латинского алфавита и еще одного алфавита (например, кириллицы), а также знаки препинания и необходимые вспомогательные символы (знаки арифметических действий, процента, денежной единицы и др.). Соответствие между символом и его числовым кодом задается таблицей кодирования (кодовой таблицей) или просто кодировкой. Ясно, что простой перестановкой символов или их кодов можно получить различные варианты таблиц кодирования. С точки зрения возможности кодирования данных все они абсолютно равноправны. Однако попытка прочесть (декодировать) данные при помощи кодовой таблицы, отличной от той, которая была использована при кодировании, приведет к тому, что мы получим неверные символы (содержание данных будет ошибочно изменено, передаваемая информация утеряна). Такого рода проблемы часто возникают при обмене текстовыми данными на различных языках, например, по компьютерным сетям. Для английского языка, являющегося де-факто средством межнационального общения, существует общепризнанная стандартная таблица кодирования ASCII (American Standard Code for Informational Interchange – стандартный код для информационного обмена США). Таблица ASCII закрепляет значения кодов от 0 до 127 за специальными управляющими кодами (в том числе кодами перемещения курсора, удаления символа, конца строки), символами английского языка, цифрами, знаками препинания и другими общеупотребительными символами. Это так называемая базовая таблица ASCII. Диапазон кодов с 128 до 255 может быть использован для кодирования символов национальных языков. Именно в этой части чаще всего отличаются друг от друга применяемые в разных странах кодовые таблицы. В России на сегодняшний день действуют в основном три стандарта кодировки: Windows-1251, КОИ-8 и ISO. Кодировка Windows-1251, введенная компанией Microsoft, получила очень широкое распространение вместе с операционными системами и прикладными программными продуктами этой фирмы. Кодировка КОИ-8 (код обмена информацией восьмизначный) распространена в русскоязычном секторе Интернета. Кодировка ISO, введенная Международным институтом стандартизации (International Standard Organization), на практике используется реже. Для преодоления организационных трудностей, связанных с созданием единой системы кодирования текстовых данных на разных национальных языках, необходимо, очевидно, увеличить размер кодовой таблицы. Такая система кодирования существует и называется универсальной (Unicode). В системе Unicode для кодирования одного символа используется не восемь, а шестнадцать бит. По формуле (1) можно подсчитать, что количество кодовых комбинаций в этой системе составляет 216=65 536 – этого достаточно, чтобы разместить в одной таблице символы большинства языков планеты.