2020-04-20
2020-04-20 206
206Усі явища навколишнього світу взаємопов'язані й взаємозумовлені. У складному переплетенні всеохоплюючого взаємозв'язку будь-яке з них є наслідком дії певної множини причин і водночас причиною інших явищ.
Логічний зміст і практичну значущість статистичних моделей взаємозв'язку слід розглядати саме в площині співвідношення причинності і зв'язків, що вимірюються статистичними методами. Суть причинності полягає в породженні одного явища іншим. Причина — активна основа, що примушує інше явище змінюватися. Сама по собі причина не визначає наслідку. Останній залежить і від умов, у яких діє причина. Через нерозрізненість причин і умов при моделюванні вони об'єднуються в одне поняття «фактор», а наслідок розглядається як результат дії факторів. Отже, в рамках моделі досліджується детермінованість результату факторами.
Методологічні проблеми побудови моделей взаємозв'язку можна об'єднати в дві групи:
- формування ознакової множини моделі, себто визначення кількості факторів та їх числових еквівалентів;
- модельна специфікація — вибір функціонального виду моделі, ідентифікація та оцінювання параметрів.
При формуванні ознакової множини моделі різноманітні прояви причинно-наслідкових зв'язків доцільно представляти візуально у вигляді спеціальних конструкцій — графів зв'язку, елементами яких е вершини та орієнтовані ребра (дуги). Вершини графа відповідають ознакам, а дуги показують відношення між ознаками. На рис. 2.1 ілюструється граф зв'язку чотирьох ознак. За дугами графа можна простежити систему відношень між ними: х впливає на у прямо, безпосередньо, z — прямо та опосередковано двома шляхами: 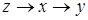 та
та 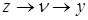 . У такій логічній конструкції ознака у єрезультатом, а х, z і
. У такій логічній конструкції ознака у єрезультатом, а х, z і 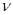 — факторами, що визначають результат.
— факторами, що визначають результат.
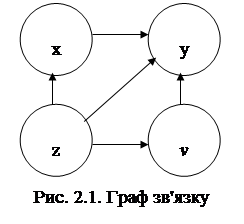 |
Граф відображує теоретично обґрунтовану систему відношень між ознаками. Кожна ланка цієї системи розглядається як окрема гіпотеза, що підлягає перевірці в подальшому аналізі на усіх етапах побудови моделі. Основна мета моделей взаємозв'язку - виявити і кількісно виміряти вплив факторів на результат. Очевидно, щоб визначити ефект впливу і-го фактора, необхідно елімінувати (усунути) вплив інших факторів, умовно зафіксувавши їх шляхом відповідних розрахунків на одному і тому ж рівні.
На етапі модельної специфікації враховується характер зв'язку та особливості наявної інформації. За своїм характером зв'язки поділяються на стохастичні, різновидом яких є кореляційні зв'язки, та жорстко детерміновані (функціональні). Перші відображують стохастичний характер причинно-наслідкових відношень, Другі - адитивні чи мультиплікативні зв'язки між елементами розрахункових формул показників. Відповідно вибирається функціональна форма моделі: кореляційні зв'язки описуються переважно регресійними моделями, функціональні - балансовими або індексними. У моделях, що описують функціональні зв'язки, ступінь вільності при формуванні ознакової множини обмежена, маневрувати можна лише кількістю факторів, укрупнюючи їх чи деталізуючи. Для регресійних моделей характерна багатоваріантність як ознакової множини, так і функціональної форми моделі. Інформаційна база моделі залежить від того, як представлено об’єкт моделювання. Якщо він розглядається як сукупність елементів у просторі, то інформація подається просторовими рядами
У вигляді матриці обсягом 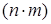 , де п - обсяг сукупності, т - кількість включених у модель факторів. Класична регресія передбачає однорідність сукупності, тобто всі одиниці сукупності мають бути однотипними щодо комплексу умов існування, а властиві їм закономірності однаковими для усіх одиниць без винятку. Якщо сукупність внутрішньо диференційована, має у своєму складі певні групи (класи) одиниць зі специфічним характером зв'язку, в моделі слід врахувати неоднорідність за принципом структурної подібності. Методи відображення неоднорідності залежать від характеру та сталості міжгрупових розбіжностей.
, де п - обсяг сукупності, т - кількість включених у модель факторів. Класична регресія передбачає однорідність сукупності, тобто всі одиниці сукупності мають бути однотипними щодо комплексу умов існування, а властиві їм закономірності однаковими для усіх одиниць без винятку. Якщо сукупність внутрішньо диференційована, має у своєму складі певні групи (класи) одиниць зі специфічним характером зв'язку, в моделі слід врахувати неоднорідність за принципом структурної подібності. Методи відображення неоднорідності залежать від характеру та сталості міжгрупових розбіжностей.
Моделі, побудовані у просторовій площині, охоплюють одиничний, фіксований інтервал часу. Серія такого типу моделей за певний період дає можливість простежити динаміку взаємозв'язків, оцінити зміну потужності впливу окремих факторів, його перерозподіл.
Якщо об'єкт моделювання розглядається як первинний, неподільний елемент (галузь економіки, регіон, країна), то інформаційна база представляється багатовимірним динамічним рядом у вигляді матриці обсягом (т • Т), де Т- довжина динамічного ряду. В такому разі в моделі необхідно відобразити властиві процесу закономірності динаміки, як-от: тенденції, коливання, запізнення впливу тощо. За умови, що об'єкт моделювання нечисленний, а довжина динамічного ряду обмежена, просторові та динамічні ряди об'єднуються.
На практиці використовують переважно автономно побудовані моделі, тобто моделі одного показника-функції. Специфікація моделі залежить від її призначення, природи і структури взаємозв'язків, специфіки об'єкта моделювання, наявної інформації. Поєднання, комбінація усіх цих елементів визначає безліч типів моделей.
В автономних регресійних моделях (одного рівняння) відбувається складний процес елімінування впливів між включеними в модель факторами і виокремлення безпосереднього впливу кожного з них на результат. Фактичне використання такої моделі передбачає, що в разі необхідності рівні факторів можна змінювати незалежно один від одного. Проте в реальних умовах зміна одного фактора не може відбуватися за незмінності інших, вона спричиняє ланцюгову реакцію в усій системі взаємозв'язаних показників. Поряд з безпосереднім прямим впливом має місце опосередкований вплив, часом за різними напрямами, що потребує оцінювання сумарного впливу. Іноді одна й та сама змінна виступає водночас причиною і наслідком. Тоді виникає необхідність одночасного оцінювання прямого і зворотного впливів.
Складне переплетення взаємозв'язків соціально-економічних явищ потребує і складних інструментів аналізу. З-поміж таких інструментів є системи рівнянь, заміна множин висококорельованих ознак інтегральними факторами (головними компонентами) тощо. Методологічні засади модельної специфікації розглядаються за принципом «від простого до складного».
Класична регресія
Регресійна модель описує об'єктивно існуючі між явищами кореляційні зв'язки. За своїм характером кореляційні зв'язки надзвичайно складні та різноманітні. В одних випадках результат у зі зміною фактора х, зростає чи зменшується рівномірно, в інших — нерівномірно. Іноді зростання може змінитися зменшенням і навпаки. Простежити всі ці взаємозв'язки і встановити точний функціональний вид практично неможливо. А тому при виборі типу функції йдеться лише про апроксимацію відносно простими функціями незрівнянно більш складних за своєю природою взаємозв'язків. На практиці перевагу віддають моделям, які є лінійними або приводяться до лінійного виду шляхом перетворення змінних, наприклад логарифмуванням. Такий підхід, безперечно, містить у собі певну умовність, оскільки передбачає однаковий характер зв'язку з усіма факторами. Проте використання надто складних функцій неминуче веде до збільшення кількості параметрів, а отже, зменшує точність вимірювання та ускладнює інтерпретацію результатів.
При обґрунтуванні типу функції слід враховувати й той факт, що межі варіації корельованих ознак у конкретних умовах простору і часу, в конкретній сукупності значно вужчі за їх можливі значення, і в цих межах варіації навіть лінійна функція може задовільно апроксимувати зв'язок.
У лінійному щодо параметрів рівнянні регресії індивідуальне значення результативного показника 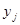 (де j — порядковий номер одиниці сукупності) записується так:
(де j — порядковий номер одиниці сукупності) записується так:
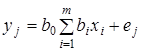 ,
,
де 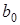 — вільний член рівняння; економічного змісту, як правило, не має, лише окреслює область існування моделі;
— вільний член рівняння; економічного змісту, як правило, не має, лише окреслює область існування моделі; 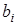 — коефіцієнт регресії;показує, як в середньому змінюється
— коефіцієнт регресії;показує, як в середньому змінюється 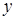 зі зміною
зі зміною 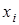 на одиницю її шкали вимірювання за незмінності інших включених в модель факторів і за інших рівних умов;
на одиницю її шкали вимірювання за незмінності інших включених в модель факторів і за інших рівних умов; 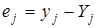 — залишкова величина.
— залишкова величина.
У регресійній моделі основне навантаження покладається на коефіцієнт регресії 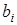 , він розглядається як своєрідна міра «очищеного» впливу
, він розглядається як своєрідна міра «очищеного» впливу 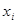 на у і називається ефектом впливу.
на у і називається ефектом впливу.
Процедура оцінювання параметрів регресійної моделі ґрунтується на методі найменших квадратів (МНК). Оскільки алгоритми МНК описано в математико-статистичній літературі й реалізовано в комп'ютерних програмах, наведемо лише загальну схему розрахунку статистичних характеристик моделі, акцентуючи увагу на їх змістовній інтерпретації.
Первинна інформація представляється як матриця факторних ознак X розміром (п • т) і вектора результативної ознаки у розміром (п • 1). Задля зручності використання алгоритмів МНК матриця X розширюється за рахунок додатково введеної фіктивної змінної 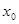 , вектор якої представлений одиницями. Параметри моделі — вектор
, вектор якої представлений одиницями. Параметри моделі — вектор 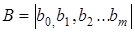 визначаються розв'язуванням системи нормальних рівнянь, яка записується так:
визначаються розв'язуванням системи нормальних рівнянь, яка записується так:
X'ХВ = 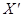 у,
у,
де X — матриця розміром п (т + 1).
Послідовність розрахунків включає етапи:
- обчислення матриці 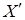 X і вектора у
X і вектора у
- обертання матриці С = 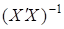 ;
;
- розрахунок параметрів 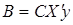 ;
;
- визначення теоретичних значень результативної ознаки  та залишків
та залишків 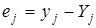 .
.
Значення коефіцієнтів регресії певною мірою залежать від складу введених у модель факторів.
З розширенням ознакової множини моделі відбувається перерозподіл впливу попередньо введених факторів. Чим вагоміший вплив нововведеного фактора, тим помітніші зміни. Ілюстрацією перерозподілу впливу факторів може слугувати регресійна модель урожайності рису, ц/га [11]. У модель послідовно вводились агротехнічні фактори: 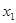 — попередник, балів;
— попередник, балів; 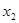 — внесення добрив під основний обробіток, центнерів поживної речовини (ц п. р.) на 1 га посіву;
— внесення добрив під основний обробіток, центнерів поживної речовини (ц п. р.) на 1 га посіву; 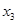 — передпосівний обробіток, та м'якої оранки;
— передпосівний обробіток, та м'якої оранки; 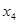 — підживлення, ц п. р.;
— підживлення, ц п. р.; 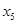 — норма висіву;
— норма висіву;  — кількість прополювань. Відповідно отримано такі рівняння регресії:
— кількість прополювань. Відповідно отримано такі рівняння регресії:
1. Y=30,432 + 3,001 ;
2. Y= 26,208 + 2,049 + 5,995 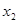 ;
;
3. Y= 21,563 + 1,970 + 4,610 + 2,906 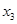 ;
;
4. Y= 22,332 + 1,321 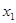 + 4,558
+ 4,558 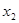 + 1,465 + 9,791
+ 1,465 + 9,791 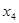 ;
;
5. Y= 18,960 + 1,342 + 4,483 + 1,347 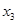 + 9,545 + 1,756 ;
+ 9,545 + 1,756 ;
6. Y= 19,387+ 0,965 , + 3,400 + 0,501 + 7,500 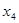 + 1,73
+ 1,73 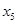 + 3,433
+ 3,433 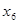 .
.
Як бачимо, введення кожного нового фактора спричиняє зменшення впливу попередньо введених факторів, таку ж тенденції має й вільний член рівняння.
Оскільки факторні ознаки мають, як правило, різні одиниці вимірювання, то для порівняння ефектів їх впливу в рамках моделі використовують стандартизовані коефіцієнти регресії 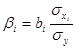 (бета-коефіцієнти) або коефіцієнти еластичності -
(бета-коефіцієнти) або коефіцієнти еластичності -  . Бета-коефіцієнт характеризує ефект впливу
. Бета-коефіцієнт характеризує ефект впливу 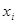 на у в середньоквадратичних відхиленнях, коефіцієнт еластичності — в процентах. У табл. 5.2 наведено бета-коефіцієнти останнього (шостого) варіанта моделі врожайності рису. Згідно із значеннями Р, найвагоміший вплив на врожайність рису мають: прополювання (
на у в середньоквадратичних відхиленнях, коефіцієнт еластичності — в процентах. У табл. 5.2 наведено бета-коефіцієнти останнього (шостого) варіанта моделі врожайності рису. Згідно із значеннями Р, найвагоміший вплив на врожайність рису мають: прополювання (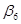 = 0,360), підживлення
= 0,360), підживлення 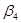 = 0,264), внесення добрив під основний обробіток (
= 0,264), внесення добрив під основний обробіток (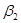 = 0,248).
= 0,248).
Для оцінювання адекватності регресійної моделі використовують:
- стандартне відхилення;
- множинні коефіцієнти детермінації та кореляції;
- частинні коефіцієнти детермінації та кореляції;
- коефіцієнти окремої детермінації;
- критерії перевірки істотності зв'язку.
Стандартне відхилення характеризує варіацію залишковихвеличин
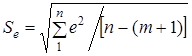 ,
,
де n — обсяг сукупності, т — кількість коефіцієнтів регресії.
Розрахунок характеристик щільності зв'язку ґрунтується на декомпозиції (розкладанні) варіації у за джерелами формування:
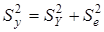 ,
,
де 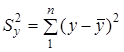 — загальна сума квадратів відхилень, зумовлена впливом усіх можливих факторів;
— загальна сума квадратів відхилень, зумовлена впливом усіх можливих факторів; 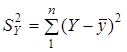 — факторна сума квадратів відхилень, зумовлена впливом включених у модель факторних ознак ;
— факторна сума квадратів відхилень, зумовлена впливом включених у модель факторних ознак ; 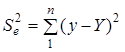 — залишкова сума квадратів відхилень, розмір якої залежить від потужності впливу не включених у модель факторів.
— залишкова сума квадратів відхилень, розмір якої залежить від потужності впливу не включених у модель факторів.
Відношення факторної суми квадратів до загальної характеризує частку варіації у, пов'язану з варіацією включених у модель факторів, і називається множинним коефіцієнтом детермінації
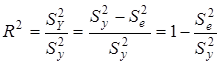 .
.
За відсутності зв'язку 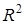 = 0. Якщо зв'язок функціональний, то
= 0. Якщо зв'язок функціональний, то 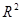 = 1. Очевидно, що
= 1. Очевидно, що 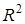 пов'язаний із стандартним відхиленням
пов'язаний із стандартним відхиленням 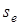 . При зменшенні
. При зменшенні 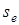 значення зростатиме і навпаки. Корінь квадратний із коефіцієнта детермінації називають коефіцієнтом кореляції
значення зростатиме і навпаки. Корінь квадратний із коефіцієнта детермінації називають коефіцієнтом кореляції 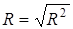 . Для моделі врожайності рису R = 0,8394,
. Для моделі врожайності рису R = 0,8394, 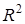 = 0,7029, тобто 70,29% варіації врожайності рису лінійно пов'язані з агротехнічними факторами, включеними в модель.
= 0,7029, тобто 70,29% варіації врожайності рису лінійно пов'язані з агротехнічними факторами, включеними в модель.
Окрім названих множинних коефіцієнтів щільності зв'язку, в комп'ютерних програмах передбачено розрахунок з урахуванням числа ступенів вільності:
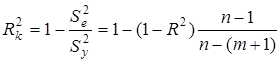 ,
,
де 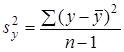 — оцінка дисперсії результативної ознаки у;
— оцінка дисперсії результативної ознаки у; 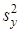 — оцінка залишкової дисперсії.
— оцінка залишкової дисперсії.
Скоригований коефіцієнт множинної детермінації 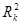 відрізняється від
відрізняється від 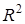 співвідношенням числа ступенів вільності дисперсій: залишкової
співвідношенням числа ступенів вільності дисперсій: залишкової 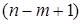 і загальної
і загальної 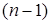 . Для розглянутої моделі це співвідношення становить (34-1): (34-6-1) = 1,2222, а = 1-(1-0,7029) • 1,2222 = 0,6369.
. Для розглянутої моделі це співвідношення становить (34-1): (34-6-1) = 1,2222, а = 1-(1-0,7029) • 1,2222 = 0,6369.
У моделях множинної регресії поряд з оцінкою сукупного впливу всіх включених у модель факторів вимірюється кореляція між функцією у та кожним окремим фактором , при елімінуванні впливу інших факторів. Для цього використовують частинні коефіцієнти детермінації 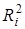 . Схему розрахунку
. Схему розрахунку 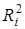 розглянемо на прикладі фактора
розглянемо на прикладі фактора 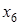 моделі врожайності рису. До введення його в модель п'ять факторів пояснювали 64,61% варіації врожайності (
моделі врожайності рису. До введення його в модель п'ять факторів пояснювали 64,61% варіації врожайності (  = 0,6461), не поясненими залишалися (1 - 0,6461) • 100 = 35,39% варіації. Фактор додатково пояснив 0,7029 — 0,6461 =0,0568 варіації у, що відносно не поясненої іншими факторами варіації становить 0,0568:0,3539 = 0,1605. Це і є частинним коефіцієнтом детермінації фактора
= 0,6461), не поясненими залишалися (1 - 0,6461) • 100 = 35,39% варіації. Фактор додатково пояснив 0,7029 — 0,6461 =0,0568 варіації у, що відносно не поясненої іншими факторами варіації становить 0,0568:0,3539 = 0,1605. Це і є частинним коефіцієнтом детермінації фактора  .
.
Отже, розрахунок ґрунтується на порівнянні двох регресійних моделей: повної, з урахуванням фактора і скороченої, у якій фактор відсутній. Чисельник дорівнює різниці сукупних коефіцієнтів детермінації цих моделей, знаменник — одиниці мінус сукупний коефіцієнт детермінації скороченої моделі. Загальну схему його розрахунку можна представити як відношення сум квадратів: частинної 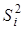 і залишкової
і залишкової 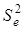 :
:
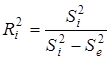 ,
,
де 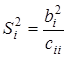 ;
; 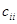 — діагональний елемент оберненої матриці.
— діагональний елемент оберненої матриці.
Корінь квадратний із частинного коефіцієнта детермінації називають частинним коефіцієнтом кореляції.
Іноді для характеристики ролі кожного фактора у відтворенні варіації у сукупний коефіцієнт детермінації розкладають на складові:
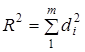 ,
,
де 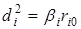 — коефіцієнт окремої детермінації, який залежить від потужності впливу і-го фактора на y та щільності зв'язку між ними (
— коефіцієнт окремої детермінації, який залежить від потужності впливу і-го фактора на y та щільності зв'язку між ними (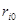 — парний коефіцієнт кореляції).
— парний коефіцієнт кореляції).
Ефекти впливу факторів на врожайність рису та характеристики щільності зв'язку наведено в табл. 2.3.
Таблиця 2.3
| Фактор | 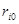
| 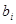
| 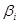
| 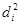
| 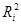
|
|
| 0,597 | 0,965 | 0,192 | 0,1146 | 0,0727 |
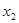
| 0,614 | 3,400 | 0,248 | 0,1521 | 0,1160 |
|
| 0,489 | 0,501 | 0,045 | 0,0221 | 0,0039 |
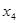
| 0,638 | 7,500 | 0,264 | 0,1687 | 0,1168 |
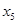
| 0,411 | 1,730 | 0,029 | 0,0119 | 0,0020 |
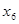
| 0,716 | 3,443 | 0,362 | 0,2335 | 0,1605 |
У таблиці для кожного фактора наведено три характеристики спільності зв'язку: парний коефіцієнт 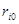 , частинний
, частинний 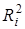 і коефіцієнт окремої детермінації
і коефіцієнт окремої детермінації 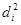 . Найбільші значення мають парні коефіцієнти кореляції. Це пояснюється тим, що фактори взаємозалежні, і парний коефіцієнт кореляції акумулює вплив інших факторів. Частинні коефіцієнти характеризують відносну зміну залишкової дисперсії за рахунок відповідного фактора; для кожного з них база порівняння інша, а тому аналітичні можливості їх обмежені. Коефіцієнти окремої детермінації, сума яких дорівнює множинному коефіцієнту детермінації =0,7029, упорядковуючи фактори за потужністю впливу, практично дублюють висновки, які можна зробити на основі бета-коефіцієнтів.
. Найбільші значення мають парні коефіцієнти кореляції. Це пояснюється тим, що фактори взаємозалежні, і парний коефіцієнт кореляції акумулює вплив інших факторів. Частинні коефіцієнти характеризують відносну зміну залишкової дисперсії за рахунок відповідного фактора; для кожного з них база порівняння інша, а тому аналітичні можливості їх обмежені. Коефіцієнти окремої детермінації, сума яких дорівнює множинному коефіцієнту детермінації =0,7029, упорядковуючи фактори за потужністю впливу, практично дублюють висновки, які можна зробити на основі бета-коефіцієнтів.
Перевірка істотності зв'язку статистичне формулюється як перевірка нульових гіпотез: 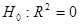 ;
; 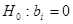 . Гіпотеза
. Гіпотеза 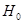 відхиляється чи визнається допустимою на основі статистичних критеріїв, зокрема дисперсійного F-критерію, статистична характеристика якого розраховується відношенням оцінок факторної і залишкової дисперсій:
відхиляється чи визнається допустимою на основі статистичних критеріїв, зокрема дисперсійного F-критерію, статистична характеристика якого розраховується відношенням оцінок факторної і залишкової дисперсій:
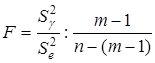 або
або 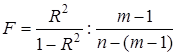 .
.
Критичні значення 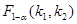 , де
, де 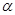 — рівень істотності,
— рівень істотності, 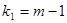 ,
,  — числа ступенів вільності чисельника та знаменника, наведено в додатку 10. Оскільки F-критерій функціонально зв'язаний з коефіцієнтом детермінації , то перевірку істотності зв'язку можна здійснити, використовуючи безпосередньо критичні значення
— числа ступенів вільності чисельника та знаменника, наведено в додатку 10. Оскільки F-критерій функціонально зв'язаний з коефіцієнтом детермінації , то перевірку істотності зв'язку можна здійснити, використовуючи безпосередньо критичні значення 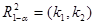 , наведені в додатку 11.
, наведені в додатку 11.
Паралельно з оцінюванням адекватності моделі проводиться перевірка істотності впливу окремих факторів , на у за допомогою t-критерію:
 ,
,
де 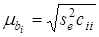 — стандартна похибка коефіцієнта регресії;
— стандартна похибка коефіцієнта регресії; 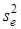 —оцінка залишкової дисперсії;
—оцінка залишкової дисперсії; 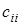 — діагональний елемент оберненої матриці С.
— діагональний елемент оберненої матриці С.
Критичні значення 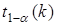 , де
, де 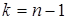 наведено в додатку 5. Ефект впливу і-го фактора визнається істотним, якщо
наведено в додатку 5. Ефект впливу і-го фактора визнається істотним, якщо 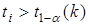 . Так, при
. Так, при 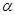 = 0,05 і
= 0,05 і 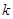 = 20 коефіцієнт в 2,15 раза перевищує стандартну похибку
= 20 коефіцієнт в 2,15 раза перевищує стандартну похибку  , що свідчить про його значущість (істотність).
, що свідчить про його значущість (істотність).
Довірчі межі ефекту впливу визначаються за правилами вибіркового методу 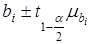 , де
, де 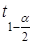 — значення двостороннього t-критерію.
— значення двостороннього t-критерію.
Рівняння регресії має такий вигляд:
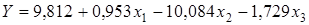 .
.
Із збільшенням цукристості буряка на 1%, за умови незмінності інших факторів, вихід цукру з 1 т сировини зростає в середньому на 0,953%; щодо порушень технології зберігання та переробки сировини, то вони мають негативний вплив, особливо порушення технології зберігання. Включені в модель фактори пояснюють 84,5% варіації виходу цукру з 1 т сировини; ефекти впливу усіх факторів істотні.